Anonimleştirme için PCA
Python ile Veri Gizliliği ve Anonimleştirme

Rebeca Gonzalez
Data engineer
Temel bileşen analizi (PCA)
$$ $$ Büyük veri kümelerinin boyutunu azaltmak için sık kullanılan bir boyut indirgeme yöntemidir.
PCA ile veri maskeleme
PCA, özgün özelliklerin doğrusal dönüşümlerinden yeni "temel bileşenler" üretir.
Bir bira veri kümesinde PCA yeni özellikler oluşturur. Örneğin:
$$ 2\times AlcoholicVolume - BitternessLevel$$
PCA ile veri maskeleme
Verinin yeni izdüşümleri
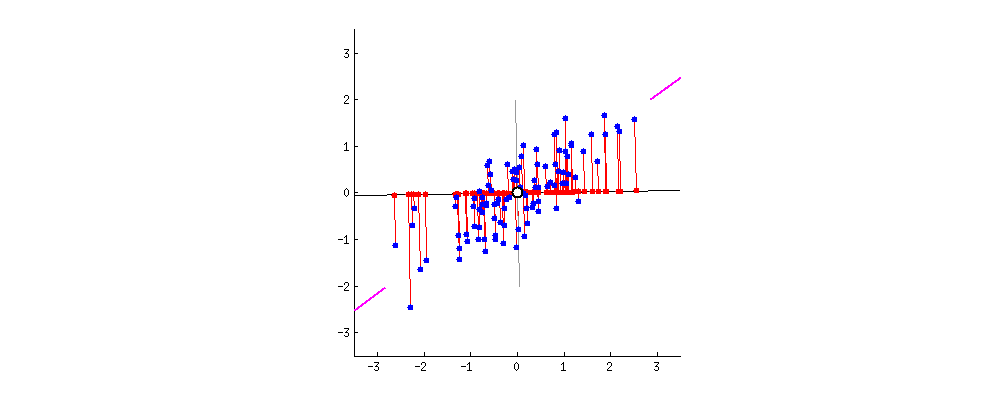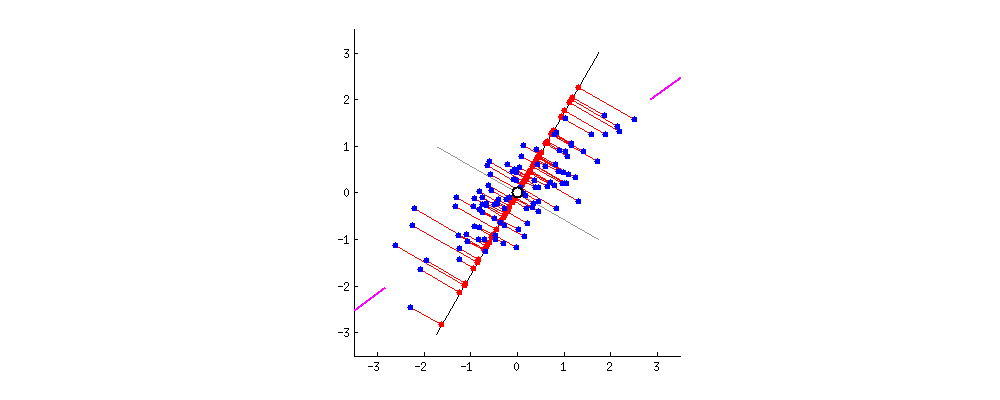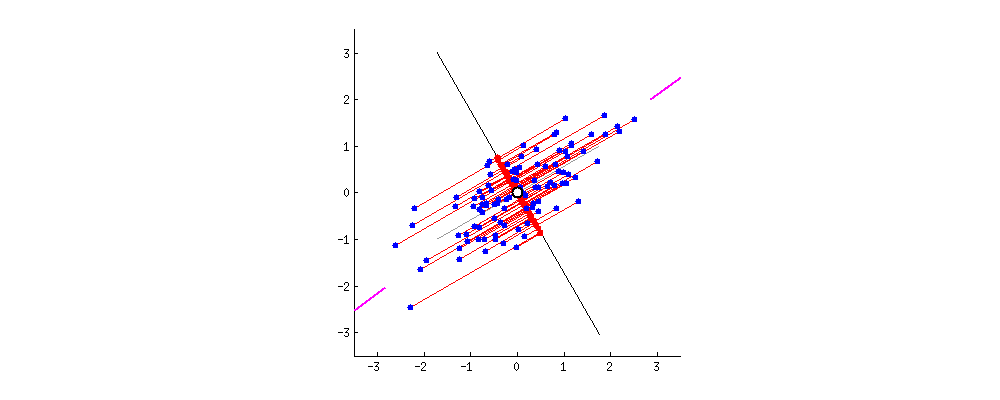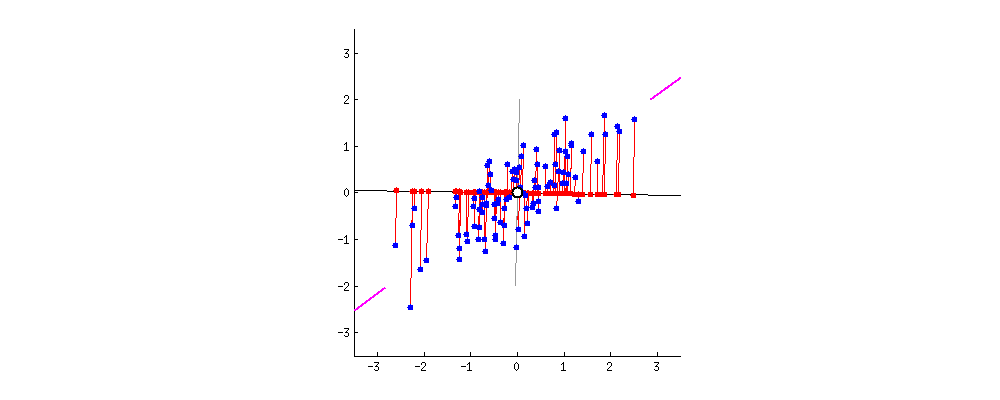
PCA ile veri maskeleme
Boyut indirgeme olmadan PCA
$$
- Yalnızca veri uzayının döndürülmesidir.
- Bu, uzaklıkların korunduğu anlamına gelir.
- Öngörü görevleri ve algoritmalar için avantajdır.
PCA ile veri maskeleme
- Bu değerler açıklamasız yayımlanırsa, algoritmalar hâlâ bunlarla eğitilip doğru tahminler yapabilir.
- Saldırganlar bu maskelenmiş değerleri nasıl yorumlayacağını bilemez.
PCA ile veri maskeleme
# Veri kümesini keşfedin
heart_df.head()
age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target
0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1
1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 1
2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 1
3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1
4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1
PCA ve Scikit-learn ile veri maskeleme
# Hedef sütunu olmadan veriyi alın x_data = df.drop(['target'], axis = 1)# Hedef sütunu değer dizisi y = df.target.values
PCA ve Scikit-learn ile veri maskeleme
# Scikit-learn'den PCA'yı içe aktarın from sklearn.decomposition import PCA# Bileşen sayısını sütun sayısına eşit olacak şekilde PCA'yı başlatın pca = PCA(n_components=len(x_data.columns))# Veriye PCA uygulayın x_data_pca = pca.fit_transform(x_data)
PCA ve Scikit-learn ile veri maskeleme
# Veriyi görüntüleyin
x_data_pca
array([[-1.22673448e+01, 2.87383781e+00, 1.49698788e+01, ...,
7.31102828e-01, -2.90393586e-01, 5.12575925e-01],
[ 2.69013712e+00, -3.98713736e+01, 8.77882303e-01, ...,
4.04206943e-01, -4.25920179e-01, -1.48124511e-01],
[-4.29502141e+01, -2.36368199e+01, 1.75944589e+00, ...,
-9.15397287e-01, 2.17828257e-01, 7.97593843e-02],
...,
PCA ve Scikit-learn ile veri maskeleme
# PCA ile dönüştürülen veriden bir DataFrame oluşturun df_x_data_pca = pd.DataFrame(x_data_pca)# Veri kümesinin şeklini inceleyin df_x_data_pca.shape
(1213, 13)
PCA maskelemesinden sonra veri yararlılığı
- Lojistik regresyon ile sınıflandırma yapın ve özgün veri ile dönüştürülmüş veri arasında doğruluk kaybını karşılaştırın.
$$
- Lojistik regresyon bir sınıflandırma algoritmasıdır; bağımsız değişkenlere göre ikili bir sonucu tahmin eder.
PCA maskelemesinden sonra veri yararlılığı
Lojistik regresyon ile sınıflandırma yapın ve doğruluk kaybını kontrol edin.
# Dönüşmüş veri kümesini eğitim/test olarak ayırın x_train, x_test, y_train, y_test = train_test_split(x_data_pca, y, test_size=0.2)# Modeli oluşturun lr = LogisticRegression(max_iter=200)# Modeli eğitin lr.fit(x_train,y_train)# Modeli çalıştırın, tahmin yapın ve doğruluk skorunu alın acc = lr.score(x_test, y_test) * 100 print("Test Accuracy is ", acc)
Test Accuracy is 85.24590163934425
PCA maskelemesinden önce veri yararlılığı
Lojistik regresyon ile sınıflandırma yapın ve özgün veri ile skoru görün
# Veri kümesini eğitim/test olarak ayırın
x_train, x_test, y_train, y_test = train_test_split(x_data.to_numpy(),y,test_size = 0.2)
# Modeli oluşturun
lr = LogisticRegression(max_iter=200)
# Modeli eğitin
lr.fit(x_train,y_train)
# Modeli çalıştırın, tahmin yapın ve doğruluk skorunu alın
acc = lr.score(x_test,y_test) * 100
print("Test Accuracy is ", acc)
Test Accuracy is 85.24590163934425
Ayo berlatih!
Python ile Veri Gizliliği ve Anonimleştirme

