Sürekli verileri anonimleştirme
Python ile Veri Gizliliği ve Anonimleştirme

Rebeca Gonzalez
Instructor
Sürekli değişkenler
- age
- height
- weight
- temperature
- date and time
Sürekli değişkenler
# Veri setini gör
hr.head()
Age BusinessTravel Department EducationField EmployeeNumber
0 41 Travel_Rarely Sales Life Sciences 1
1 49 Travel_Frequently Research & Development Life Sciences 2
2 37 Travel_Rarely Research & Development Other 4
3 33 Travel_Frequently Research & Development Life Sciences 5
4 27 Travel_Rarely Research & Development Medical 7
Sürekli dağılımlar
Verimiz için en uygun sürekli dağılımı kullanın.
- Histogram oluşturun
- Sürekli fonksiyonları deneyin, histograma uyarlayın.
- Histogramla farkı en küçük olan fonksiyonu seçin.
Sürekli dağılım
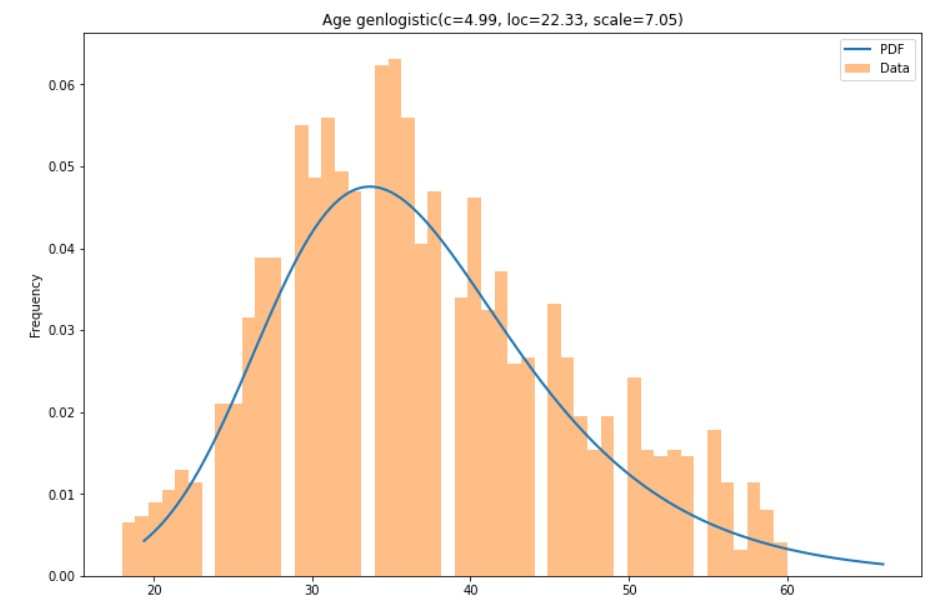
Bir dağılım uygulama
import scipy.stats# Genlogistic dağılımını Age sürekli değişkenine uydur params = scipy.stats.genlogistic.fit(hr['Age'])# Sürekli fonksiyonların parametrelerini gör print(params)
(4.9899067653418285, 22.32808853181744, 7.046590524738551)
Sürekli dağıtımdan örnekleme
# Genlogistic dağılımdan örnekleme df['Age'] = scipy.stats.genlogistic.rvs(size=len(df.index), *params)# Ortaya çıkan veri setini gör df['Age'].head()
Age BusinessTravel Department EducationField EmployeeNumber
0 40.767259 Travel_Rarely Sales Life Sciences 1
1 45.730504 Travel_Frequently Research & Development Life Sciences 2
2 41.910050 Travel_Rarely Research & Development Other 4
3 35.275320 Travel_Frequently Research & Development Life Sciences 5
4 40.198134 Travel_Rarely Research & Development Medical 7
Sürekli dağıtımdan örnekleme
# Ayrık değerler elde etmek için yuvarla
df['Age'] = df['Age'].round()
Age BusinessTravel Department EducationField EmployeeNumber
0 41 Travel_Rarely Sales Life Sciences 1
1 46 Travel_Frequently Research & Development Life Sciences 2
2 42 Travel_Rarely Research & Development Other 4
3 35 Travel_Frequently Research & Development Life Sciences 5
4 40 Travel_Rarely Research & Development Medical 7
Haydi pratik yapalım!
Python ile Veri Gizliliği ve Anonimleştirme

