K-anonimlik'e giriş
Python ile Veri Gizliliği ve Anonimleştirme

Rebeca Gonzalez
Data engineer
K-anonimlik neden önemli?

Neden önemli?
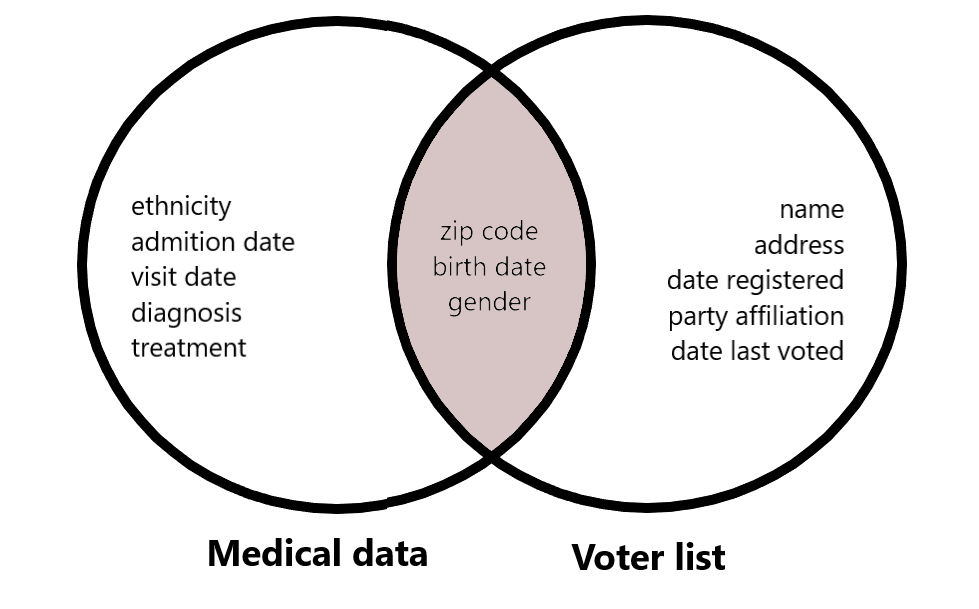
k-anonimlik tanımı

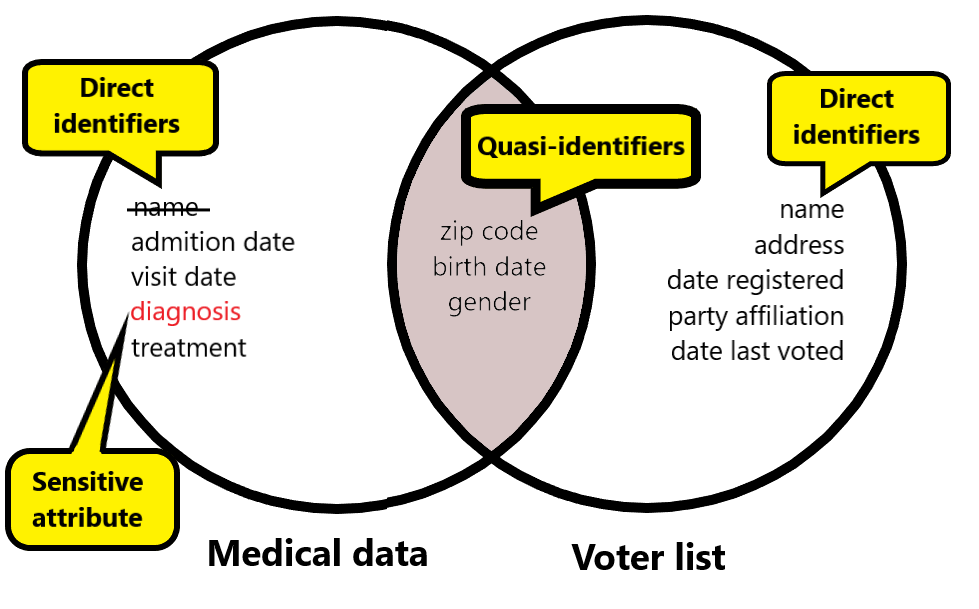
K-anonimlik: Terimler
Python ile Veri Gizliliği ve Anonimleştirme
Rebeca Gonzalez
Data engineer

