Hoe goed is je model?
Supervised Learning met scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Confusion matrix voor classificatieprestaties
- Confusion matrix
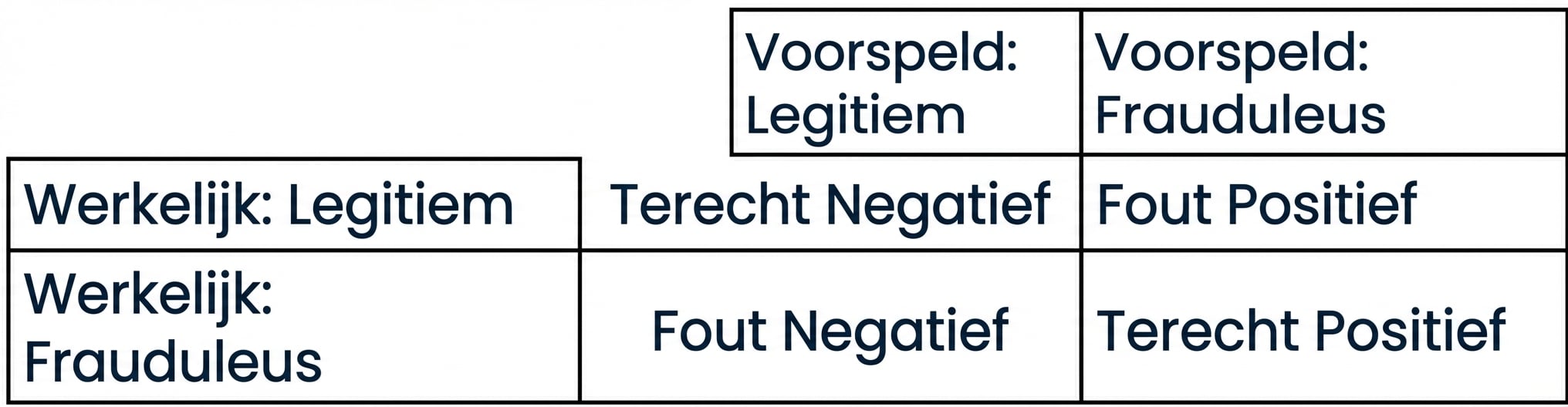
Classificatieprestaties beoordelen
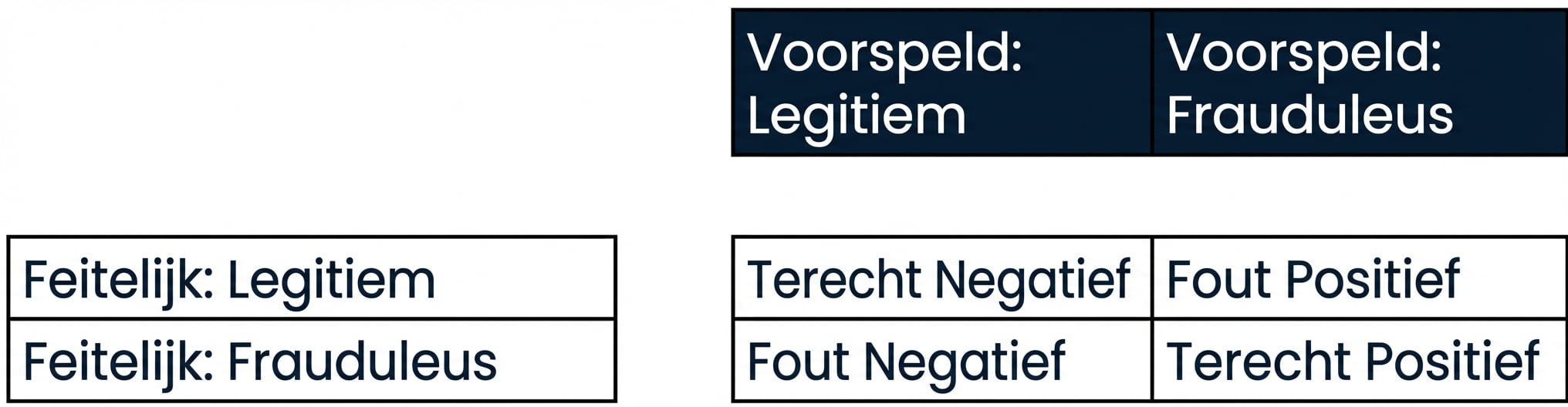
Classificatieprestaties beoordelen

Classificatieprestaties beoordelen
Classificatieprestaties beoordelen
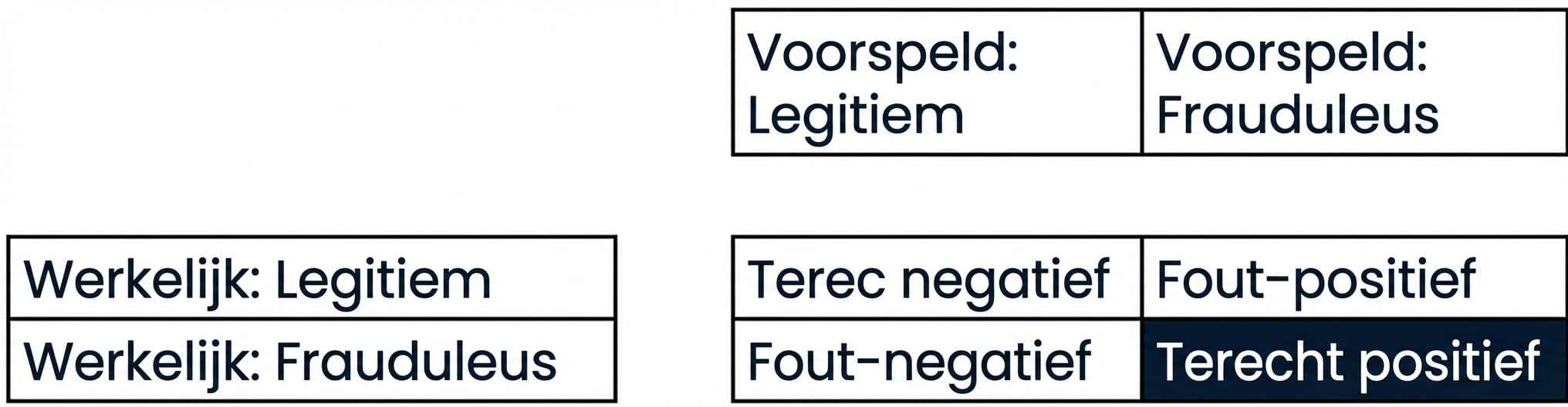
Classificatieprestaties beoordelen
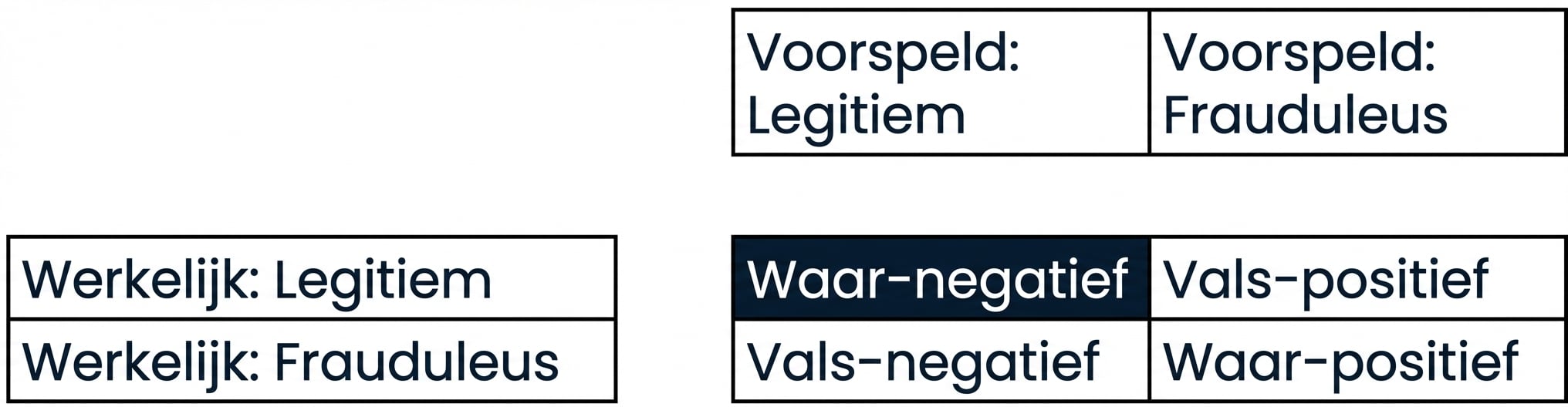
Classificatieprestaties beoordelen

Classificatieprestaties beoordelen
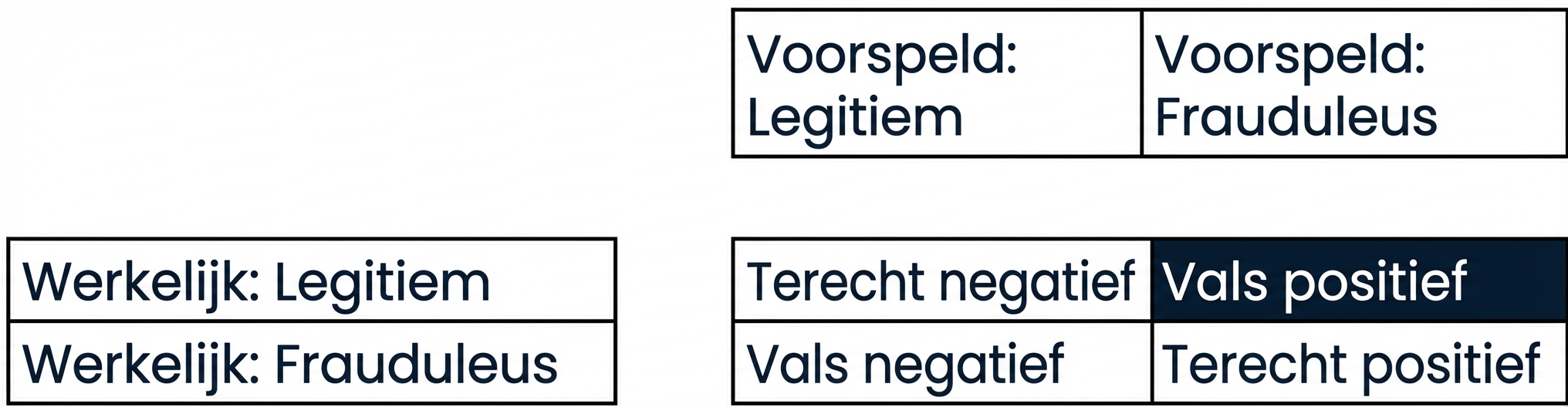
Classificatieprestaties beoordelen
- Accuratesse:
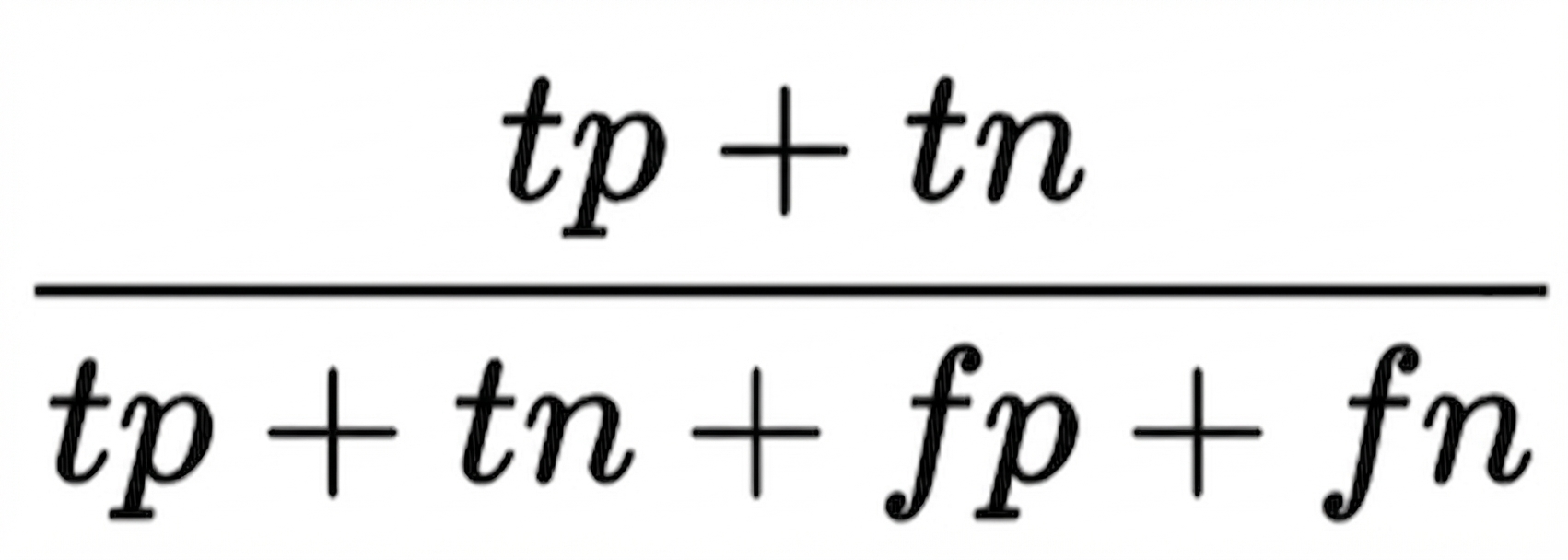
Precisie
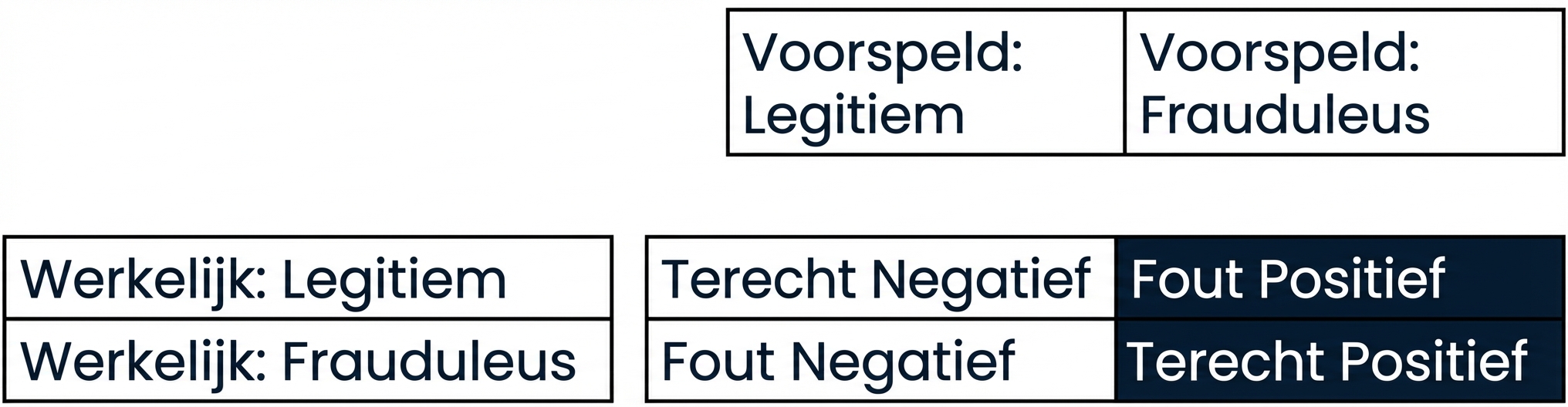
- Precisie

- Hoge precisie = lagere false-positive rate
- Hoge precisie: Weinig legitieme transacties voorspeld als frauduleus
Recall
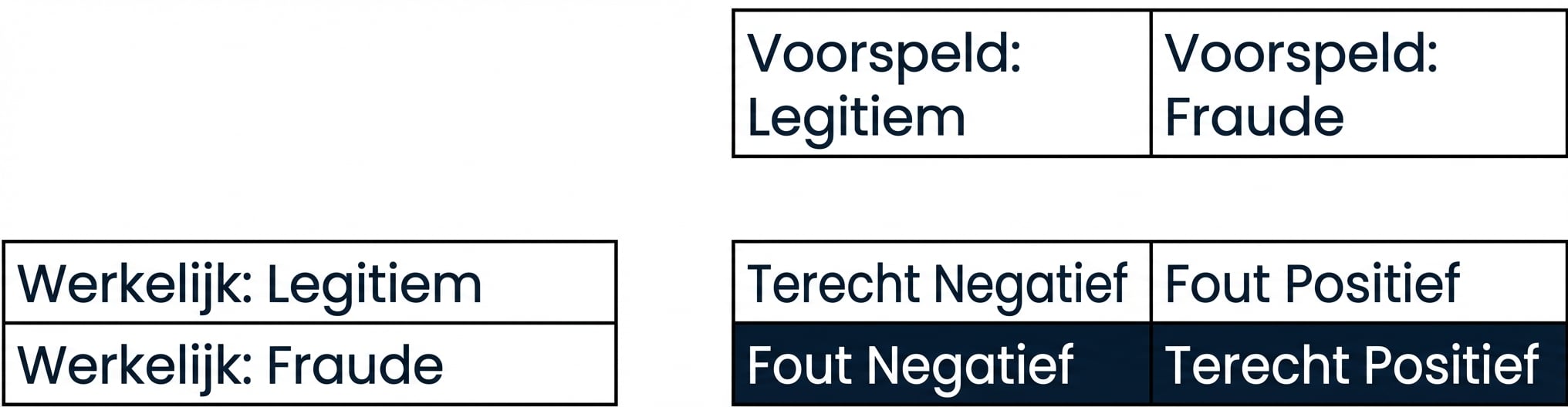
- Recall

- Hoge recall = lagere false-negative rate
- Hoge recall: Meeste frauduleuze transacties correct voorspeld

