Meerdere modellen evalueren
Supervised Learning met scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Andere modellen voor andere problemen
Een paar leidende principes
- Omvang van de dataset
- Minder features = eenvoudiger model, snellere training
- Sommige modellen hebben veel data nodig voor goede prestaties
- Interpreteerbaarheid
- Sommige modellen zijn makkelijker uit te leggen; belangrijk voor stakeholders
- Lineaire regressie is goed te interpreteren: coëfficiënten zijn begrijpelijk
- Flexibiliteit
- Kan nauwkeurigheid verhogen door minder aannames over data
- KNN is flexibeler; veronderstelt geen lineaire relaties
Het draait om de metrics
Regressiemodel-prestaties:
- RMSE
- R-kwadraat
Classificatiemodel-prestaties:
- Accuratesse
- Confusion matrix
- Precisie, recall, F1-score
- ROC AUC
Train meerdere modellen en evalueer out-of-the-box
Een opmerking over schalen
- Modellen die beïnvloed worden door schalen:
- KNN
- Lineaire regressie (plus Ridge, Lasso)
- Logistische regressie
- Kunstmatig neuraal netwerk
- Schaal je data vóór het evalueren van modellen
Classificatiemodellen evalueren
import matplotlib.pyplot as plt from sklearn.preprocessing import StandardScaler from sklearn.model_selection import cross_val_score, KFold, train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifierX = music.drop("genre", axis=1).values y = music["genre"].values X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)
Classificatiemodellen evalueren
models = {"Logistic Regression": LogisticRegression(), "KNN": KNeighborsClassifier(), "Decision Tree": DecisionTreeClassifier()} results = []for model in models.values():kf = KFold(n_splits=6, random_state=42, shuffle=True)cv_results = cross_val_score(model, X_train_scaled, y_train, cv=kf)results.append(cv_results)plt.boxplot(results, labels=models.keys()) plt.show()
Resultaten visualiseren
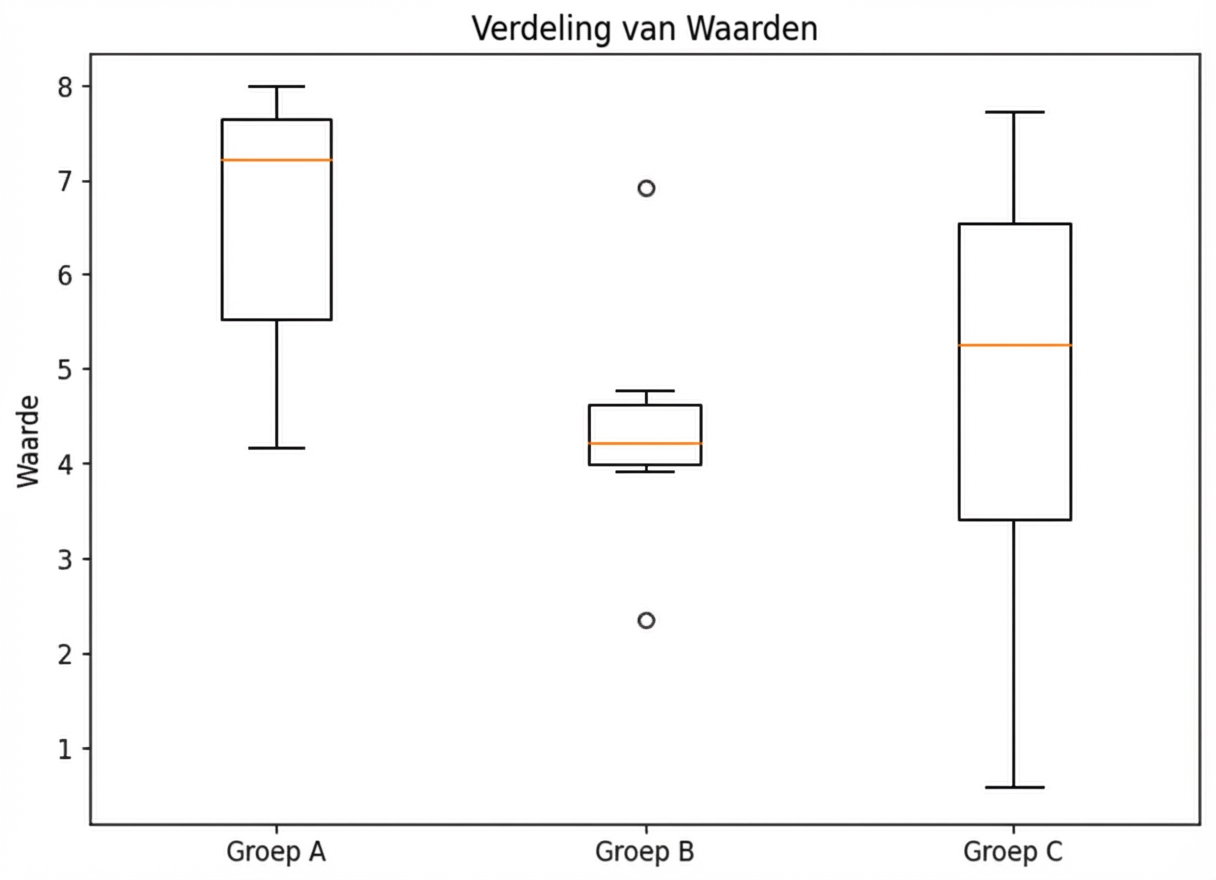
Prestaties op testset
for name, model in models.items():model.fit(X_train_scaled, y_train)test_score = model.score(X_test_scaled, y_test)print("{} Test Set Accuracy: {}".format(name, test_score))
Logistic Regression Test Set Accuracy: 0.844
KNN Test Set Accuracy: 0.82
Decision Tree Test Set Accuracy: 0.832
Laten we oefenen!
Supervised Learning met scikit-learn

