Modelprestatie meten
Supervised Learning met scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Modelprestatie meten
Bij classificatie is nauwkeurigheid een vaak gebruikte metriek
Nauwkeurigheid:

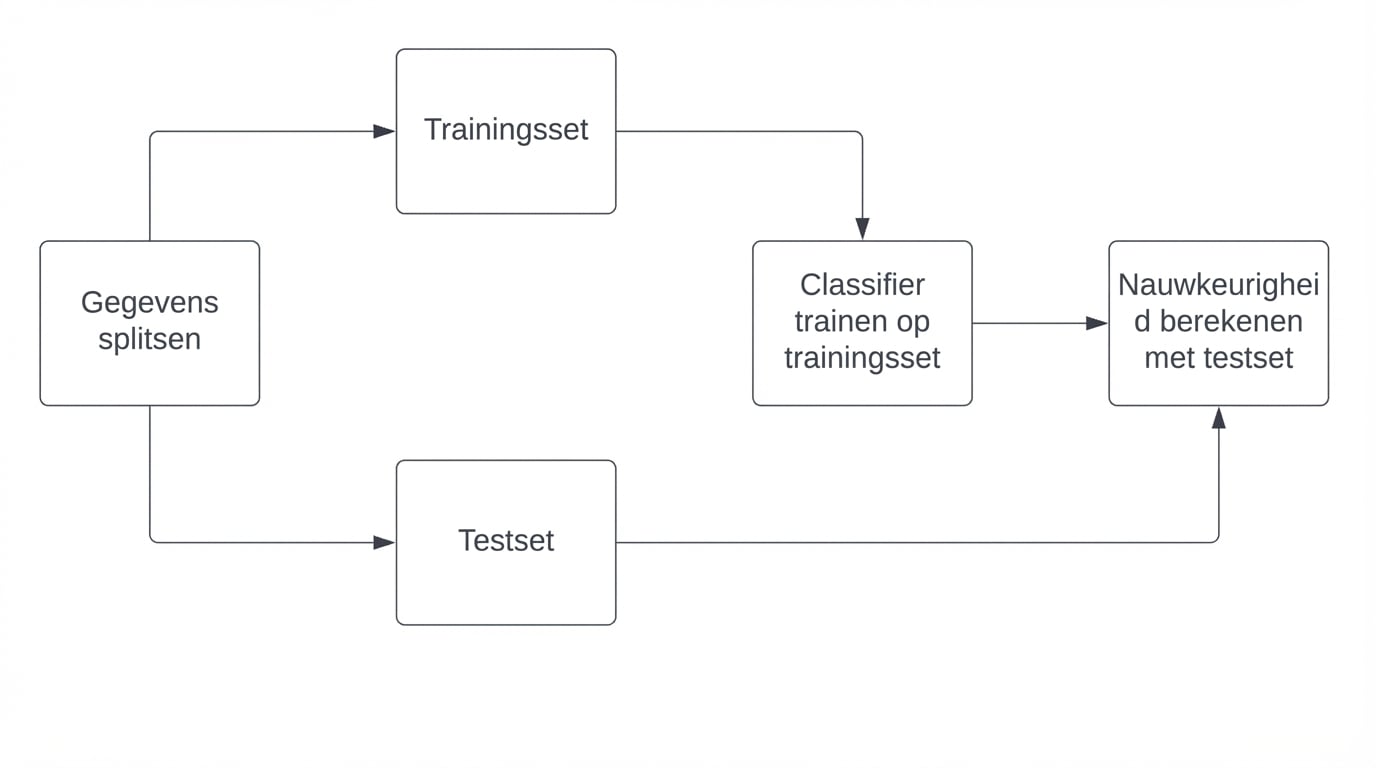
Nauwkeurigheid berekenen
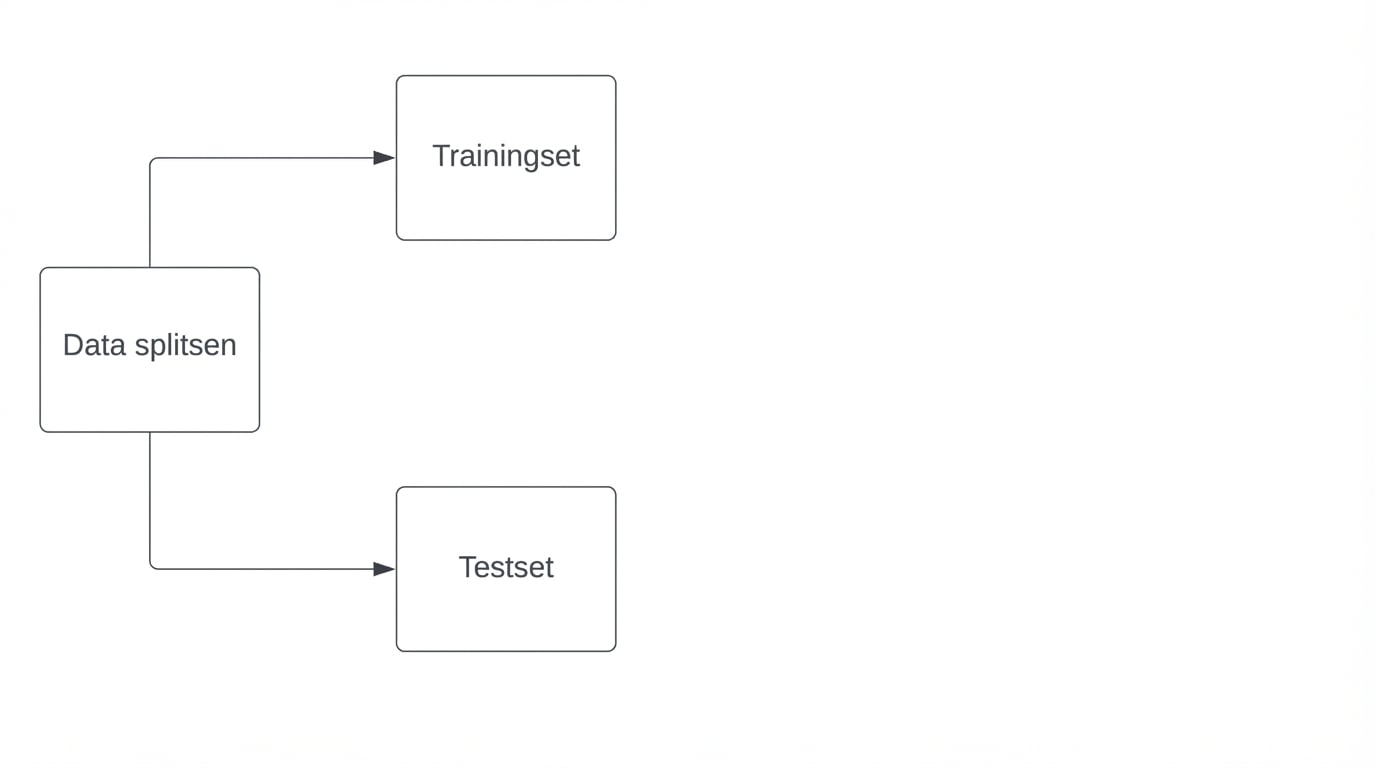
Nauwkeurigheid berekenen
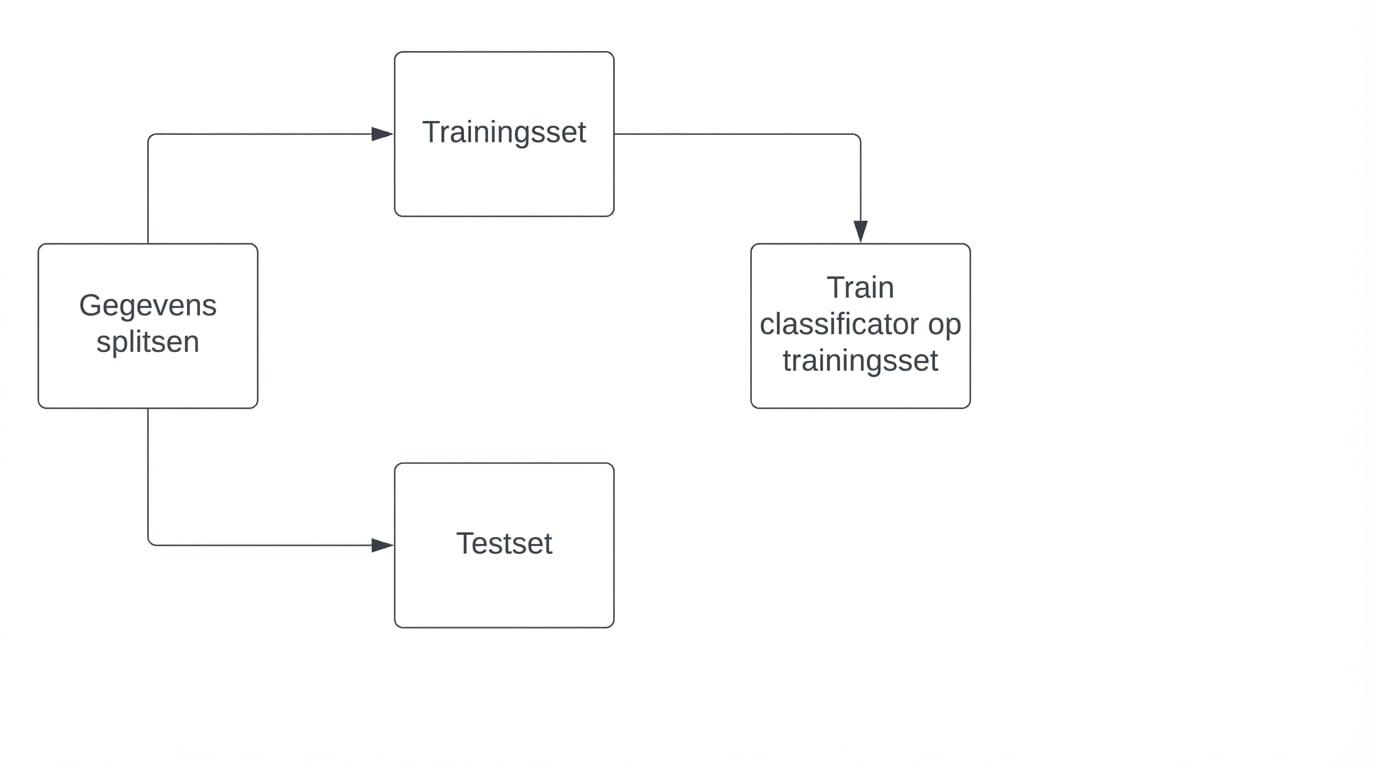
Nauwkeurigheid berekenen
Modelcomplexiteit
Grotere k = minder complex model = kan underfitting geven
Kleinere k = complexer model = kan overfitting geven
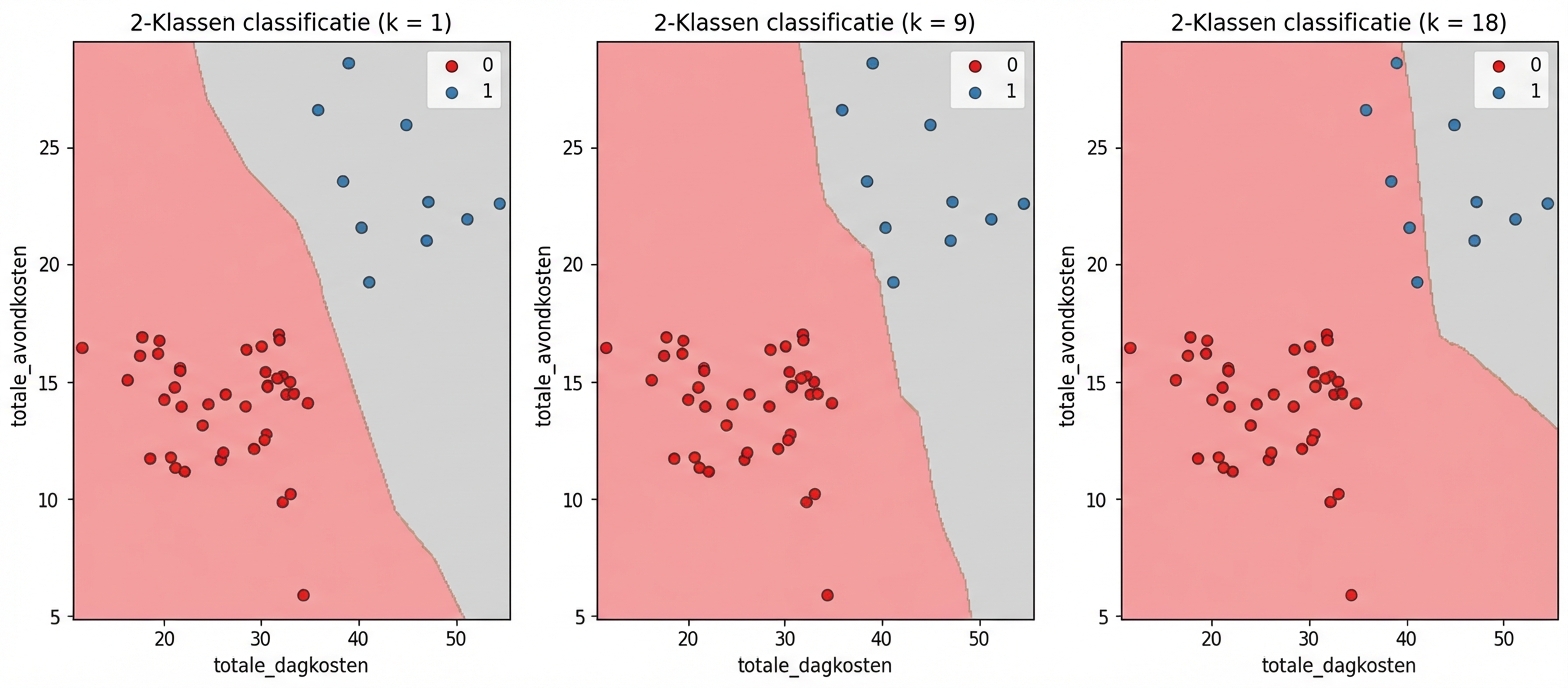
Modelcomplexiteitscurve
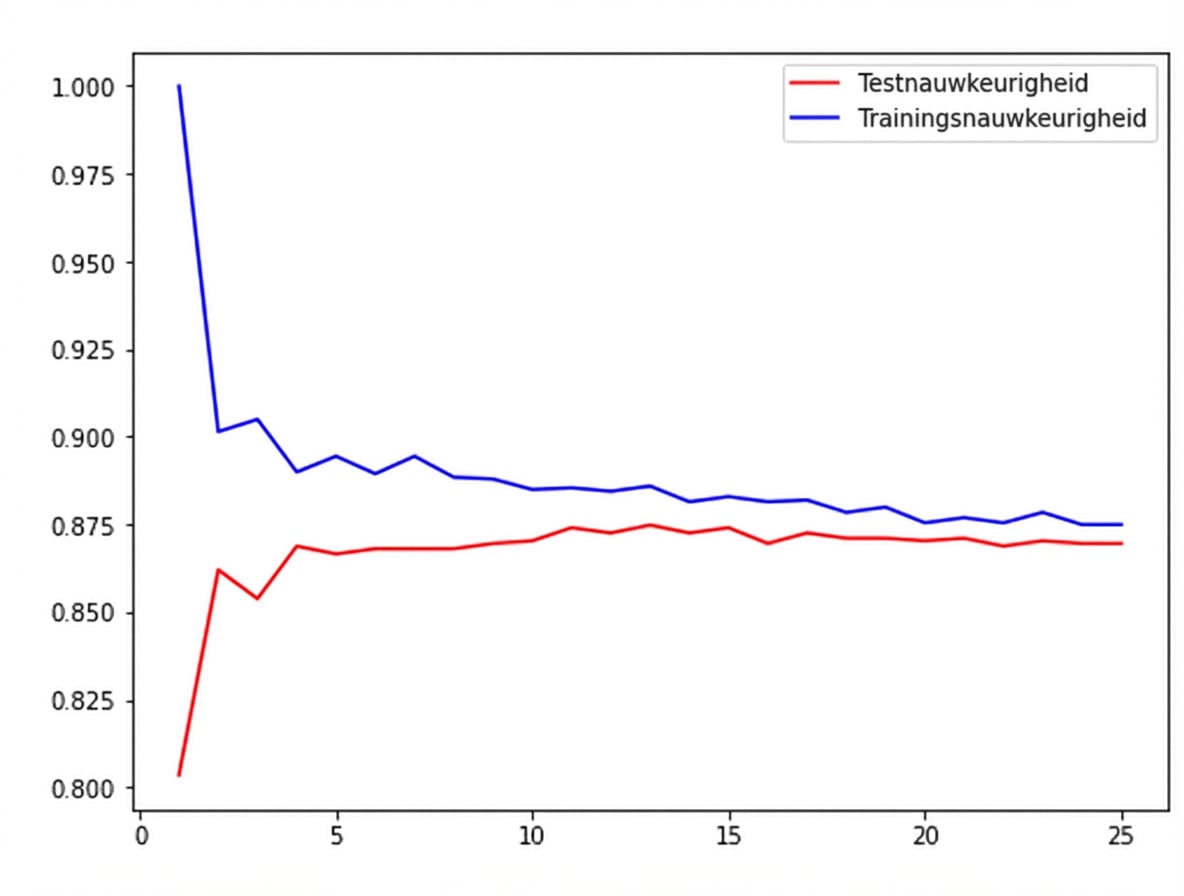
Modelcomplexiteitscurve
![]()

