Data voorbewerken
Supervised Learning met scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
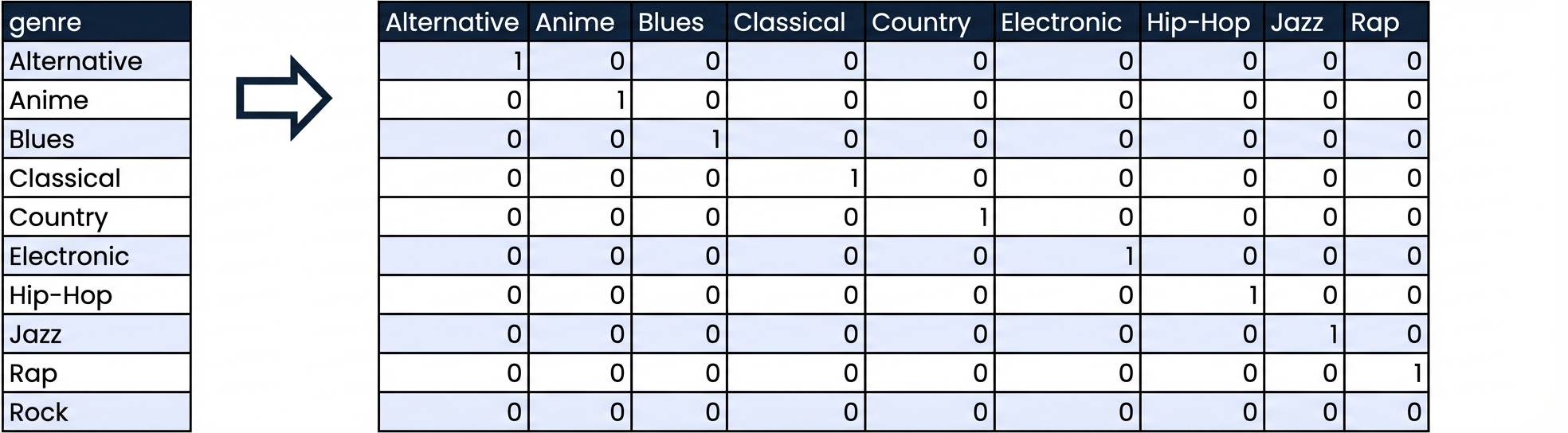
Dummyvariabelen

Dummyvariabelen
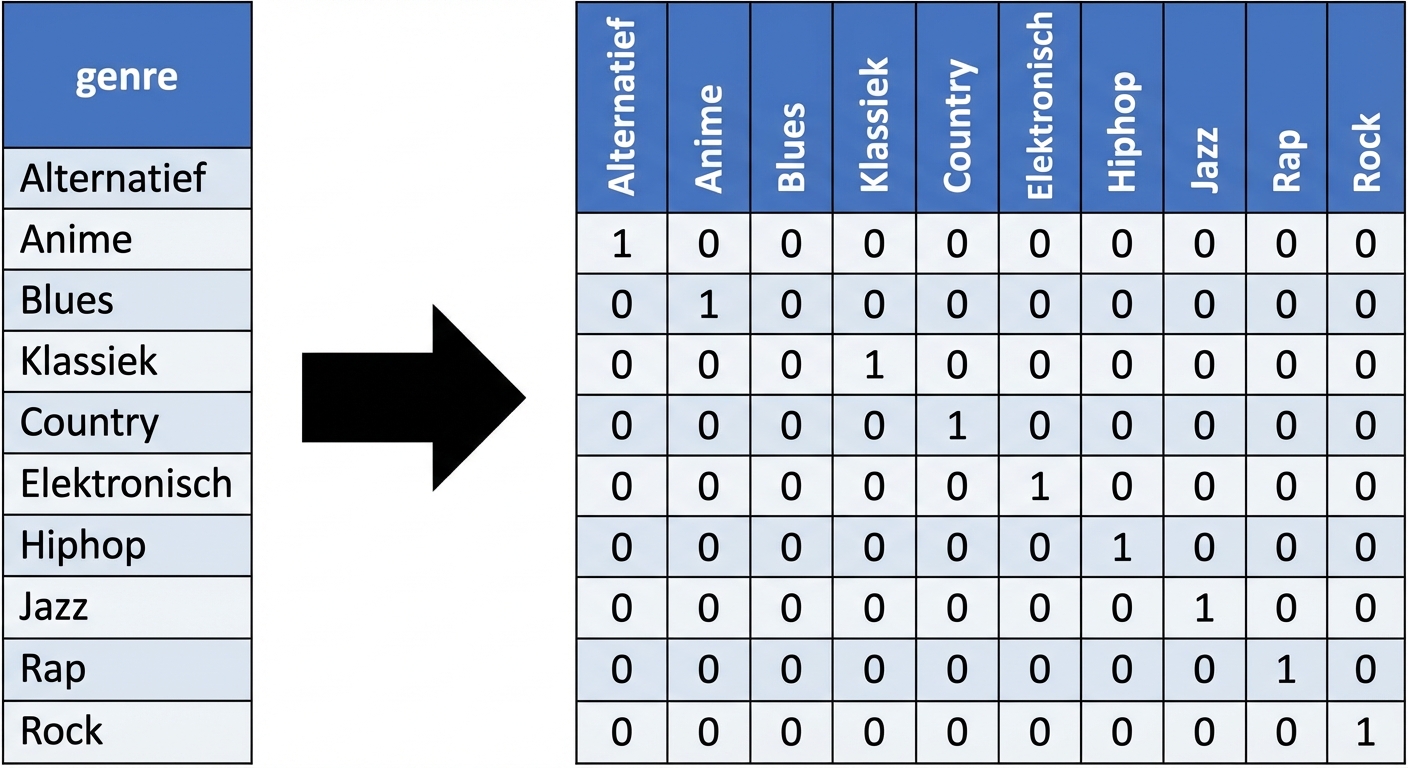
Dummyvariabelen
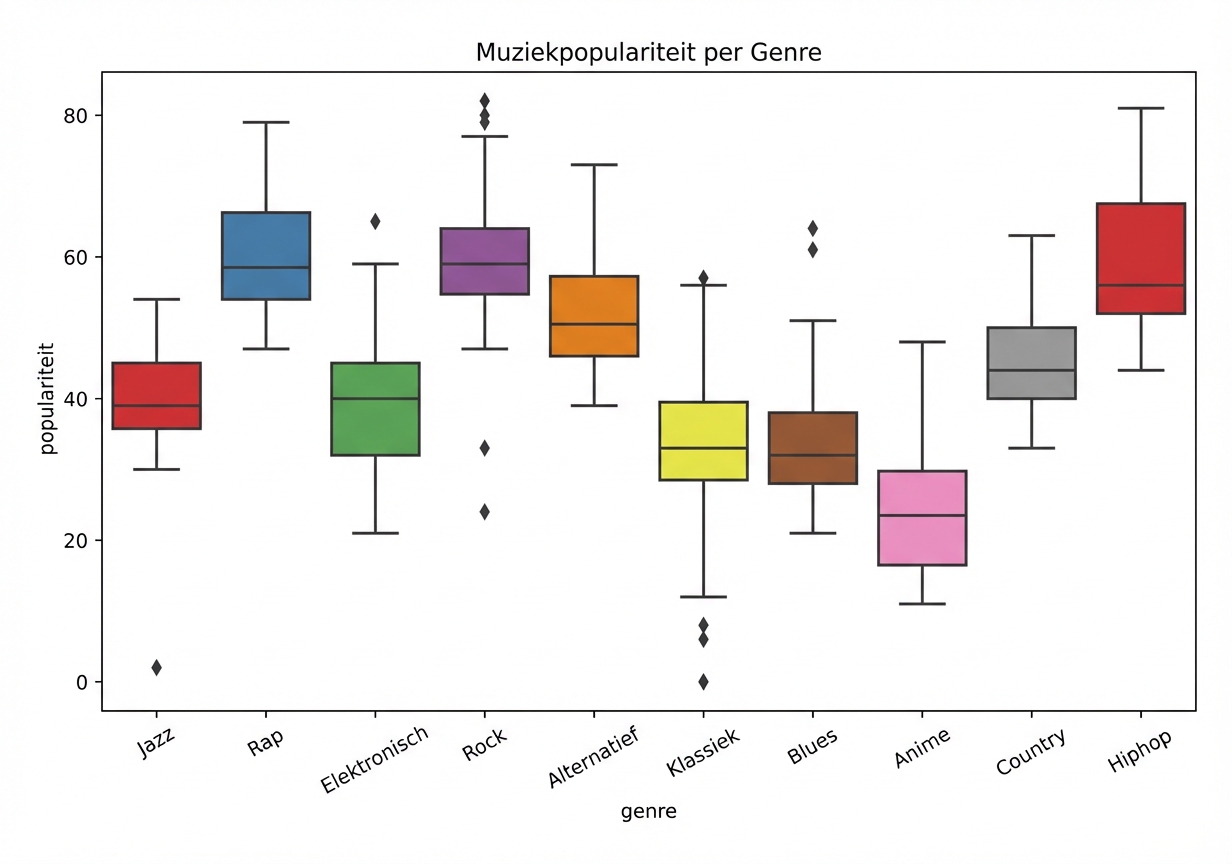
EDA met categorische feature
Supervised Learning met scikit-learn
George Boorman
Core Curriculum Manager, DataCamp

