Hyperparameterafstemming
Supervised Learning met scikit-learn

George Boorman
Core Curriculum Manager
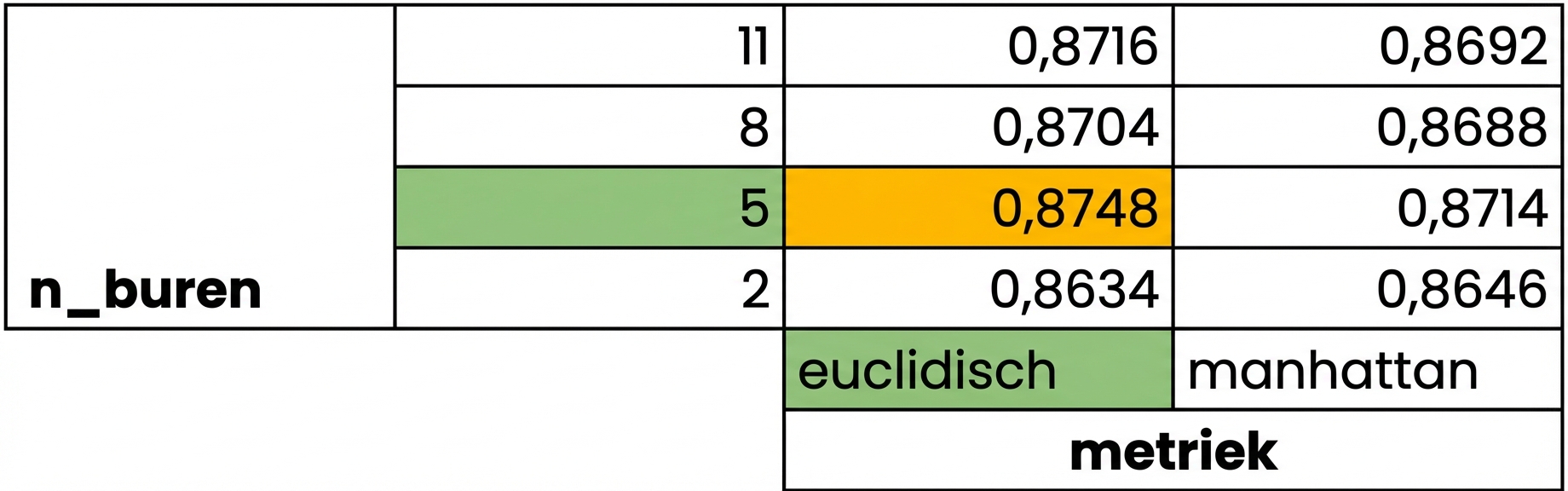
Grid search cross-validatie
Grid search cross-validatie

Grid search cross-validatie
Supervised Learning met scikit-learn
George Boorman
Core Curriculum Manager

