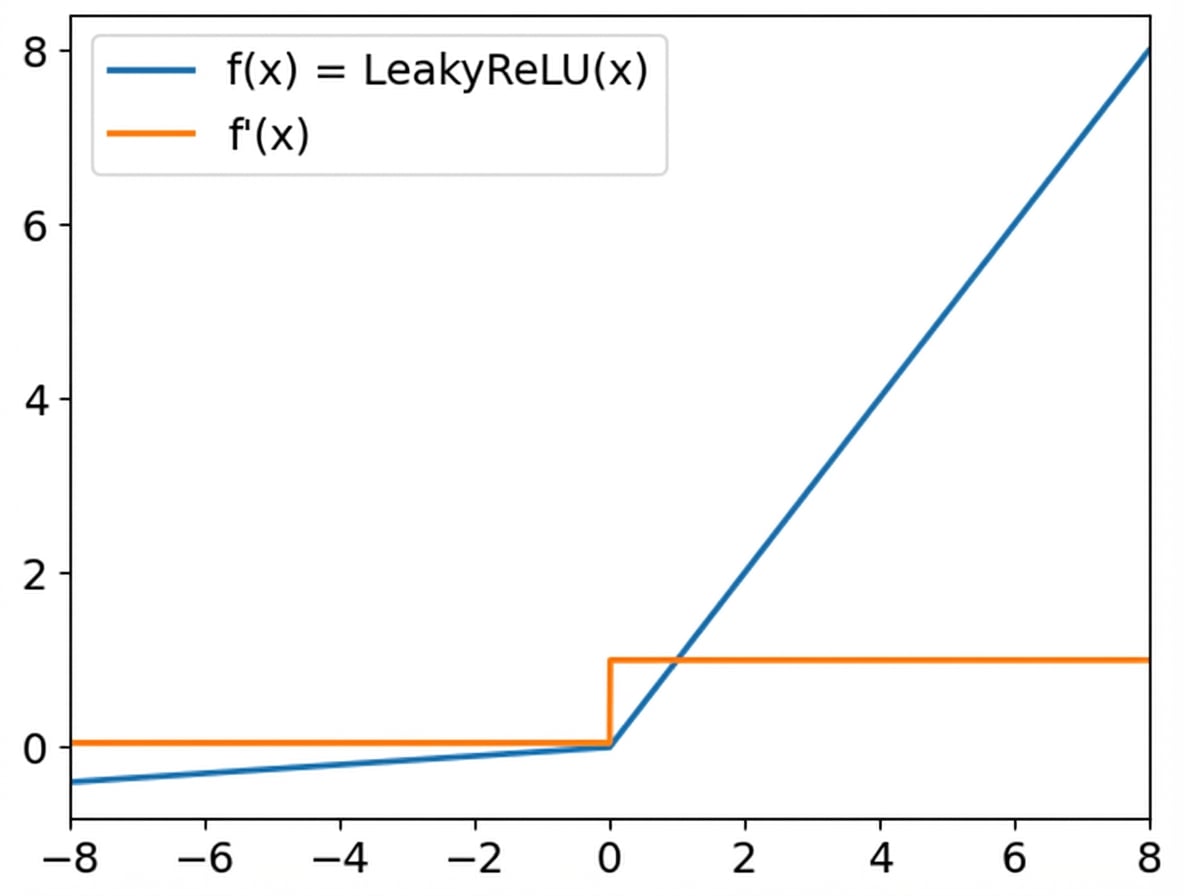
ReLU-activatiefuncties
Introductie tot Deep Learning met PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
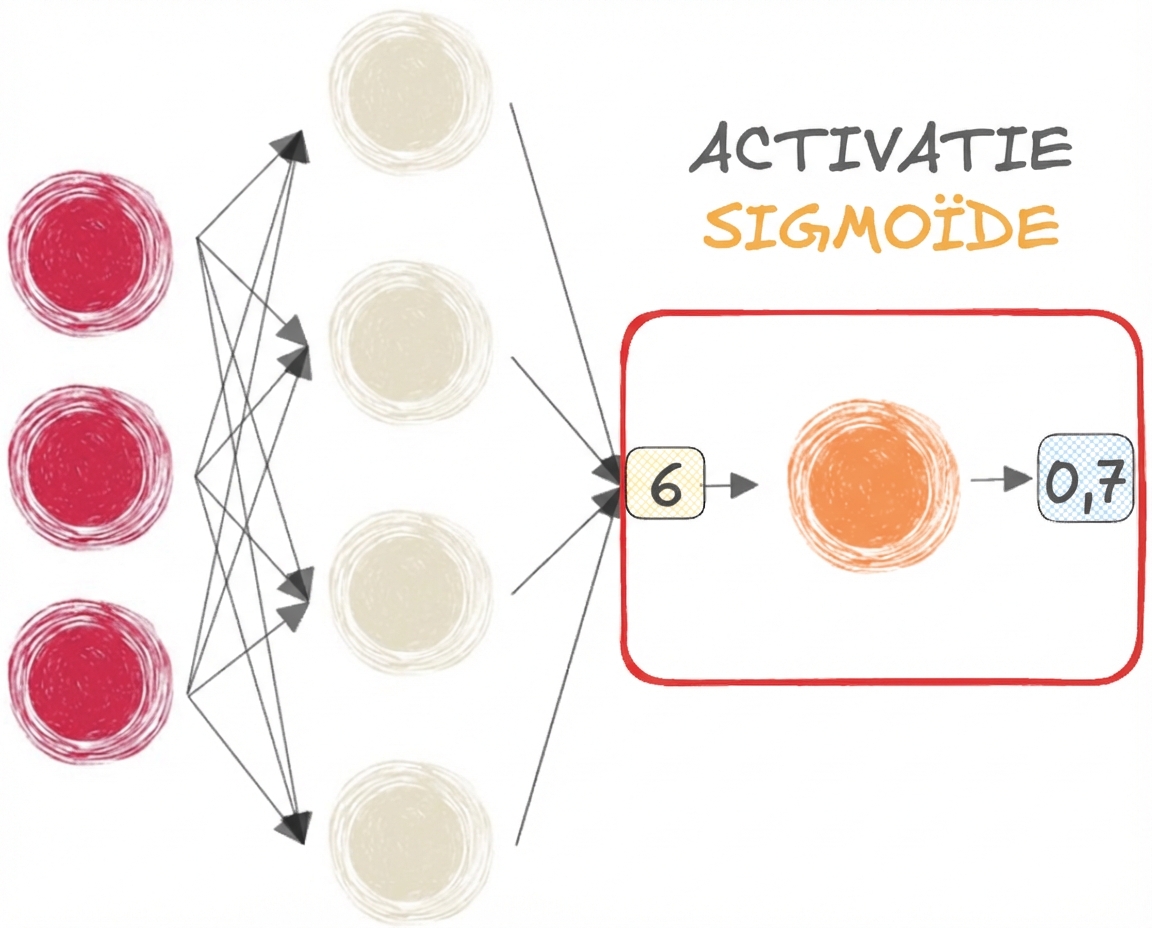
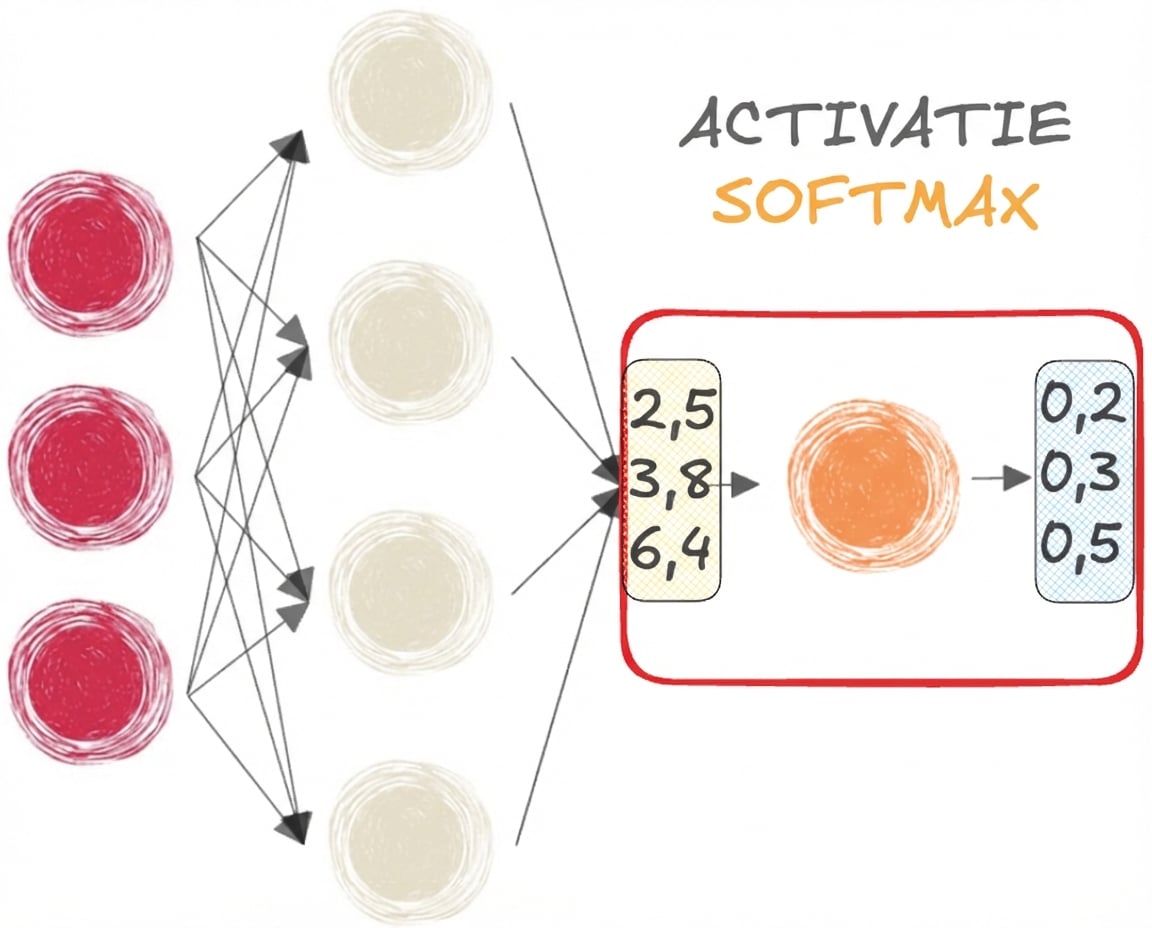
Sigmoid- en softmaxfuncties
$$
- SIGMOID voor BINAIRE classificatie
$$
- SOFTMAX voor MULTIKLASSE classificatie
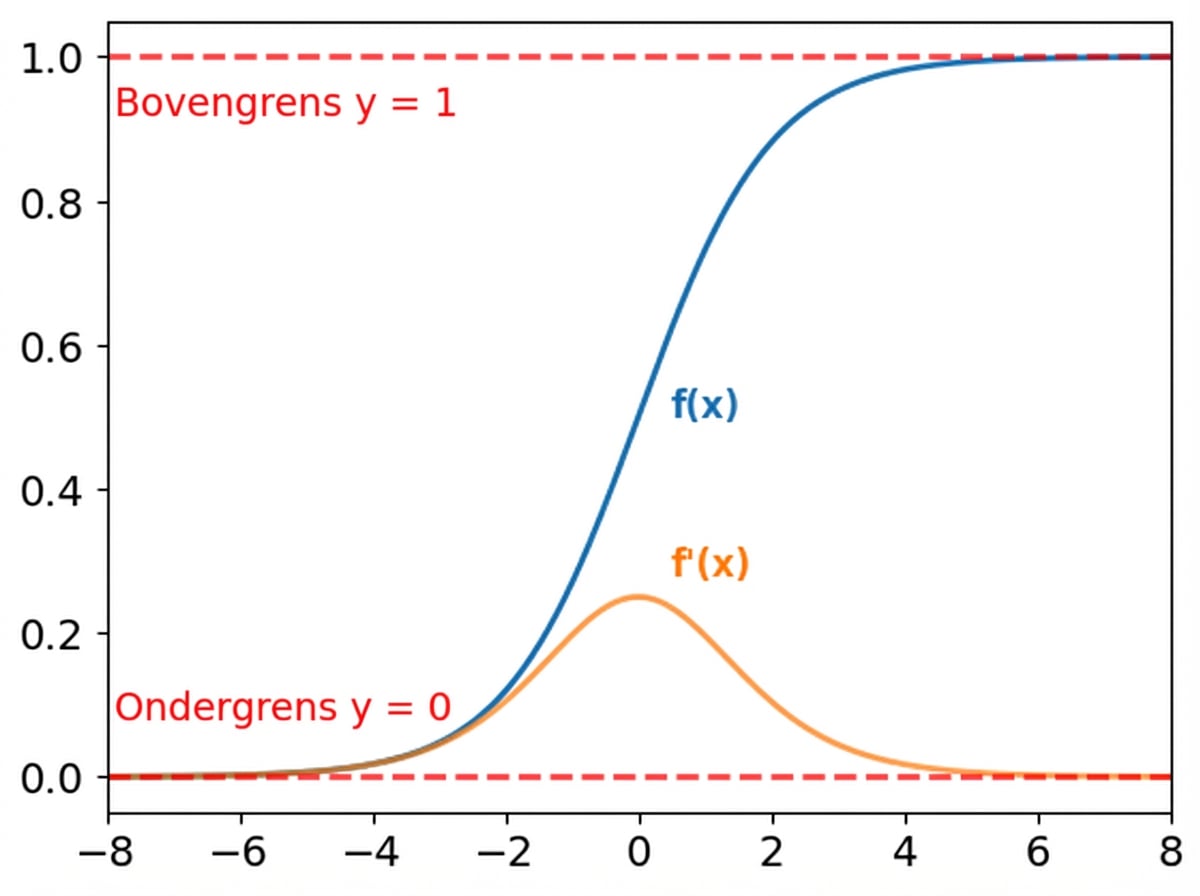
Beperkingen van de sigmoid- en softmaxfunctie
ReLU
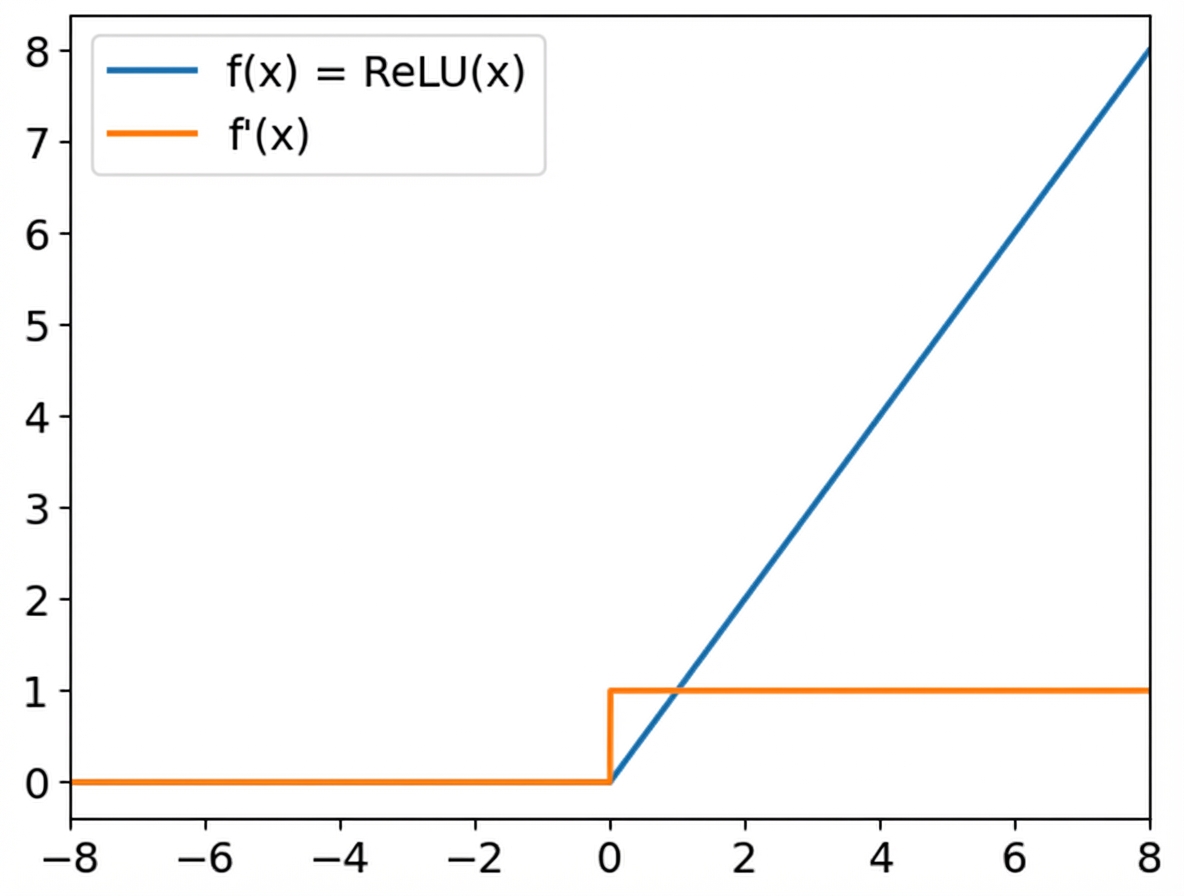
Leaky ReLU