Learning rate en momentum
Introductie tot Deep Learning met PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
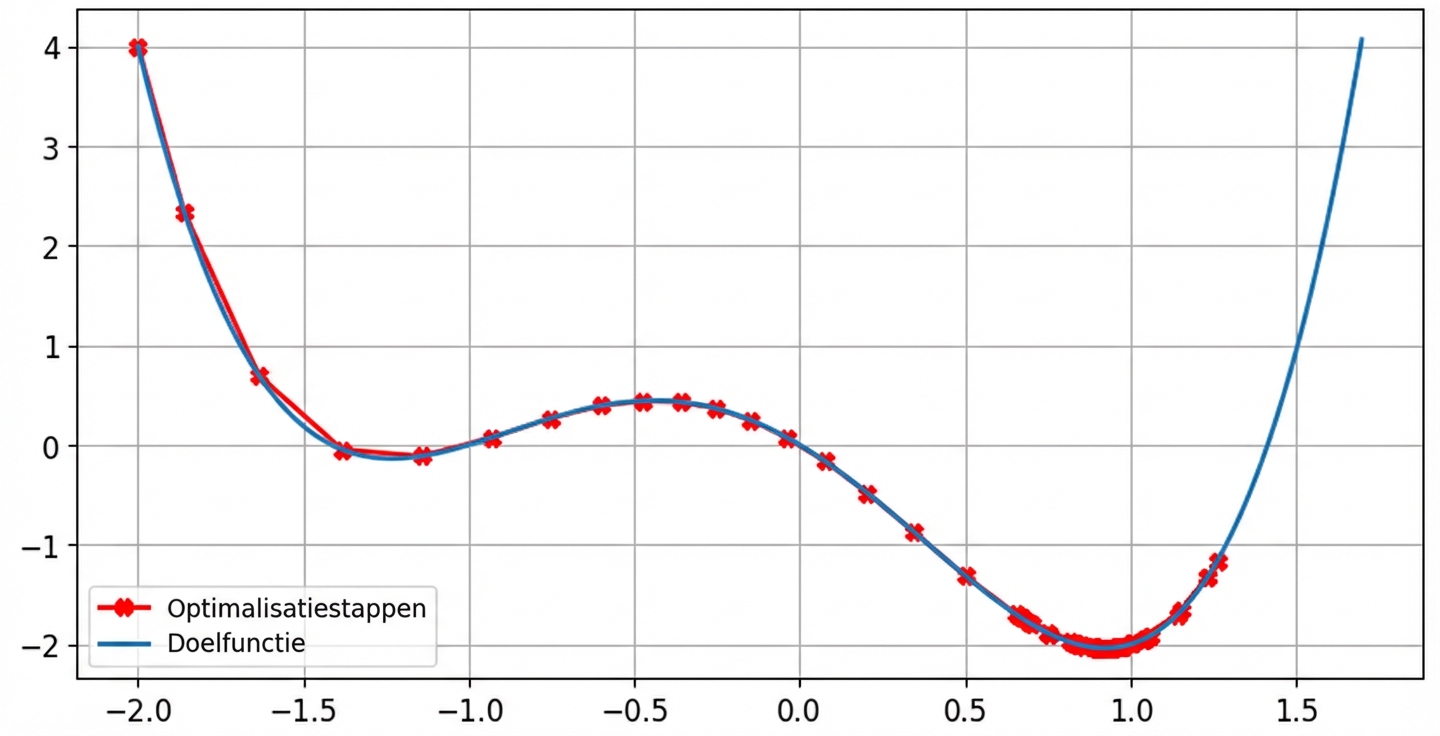
Effect van de learning rate: optimale learning rate
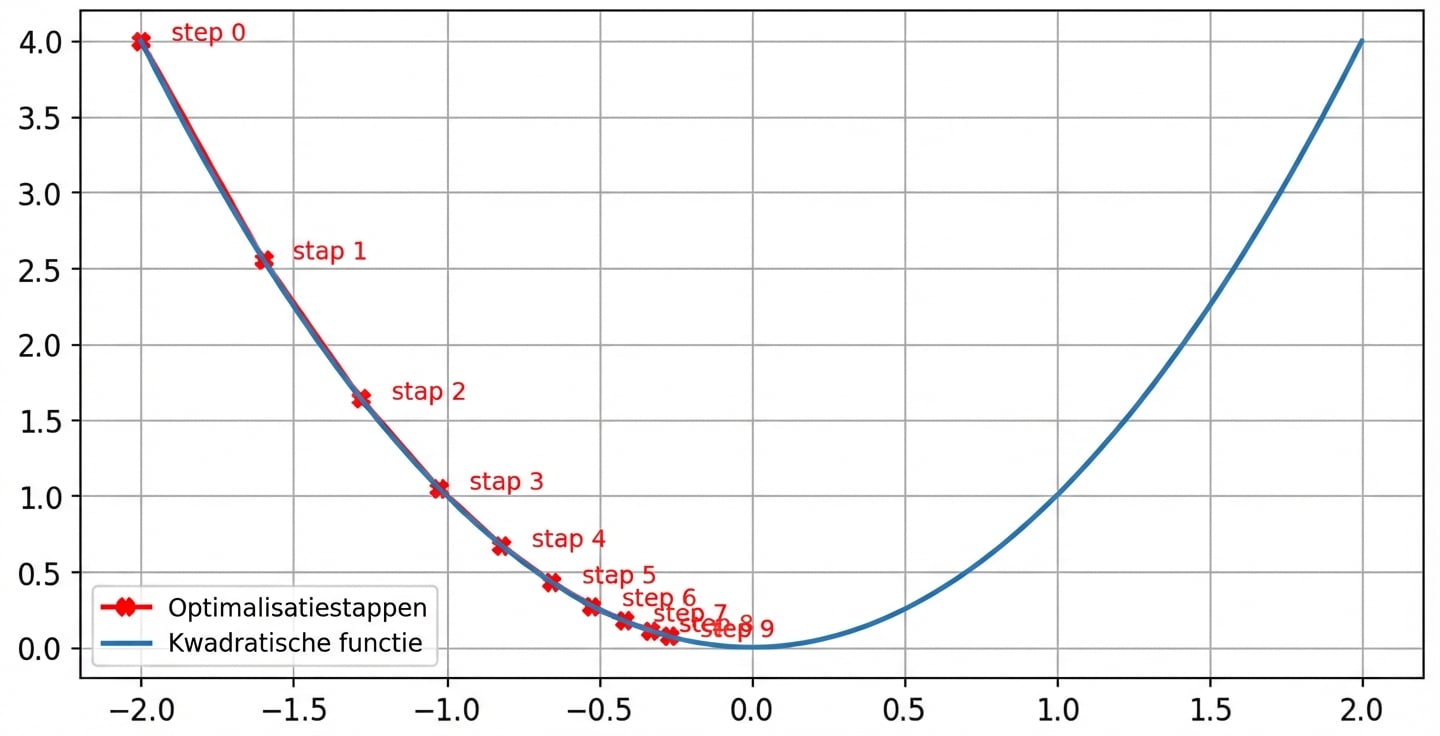
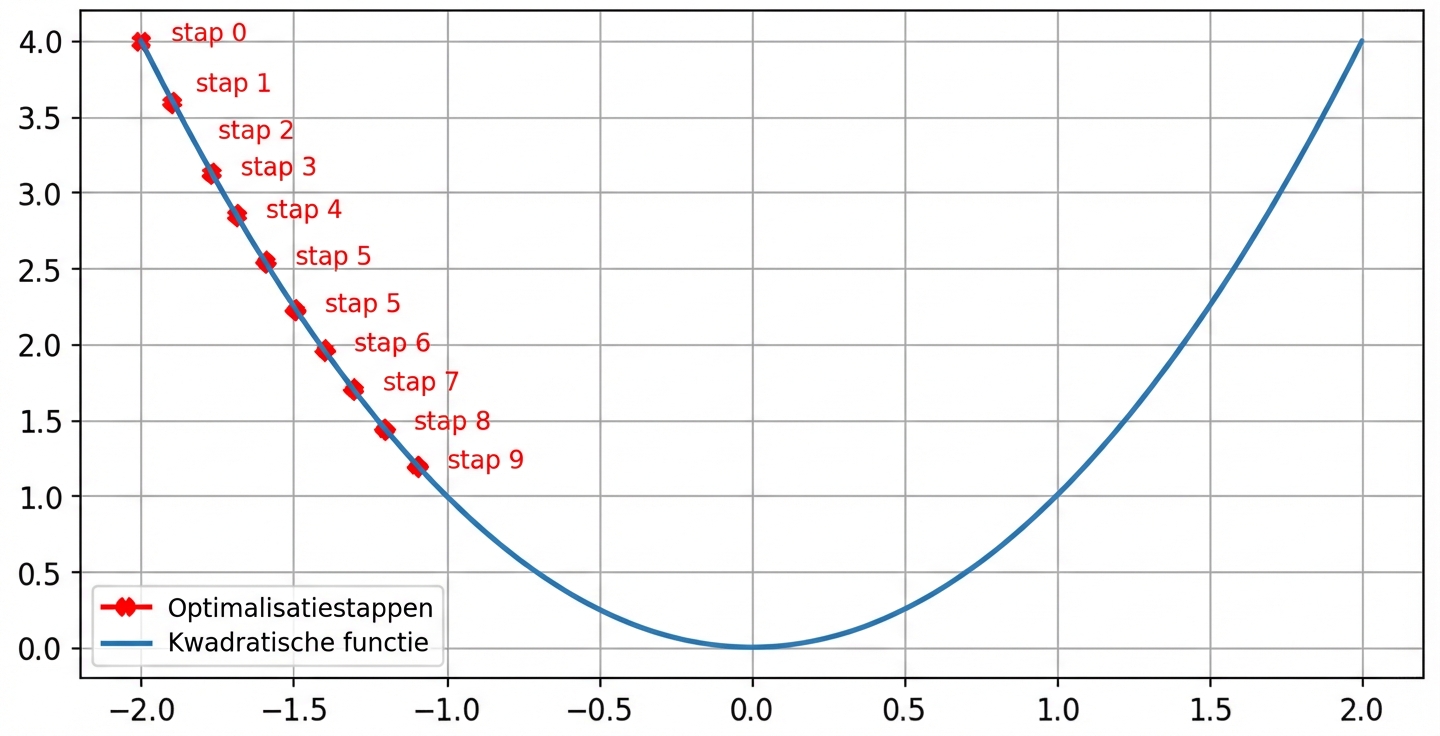
- Stapgrootte neemt af nabij nul als de gradiënt kleiner wordt
Effect van de learning rate: kleine learning rate
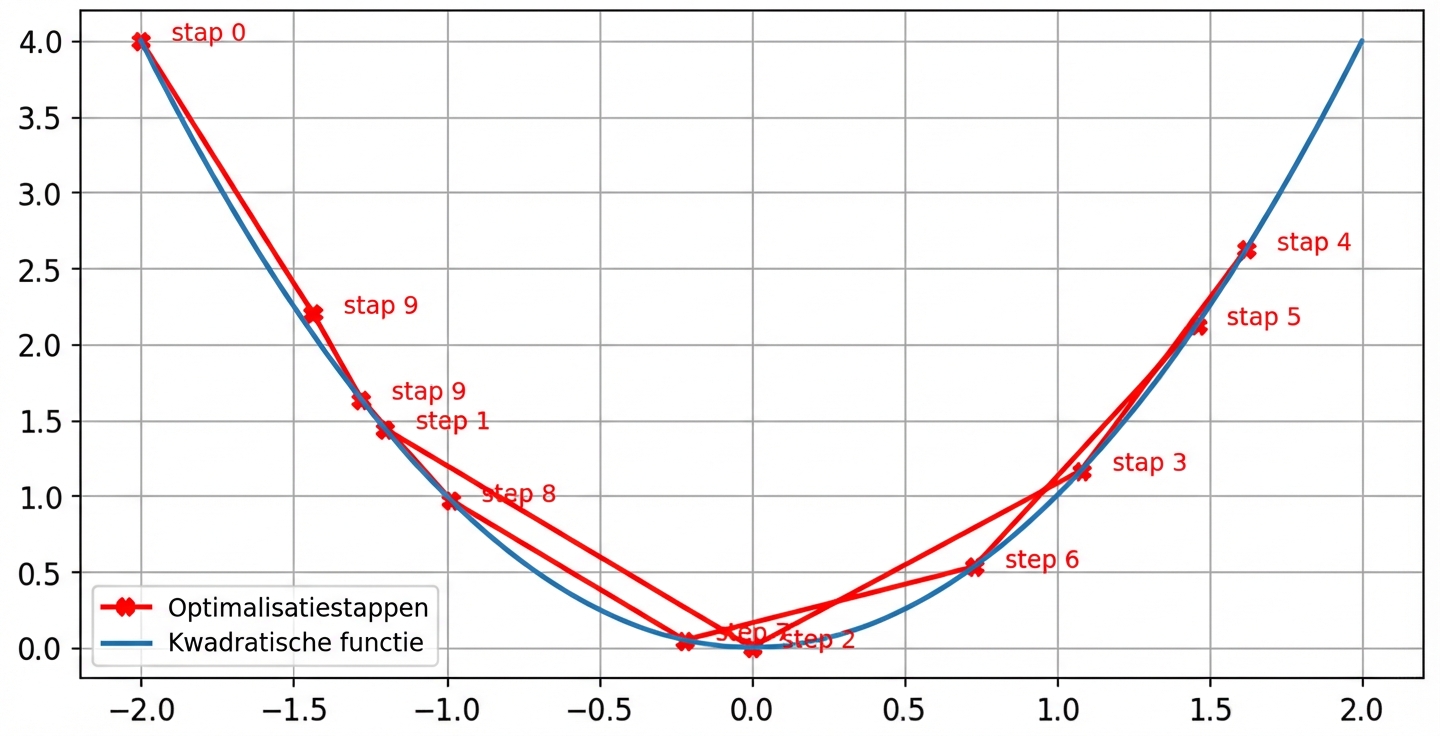
Effect van de learning rate: hoge learning rate
Convexe en niet-convexe functies
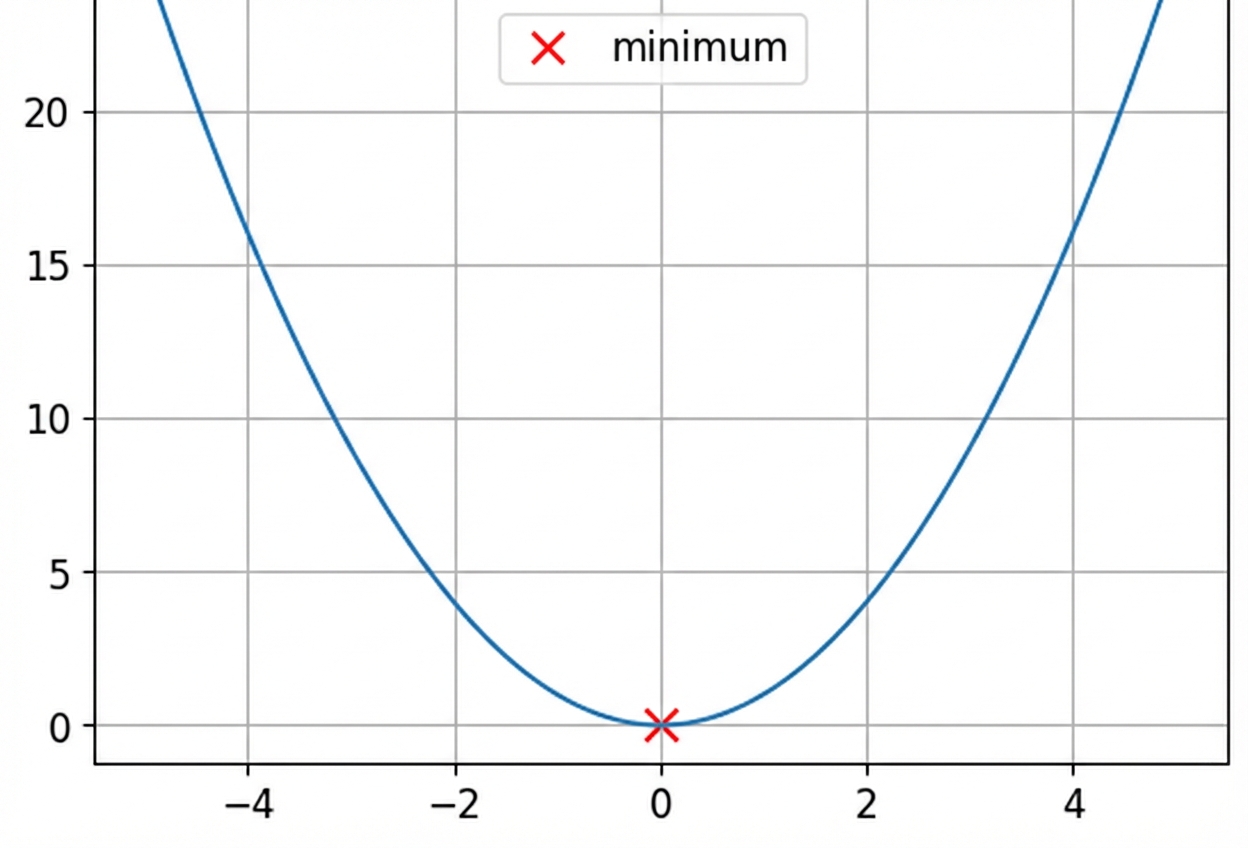
Dit is een convexe functie.
Dit is een niet-convexe functie.
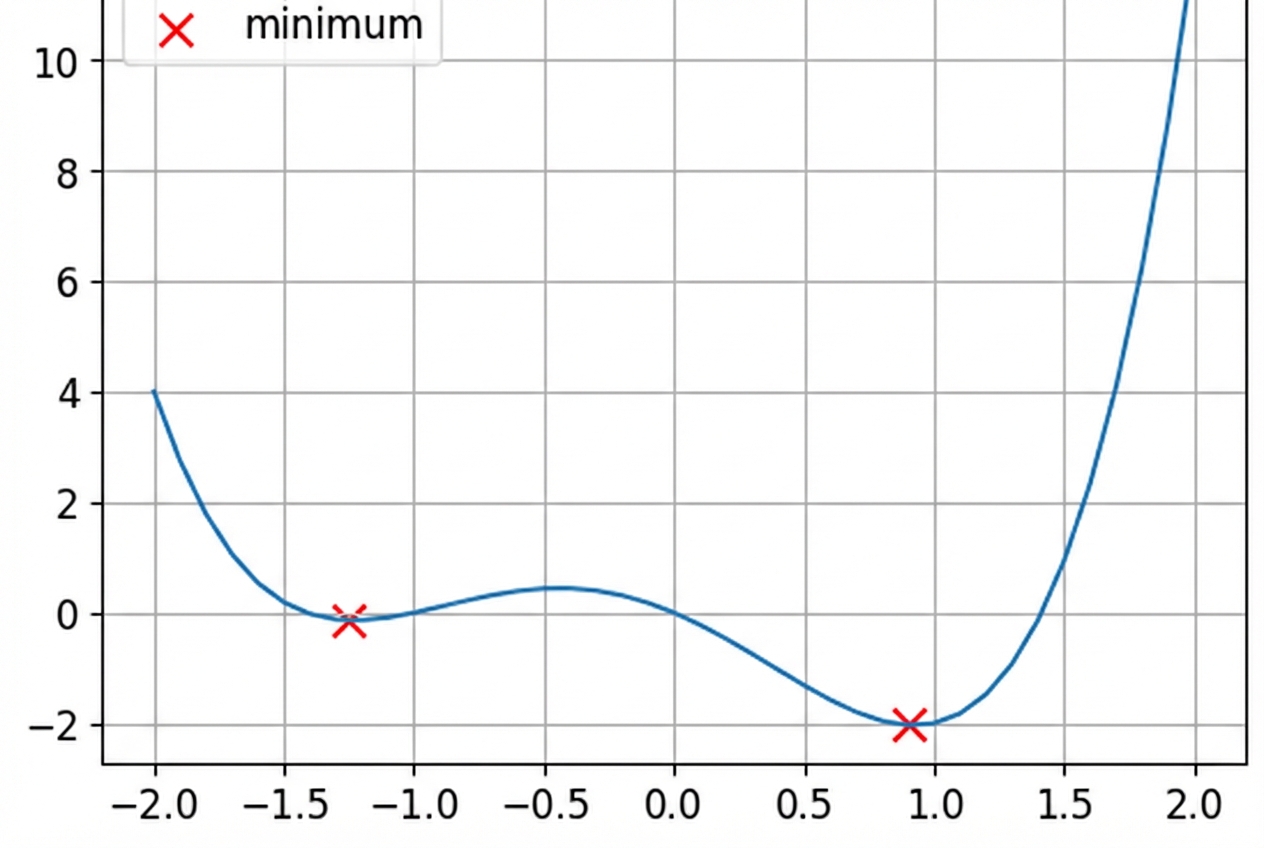
- Lossfuncties zijn niet-convex
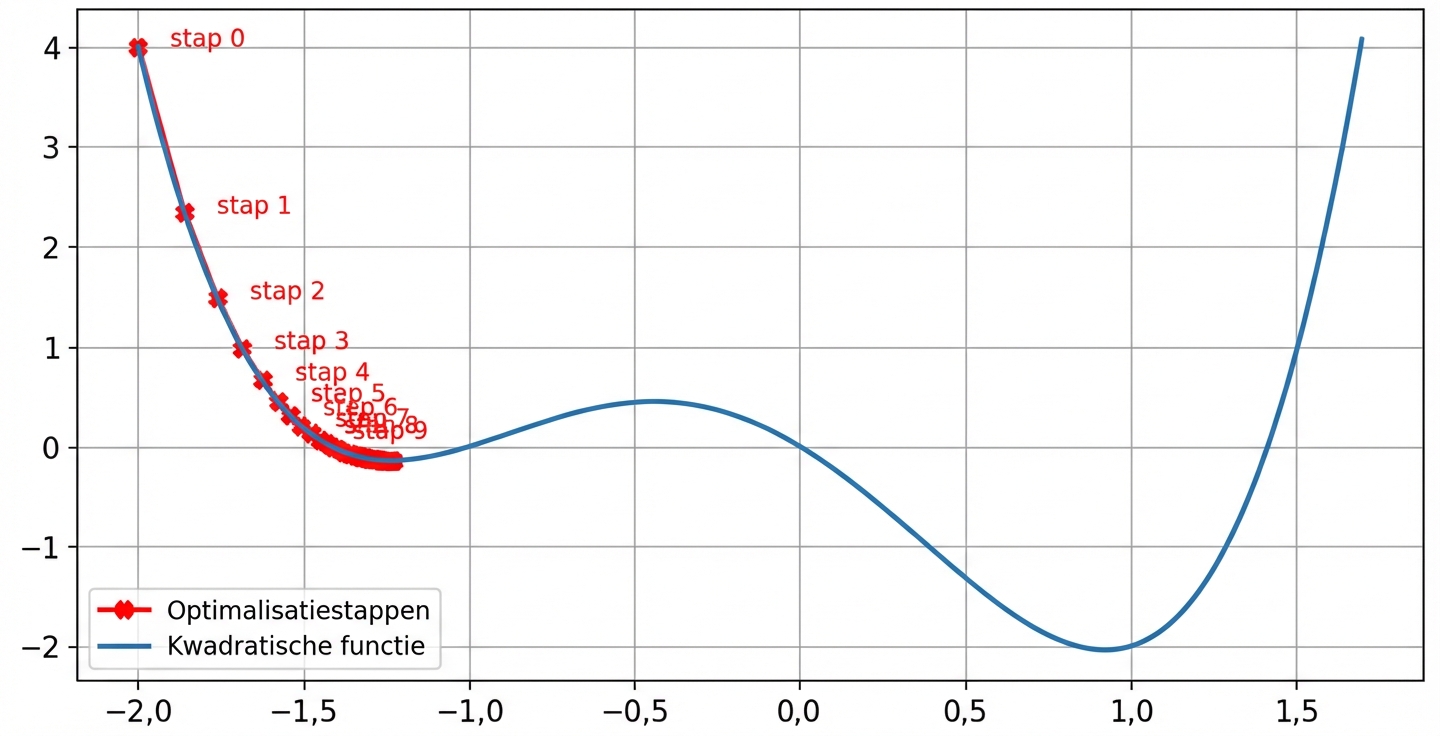
Zonder momentum
lr = 0.01momentum = 0, na 100 stappen minimum gevonden bijx = -1.23eny = -0.14
Met momentum
lr = 0.01momentum = 0.9, na 100 stappen minimum gevonden bijx = 0.92eny = -2.04