Afgeleiden gebruiken om modelparameters bij te werken
Introductie tot Deep Learning met PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Een analogie voor afgeleiden
$$

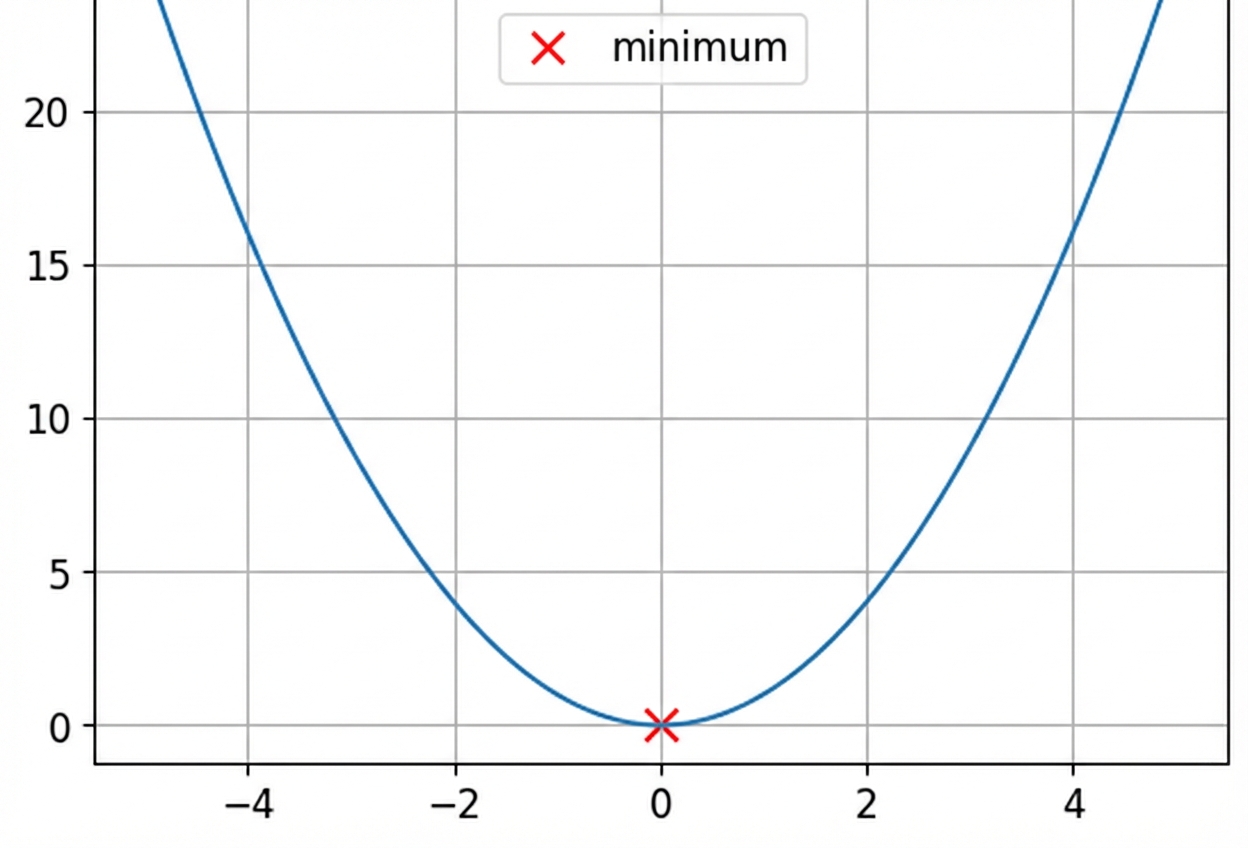
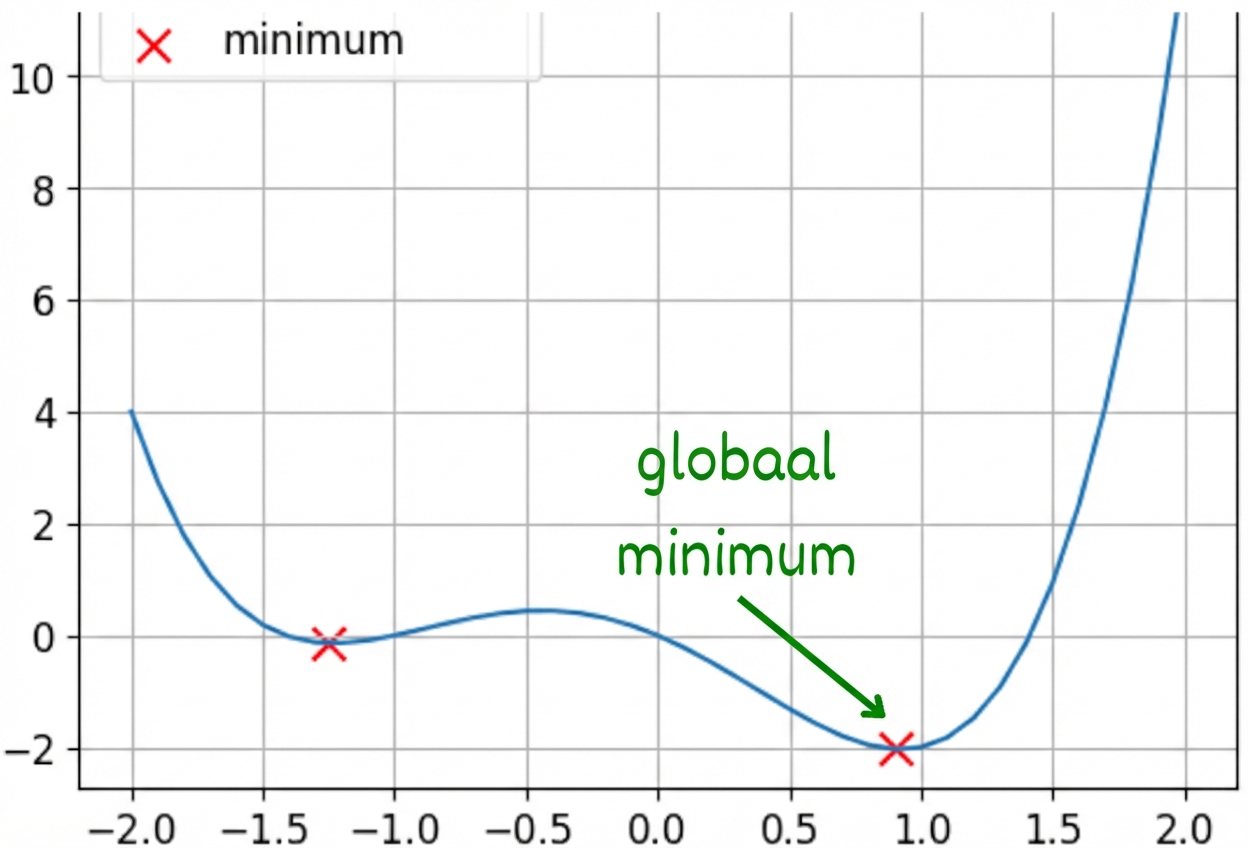
Convexe en niet-convexe functies
Dit is een convexe functie
Dit is een niet-convexe functie
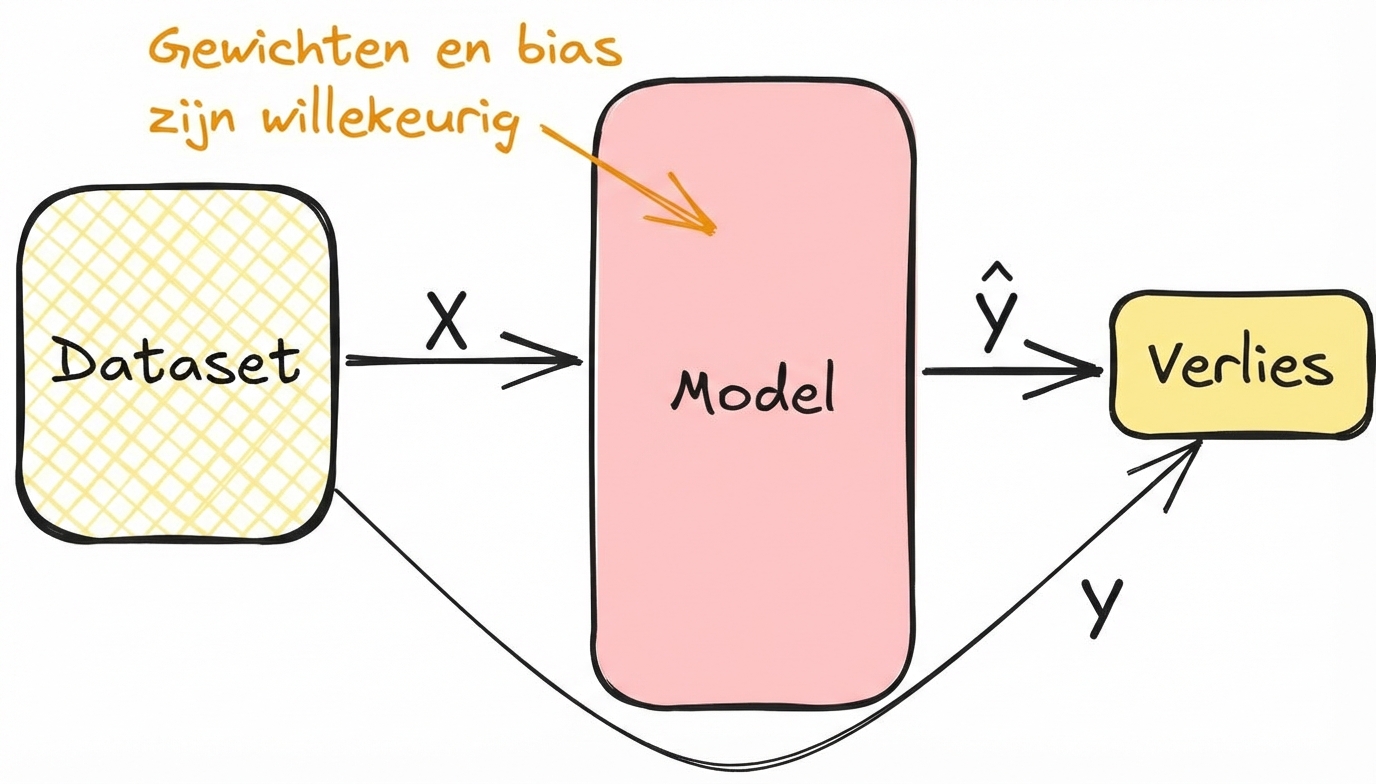
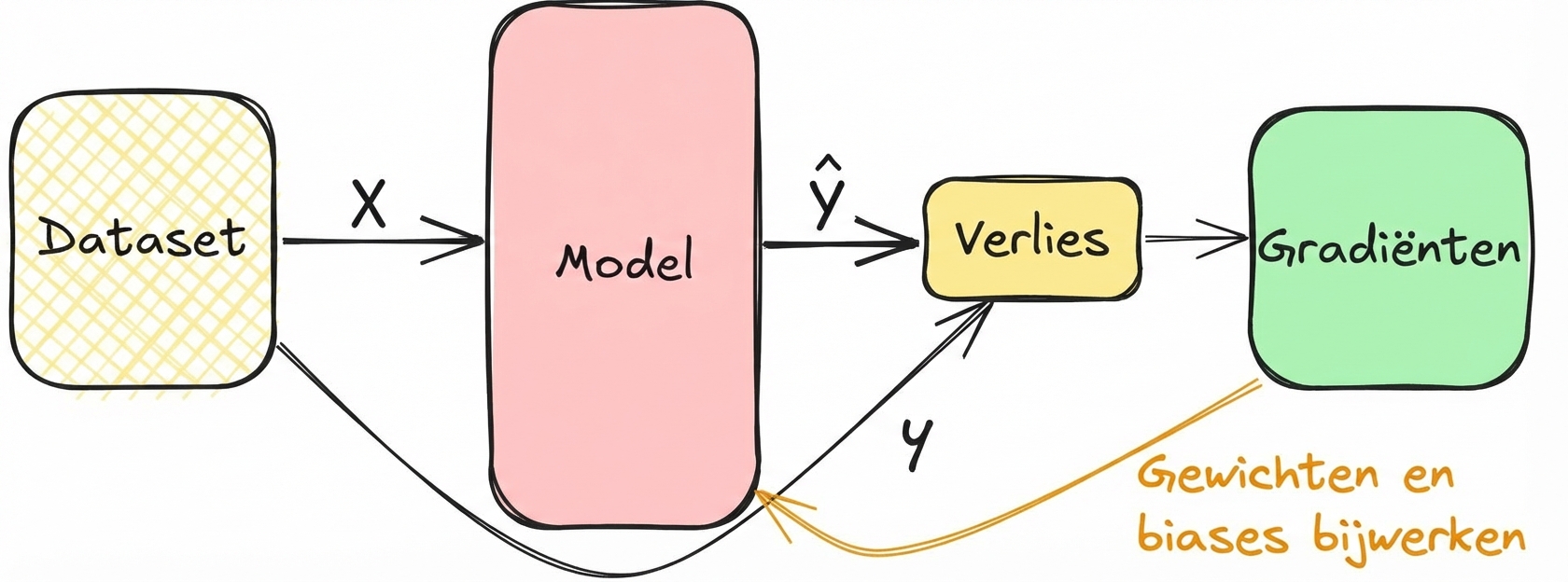
Afgeleiden koppelen aan modeltraining
- Bereken de loss in de forward pass tijdens training
$$
Afgeleiden koppelen aan modeltraining
- Gradiënten minimaliseren de loss en stemmen gewichten en biases af
- Herhaal tot de lagen afgestemd zijn
$$
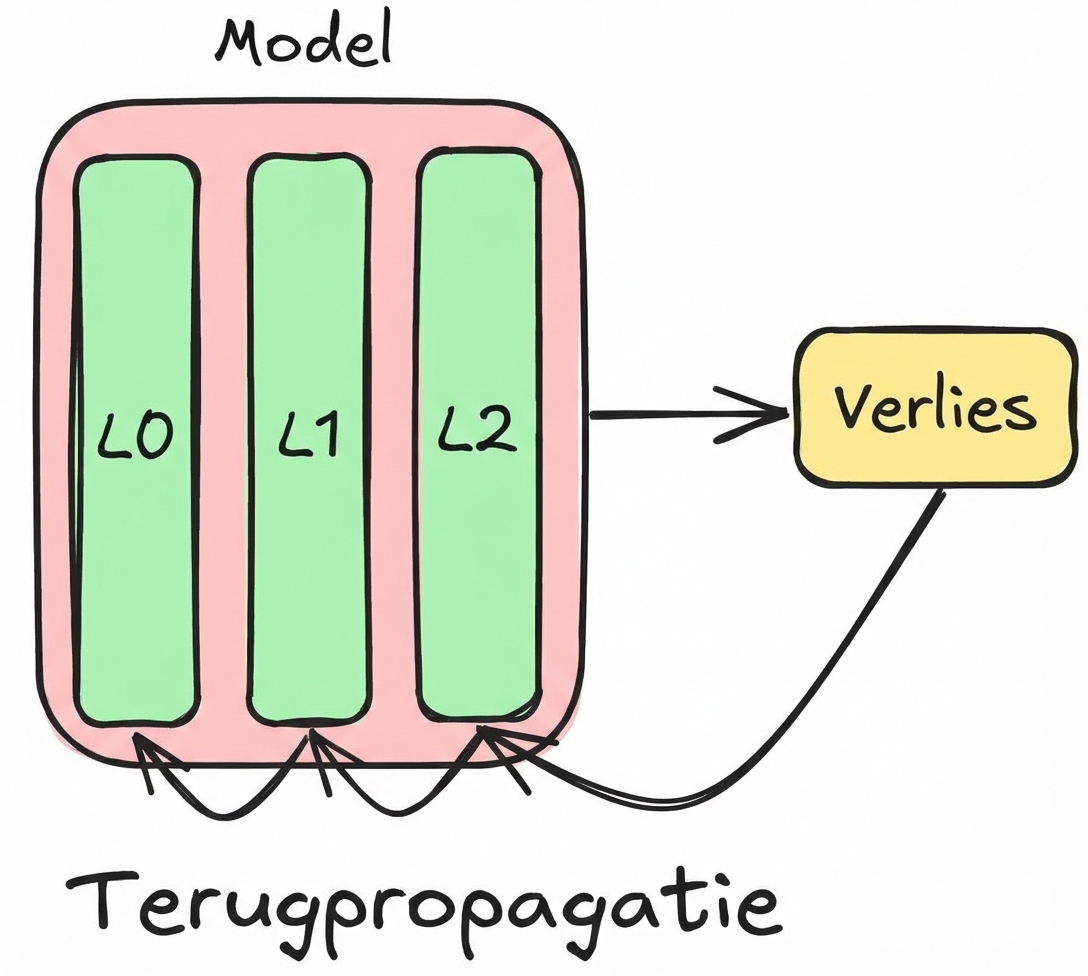
Backpropagation: concepten