De centrale limietstelling
Inleiding tot statistiek in Python

Maggie Matsui
Content Developer, DataCamp
5 keer met de dobbelsteen gooien

Steekproevenverdelingen
Steekproevenverdeling van het steekproefgemiddelde
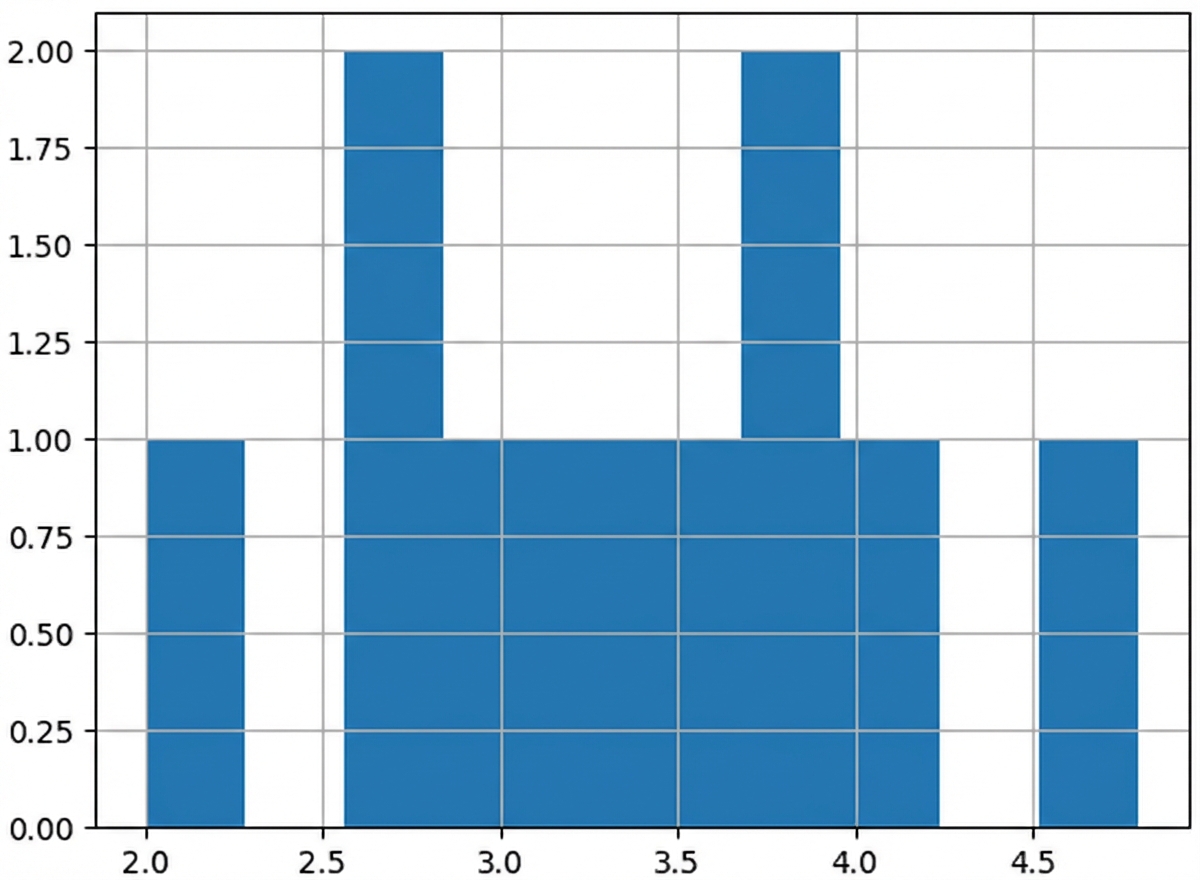
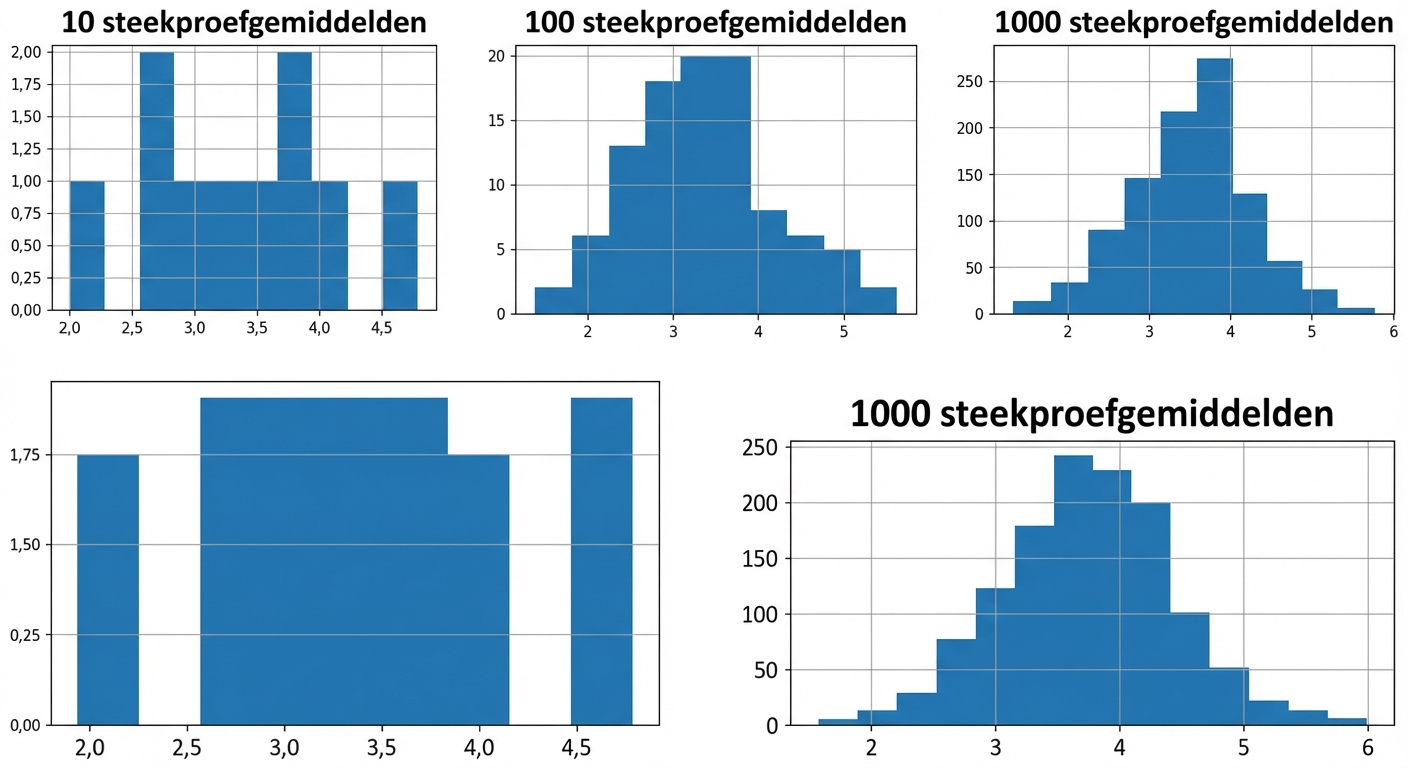
100 steekproefgemiddelden
sample_means = []
for i in range(100):
sample_means.append(np.mean(die.sample(5, replace=True)))
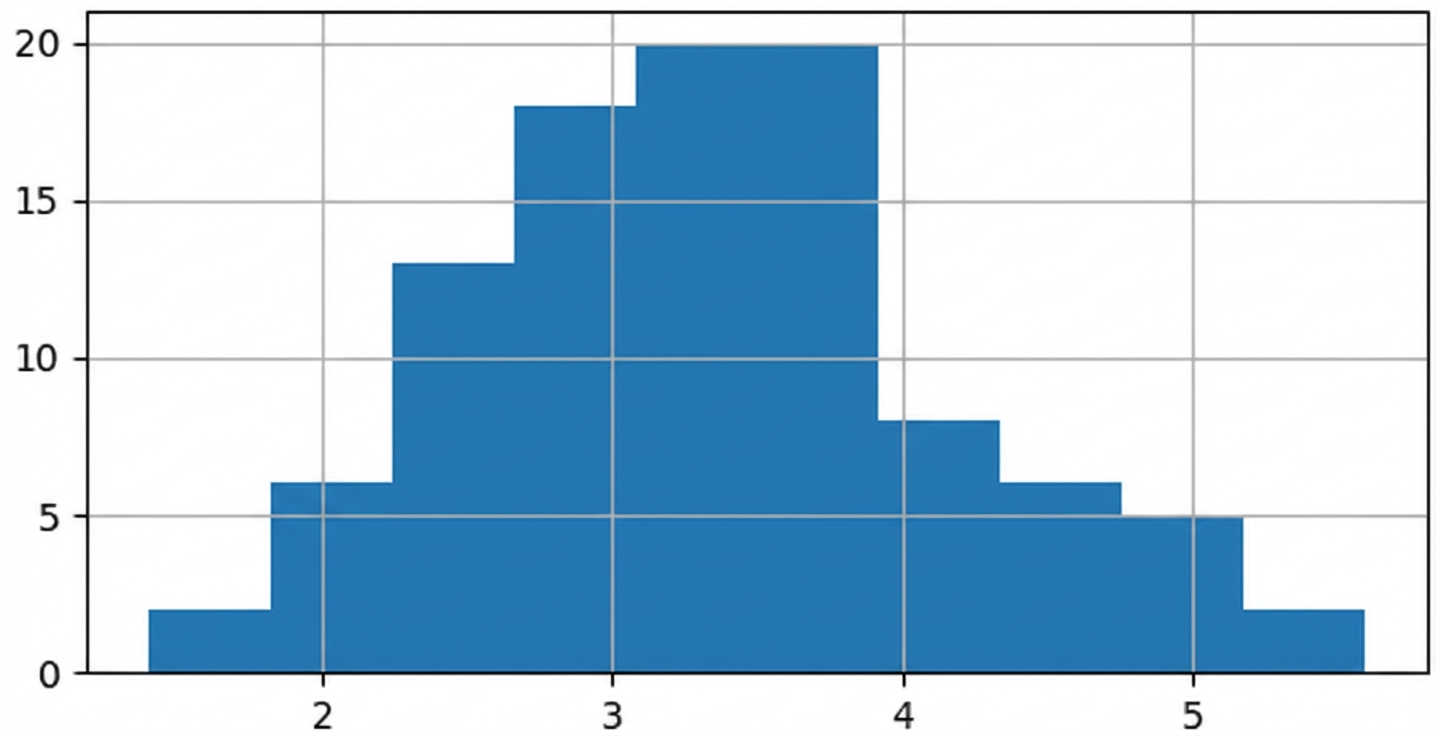
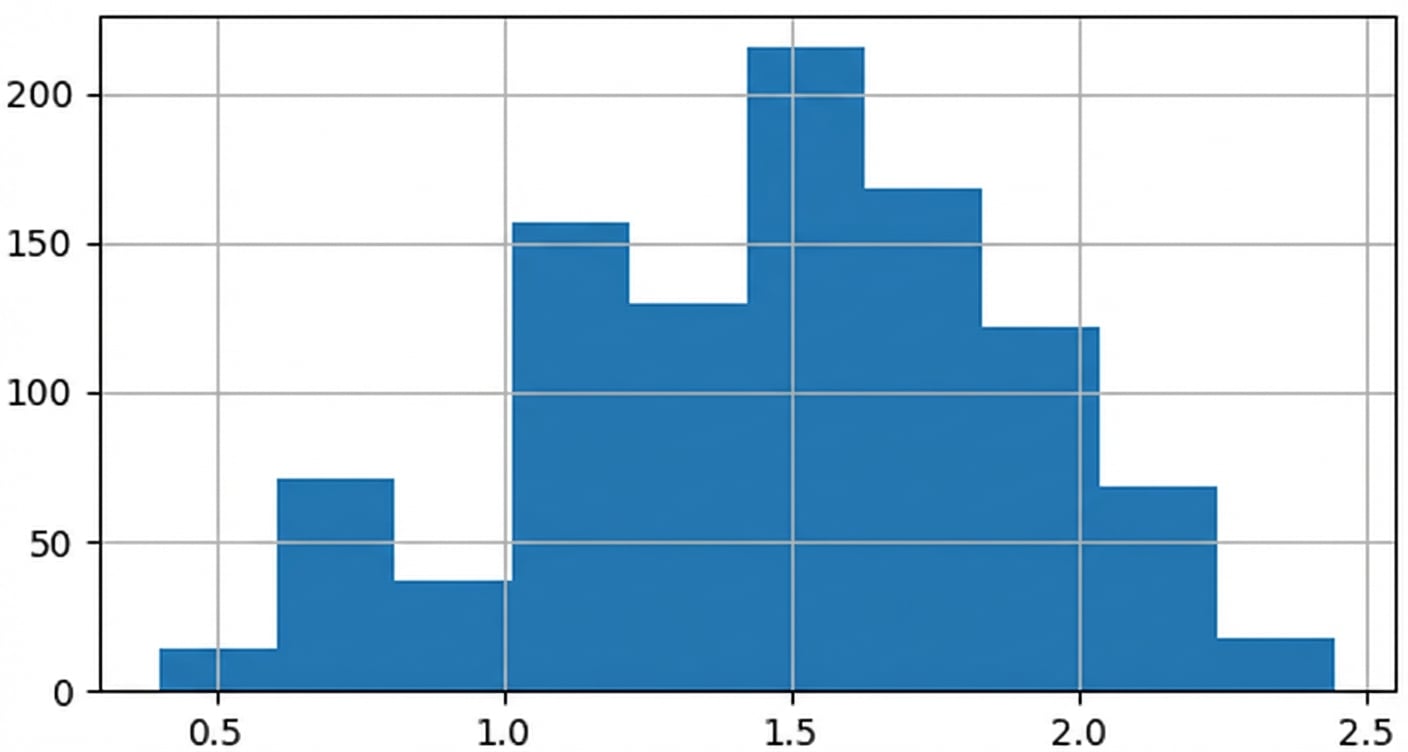
1000 steekproefgemiddelden
sample_means = []
for i in range(1000):
sample_means.append(np.mean(die.sample(5, replace=True)))
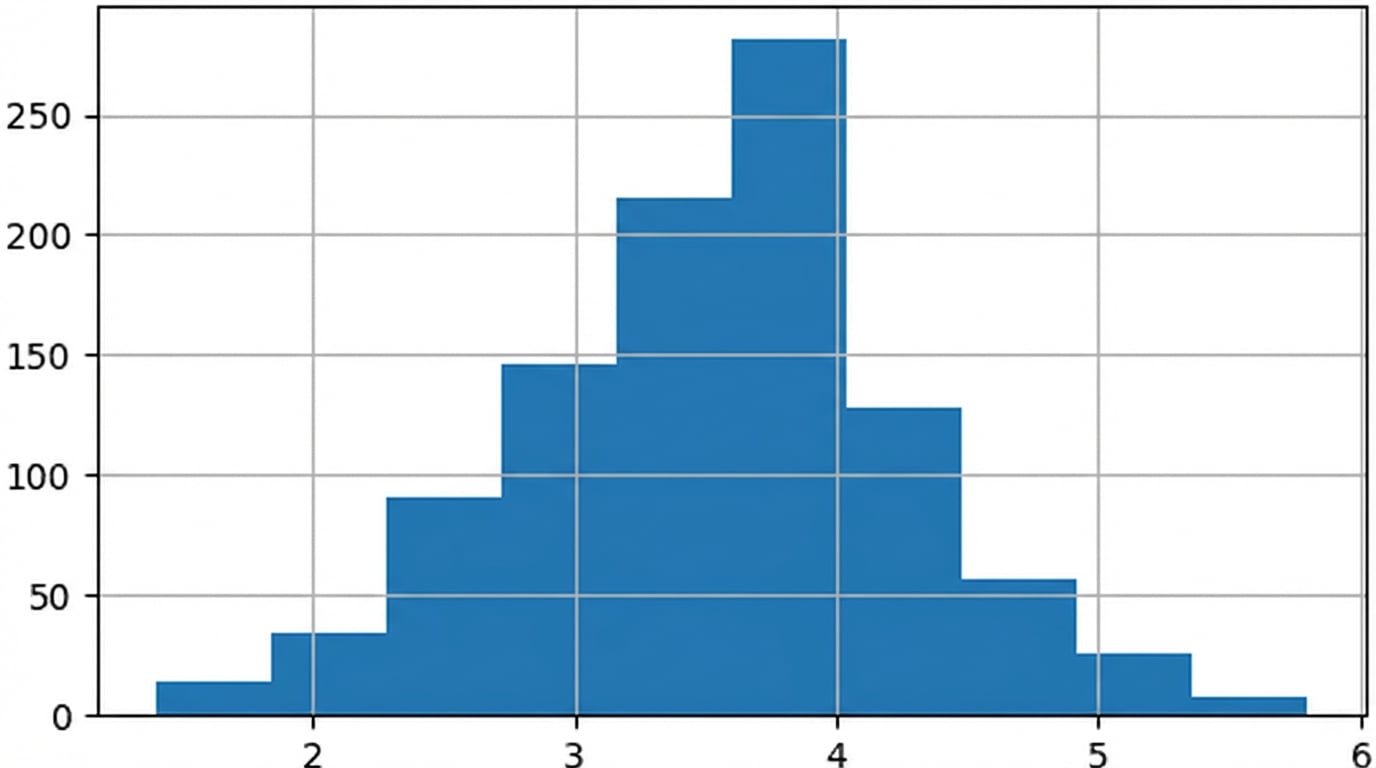
Centrale limietstelling
De steekproevenverdeling van een statistiek wordt normaler naarmate het aantal trekkingen toeneemt.
* Steekproeven moeten willekeurig en onafhankelijk zijn
Standaarddeviatie en de CLT
sample_sds = []
for i in range(1000):
sample_sds.append(np.std(die.sample(5, replace=True)))
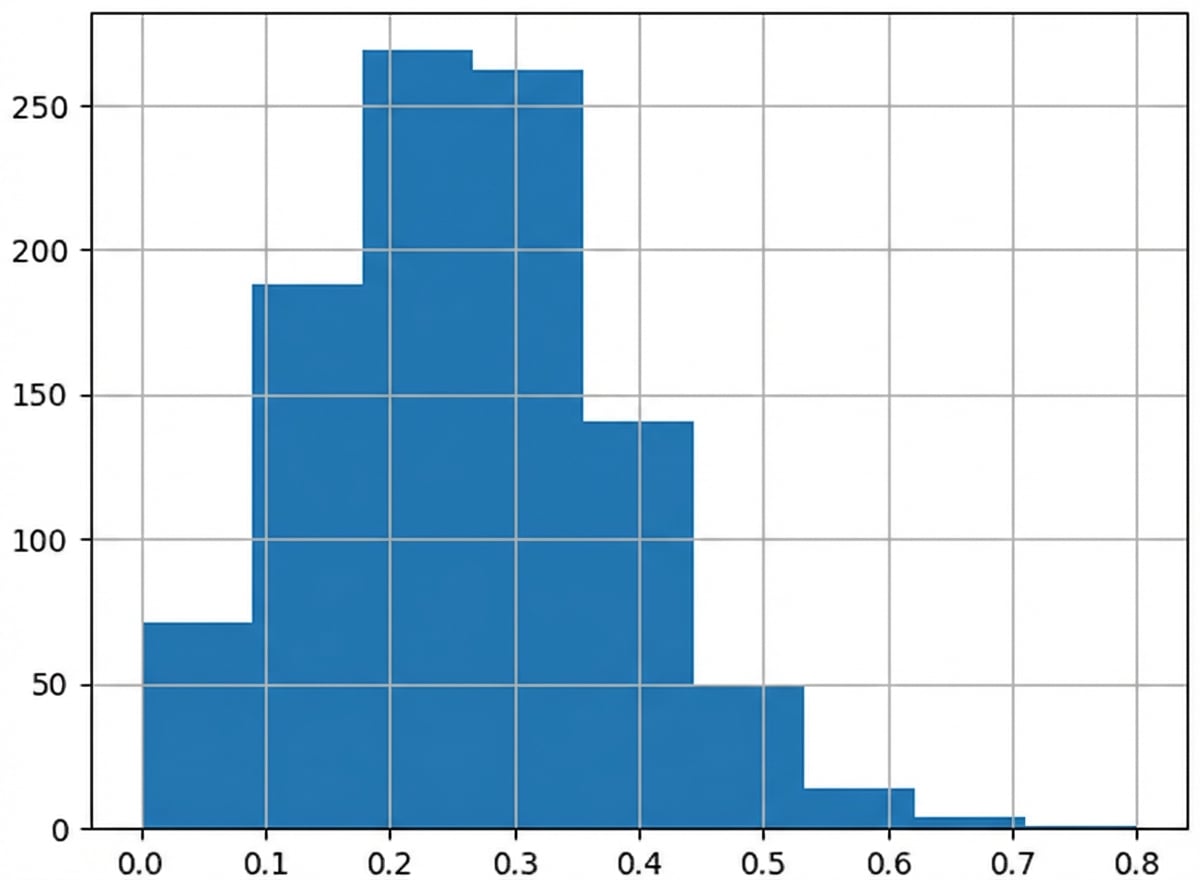
Steekproevenverdeling van proportie
Gemiddelde van de steekproevenverdeling
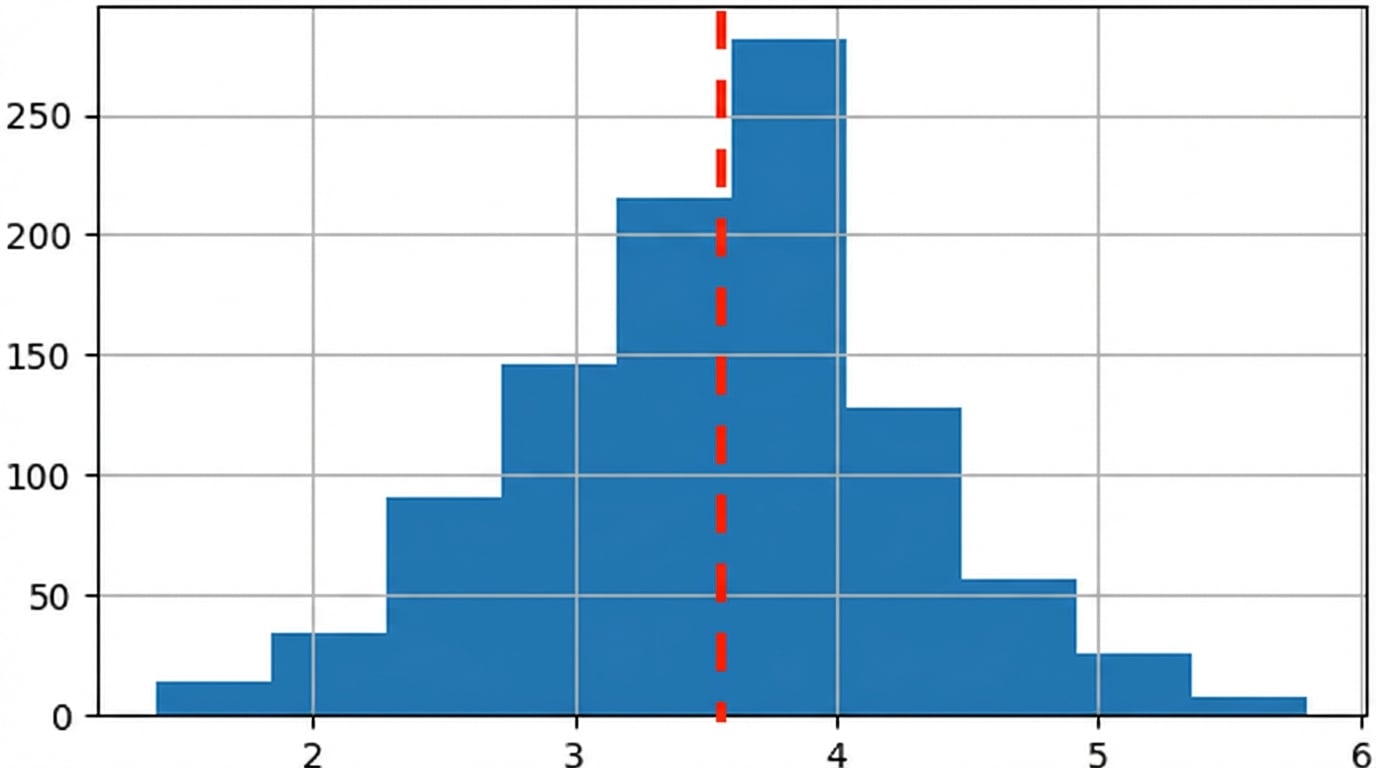
- Kenmerken van een onbekende onderliggende verdeling schatten
- Kenmerken van grote populaties makkelijker schatten

