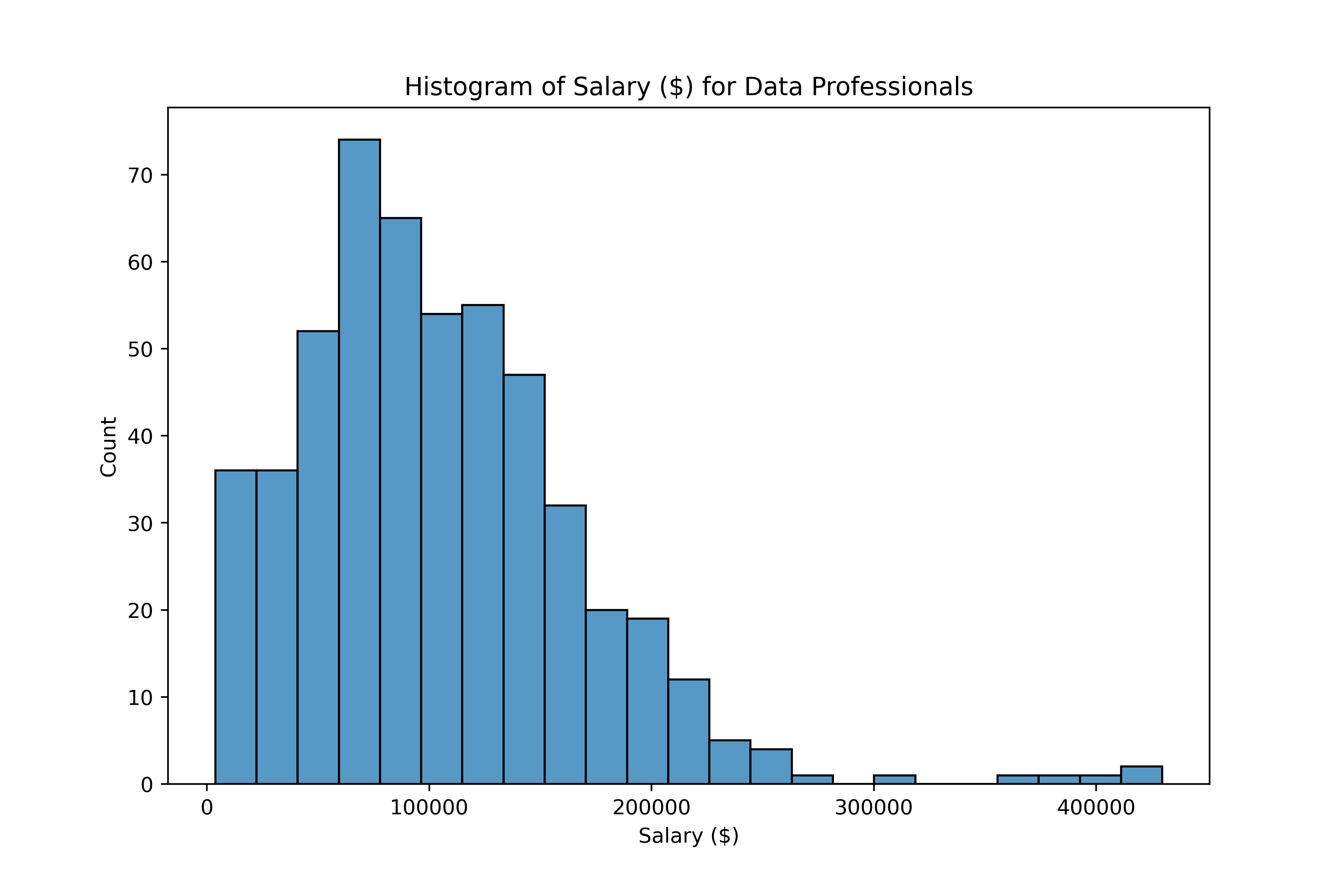
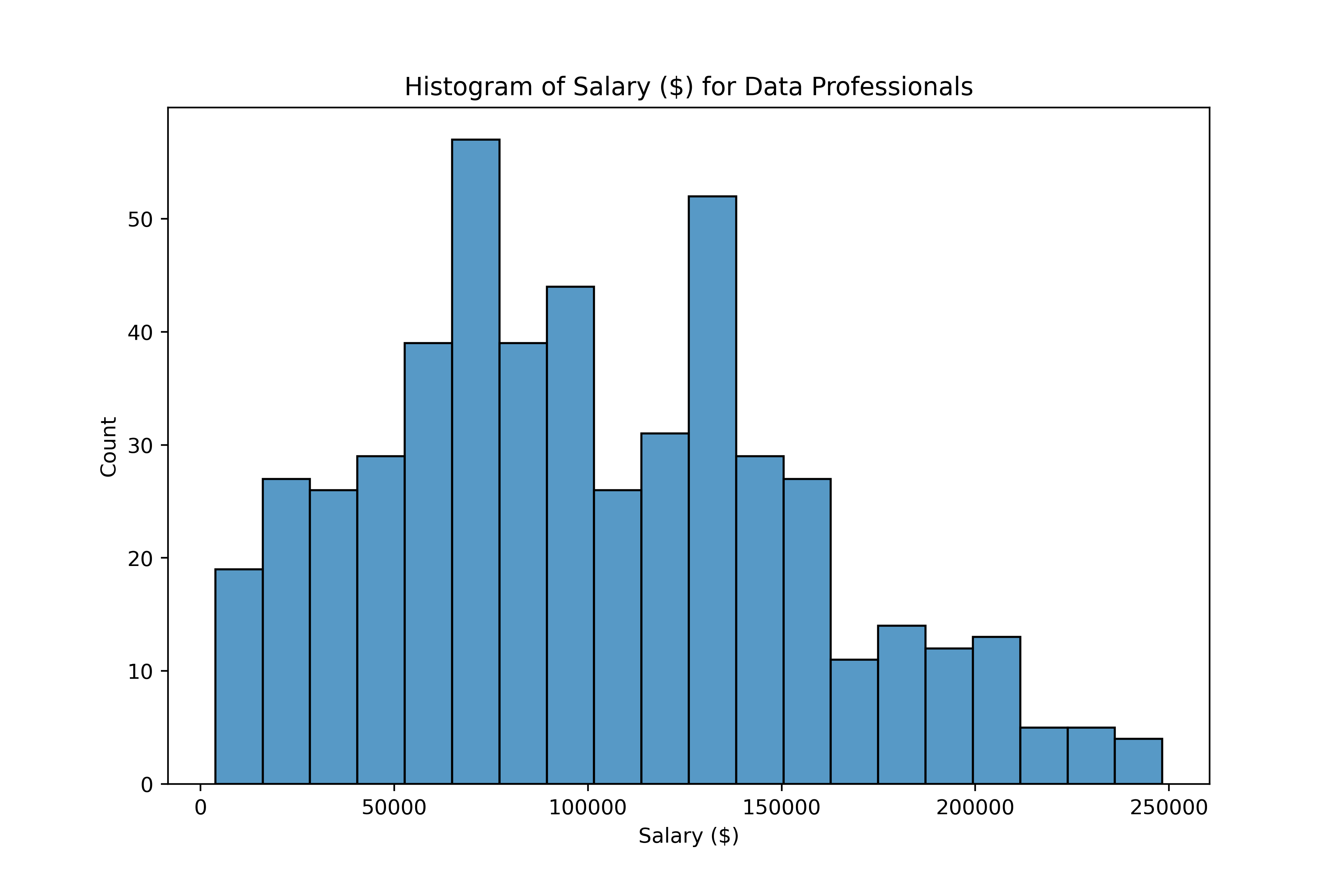
Omgaan met uitschieters
Exploratory Data Analysis in Python

George Boorman
Curriculum Manager, DataCamp
Wat is een uitschieter?

1 Image credit: https://unsplash.com/@ralphkayden
IQR in boxplots
sns.boxplot(data=salaries,
y="Salary_USD")
plt.show()
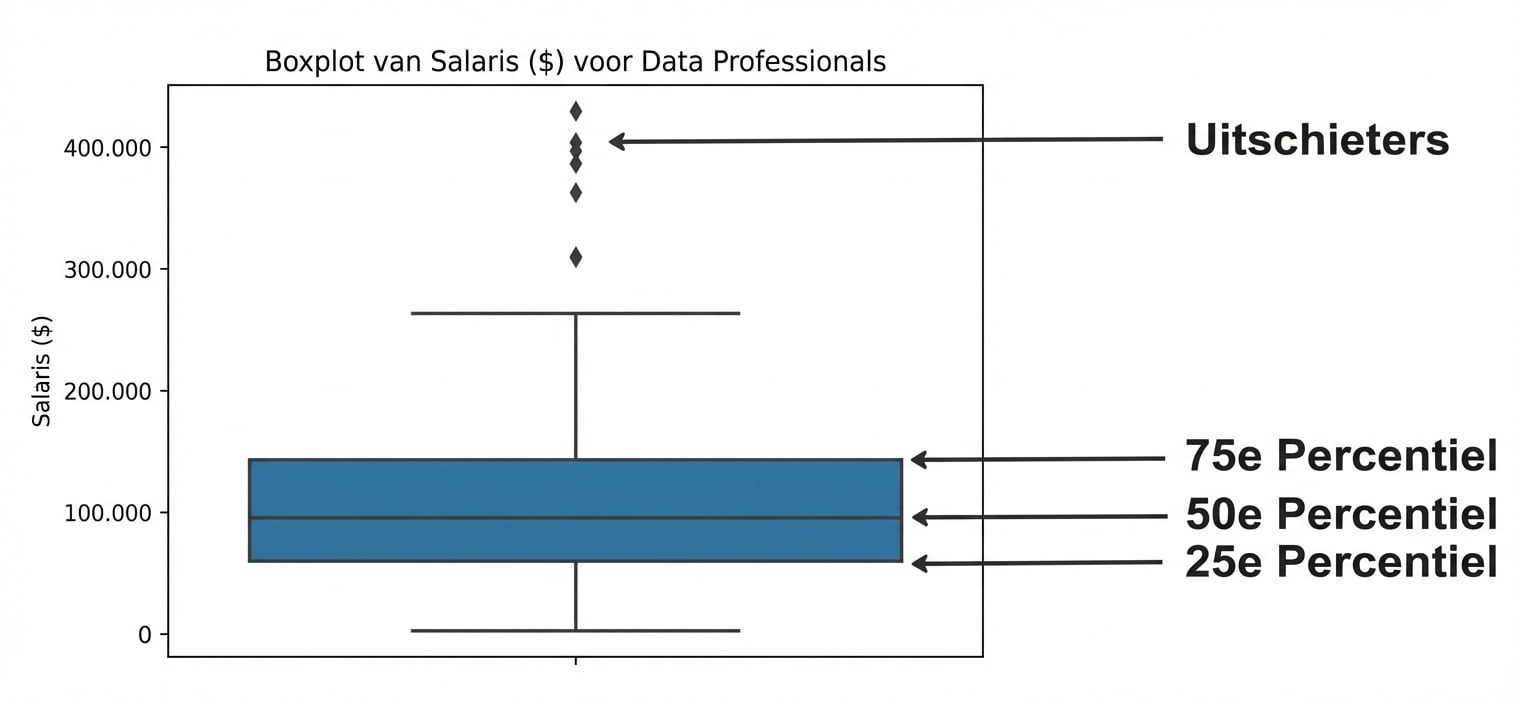
Verdeling van salarissen