Ontbrekende data aanpakken
Exploratory Data Analysis in Python

George Boorman
Curriculum Manager, DataCamp
Waarom zijn ontbrekende waarden een probleem?
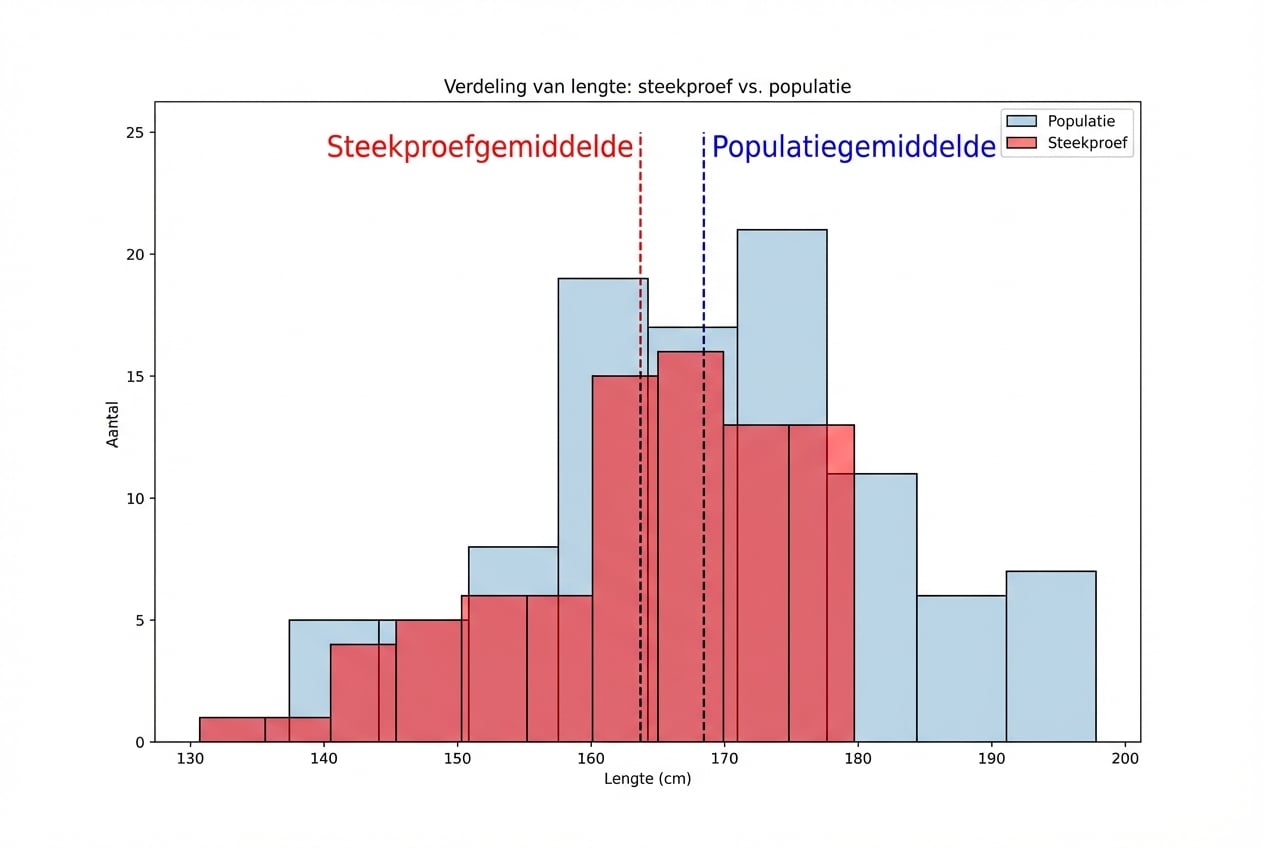
Salaris per ervaringsniveau
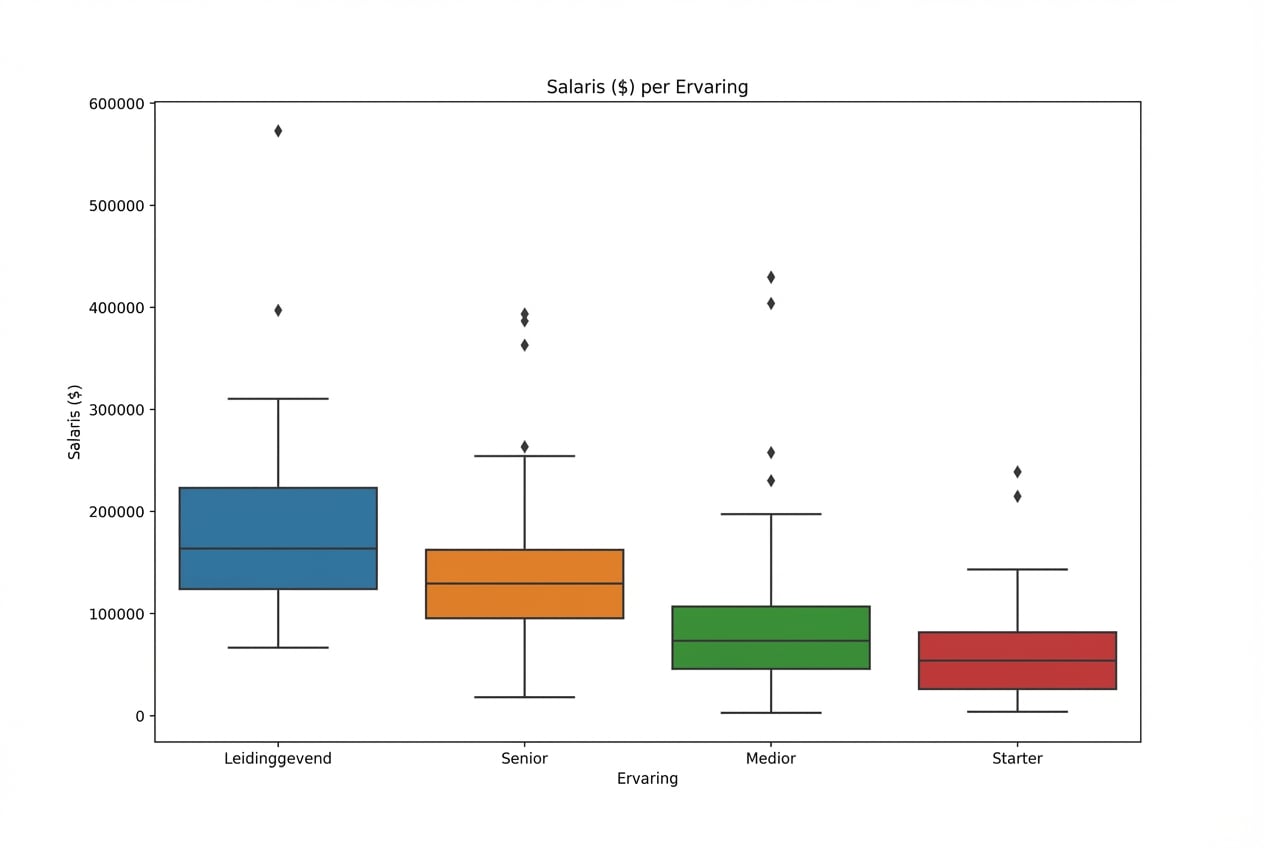
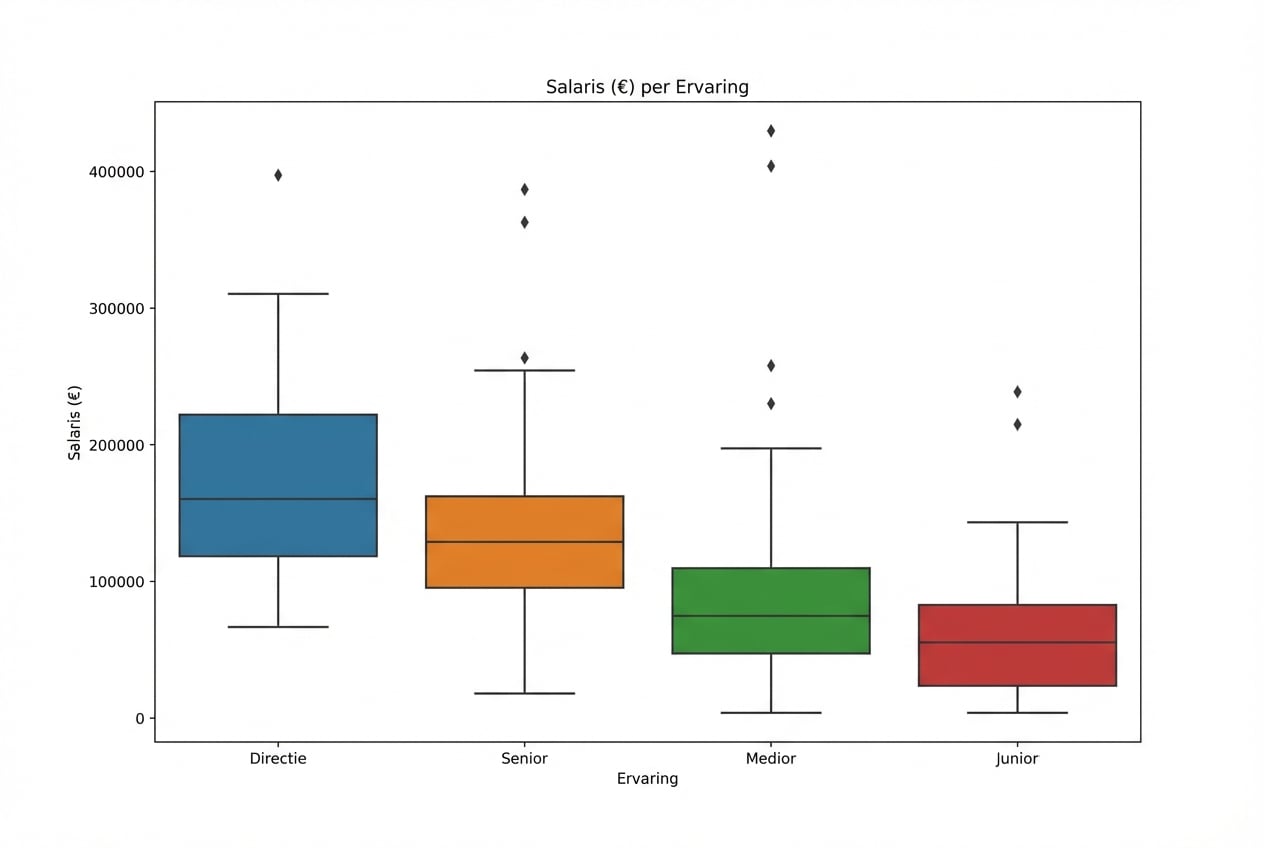
Exploratory Data Analysis in Python
George Boorman
Curriculum Manager, DataCamp

