Externe data splitsen voor retrieval
LLM-toepassingen ontwikkelen met LangChain

Jonathan Bennion
AI Engineer & LangChain Contributor
RAG-ontwikkelstappen
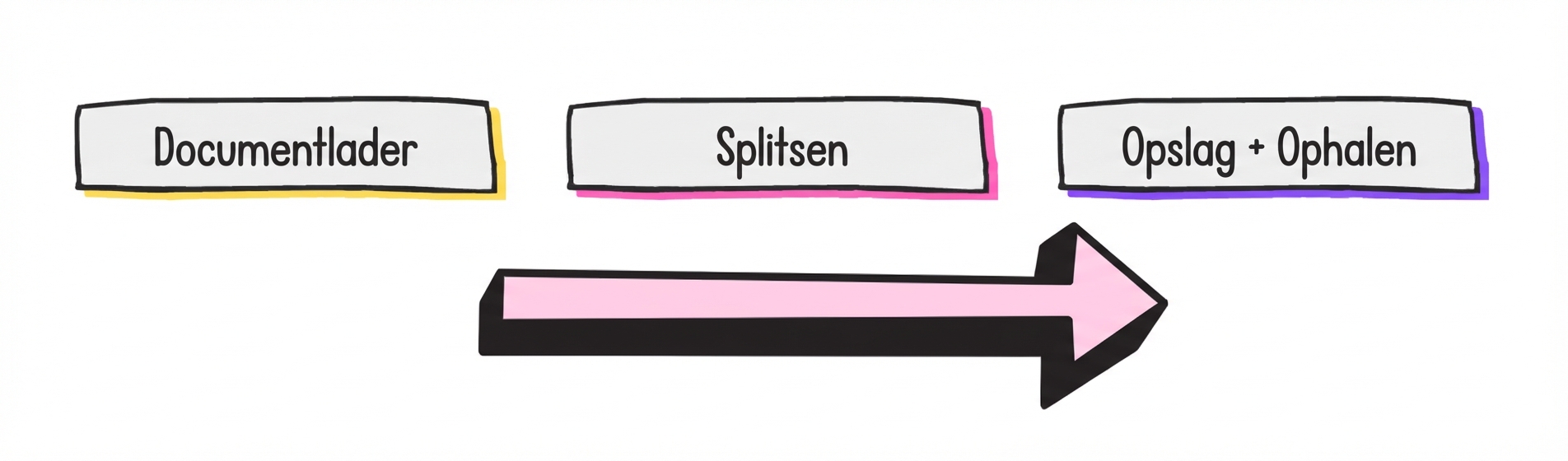
- Document splitting: document opdelen in chunks
- Splits om binnen het contextvenster van een LLM te passen
Nadenken over splitsen...

1 https://arxiv.org/abs/1706.03762
Chunk-overlap
Wat is de beste strategie om te splitsen?

1 Wikipedia Commons

