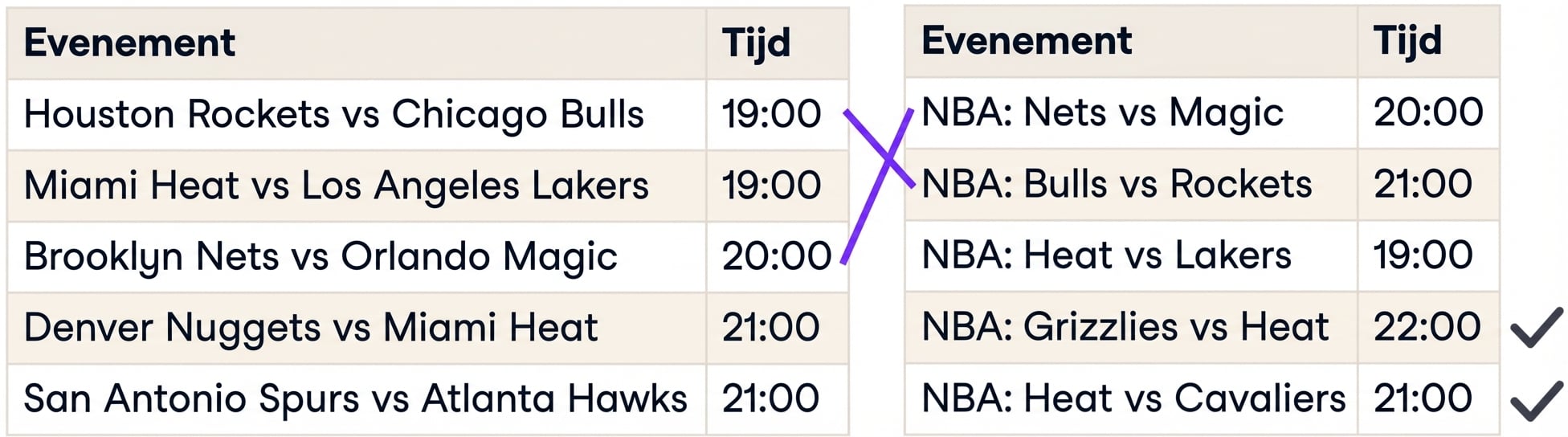
Strings vergelijken
Data opschonen in Python

Adel Nehme
VP of AI Curriculum, DataCamp
Minimale bewerkingsafstand

Minimaal aantal stappen om van de ene string naar de andere te gaan
Minimale bewerkingsafstand

Minimaal aantal stappen om van de ene string naar de andere te gaan
Minimale bewerkingsafstand
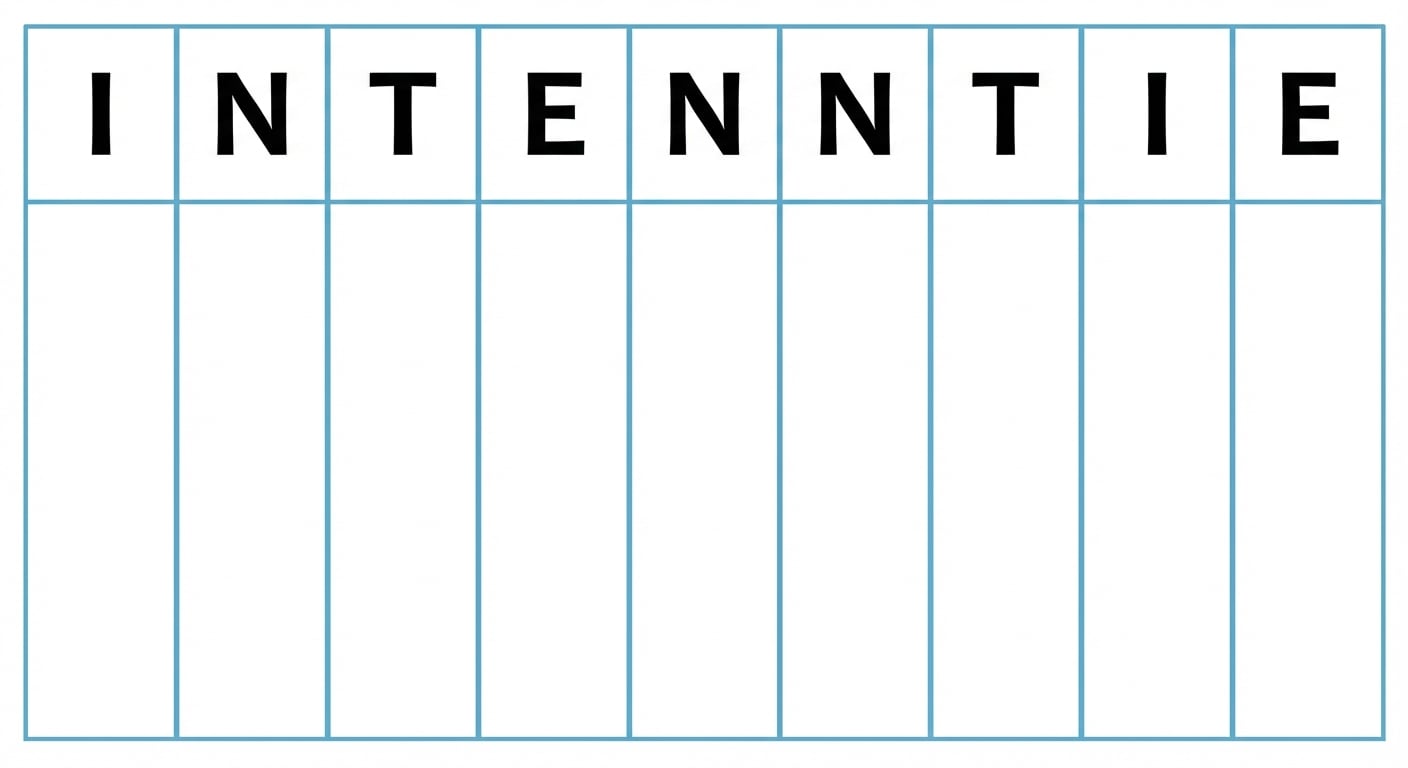
Minimale bewerkingsafstand
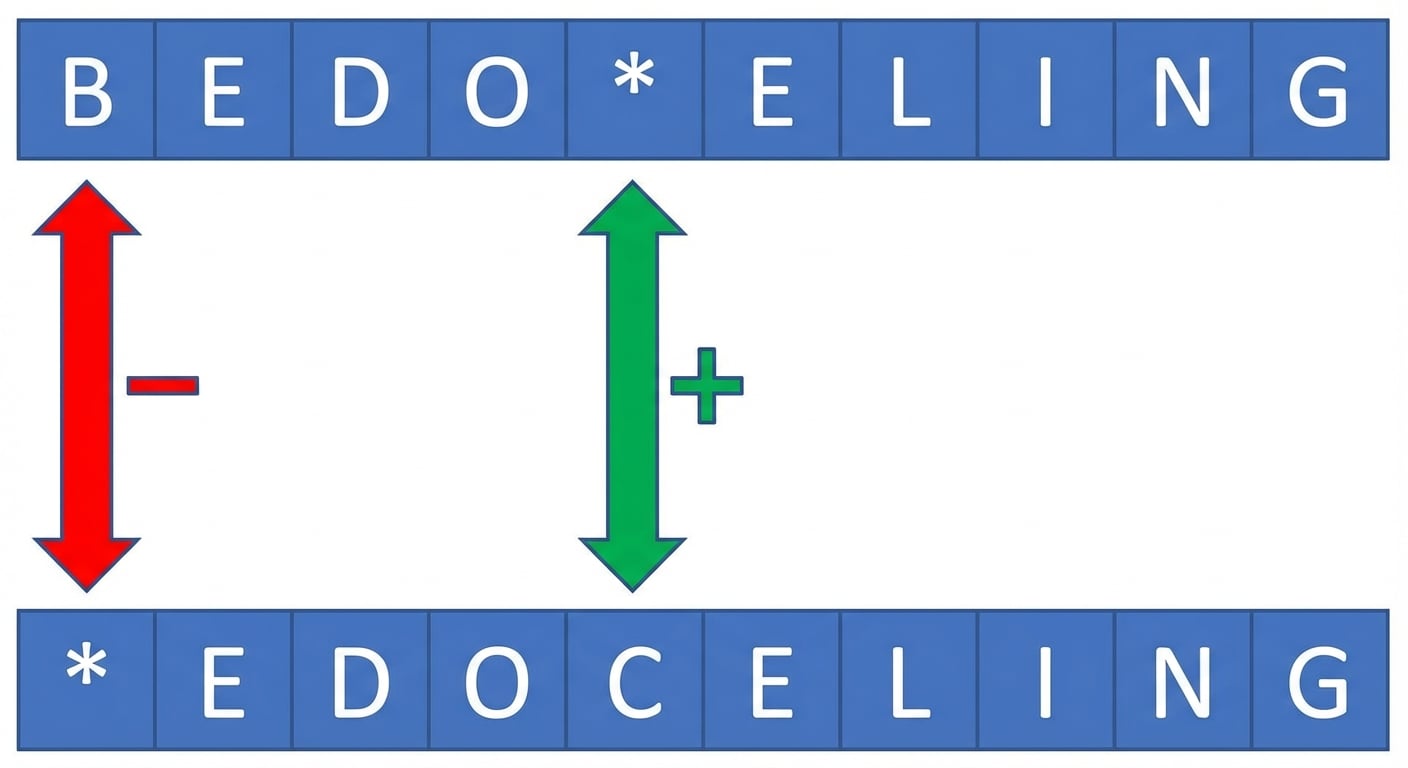
Huidige minimale bewerkingsafstand: 2
Minimale bewerkingsafstand
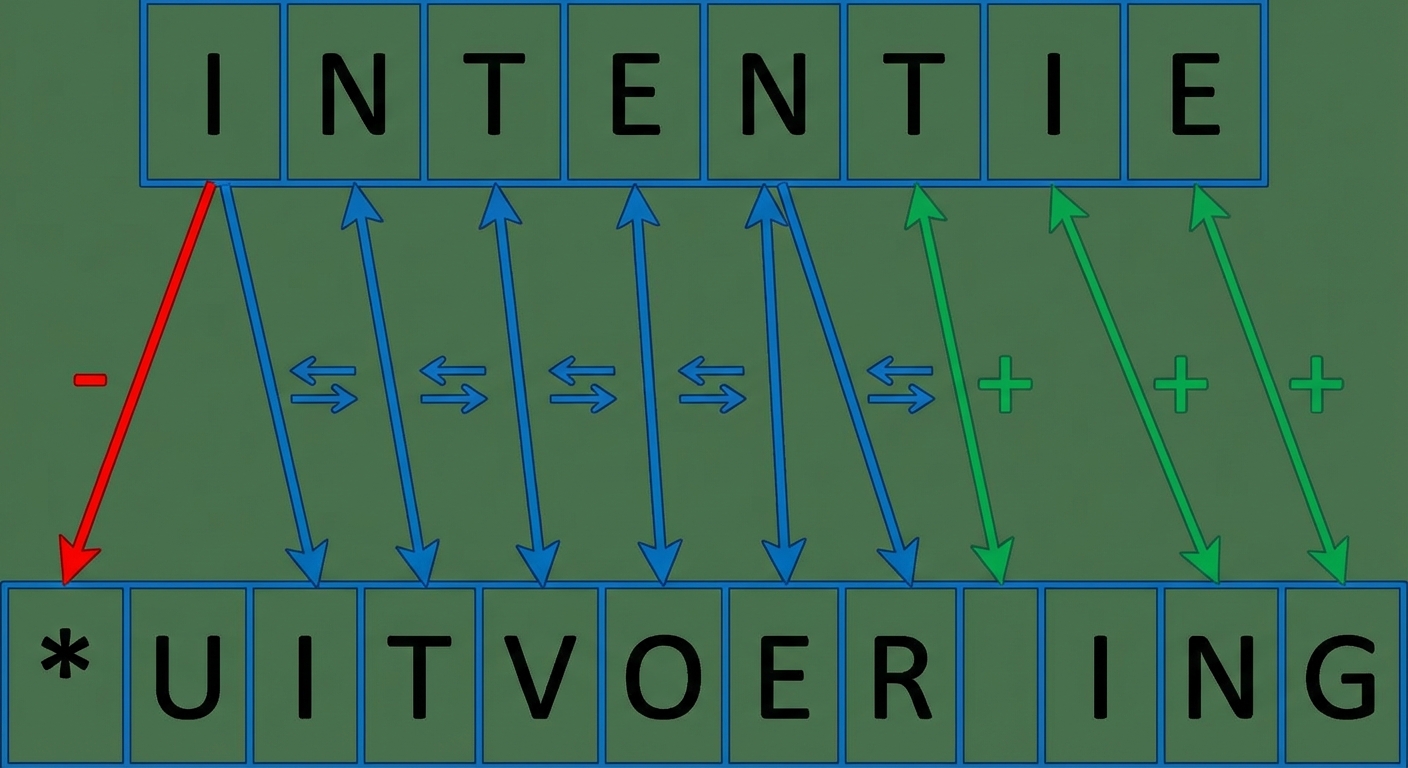
Minimale bewerkingsafstand: 5
Minimale bewerkingsafstand

Record linkage