De centrale limietstelling
Inleiding tot statistiek in R

Maggie Matsui
Content Developer, DataCamp
5 keer dobbelen

Steekproevenverdelingen
Steekproevenverdeling van het steekproefgemiddelde
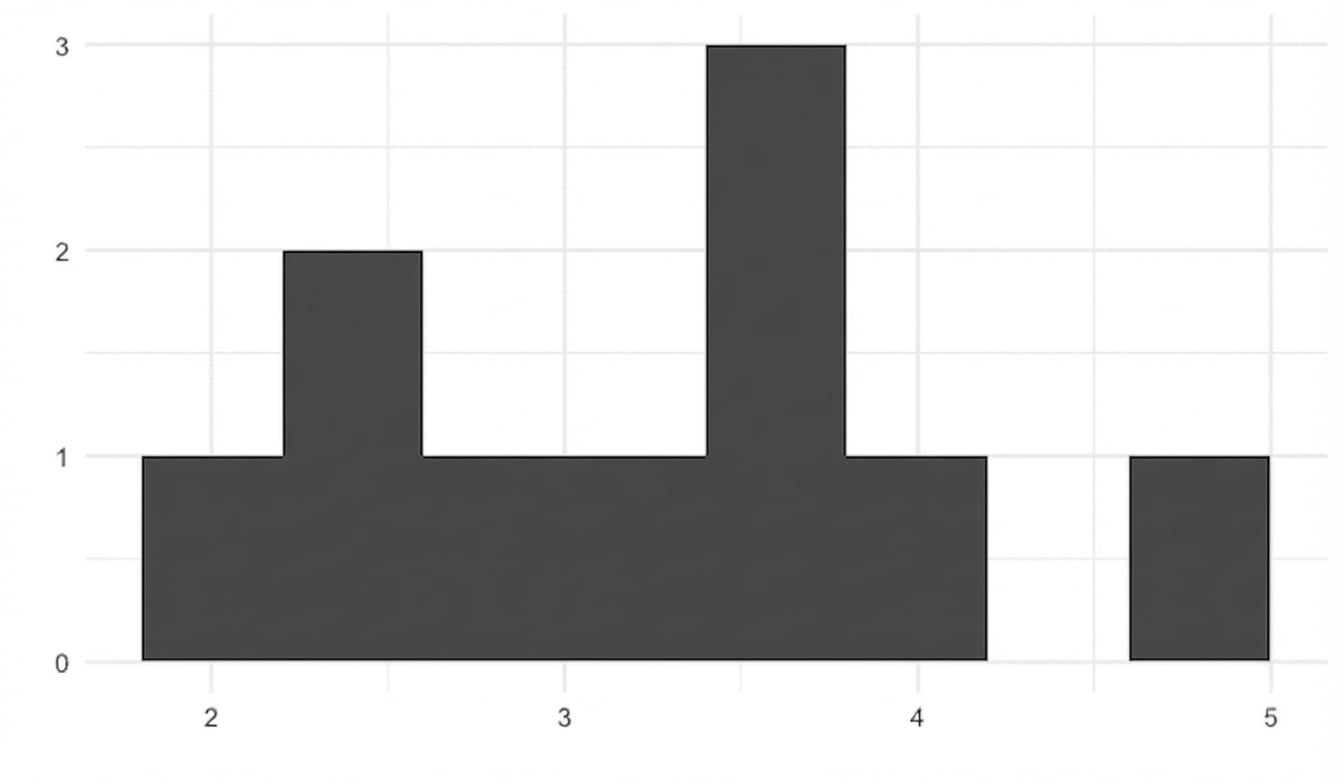
100 steekproefgemiddelden
replicate(100, sample(die, 5, replace = TRUE) %>% mean())
2.8 3.2 1.8 4.6 4.0 2.8 4.4 2.4 3.4 2.8 4.2 3.4 ... 2.2 3.8 3.6 3.8 4.4 4.8 2.4
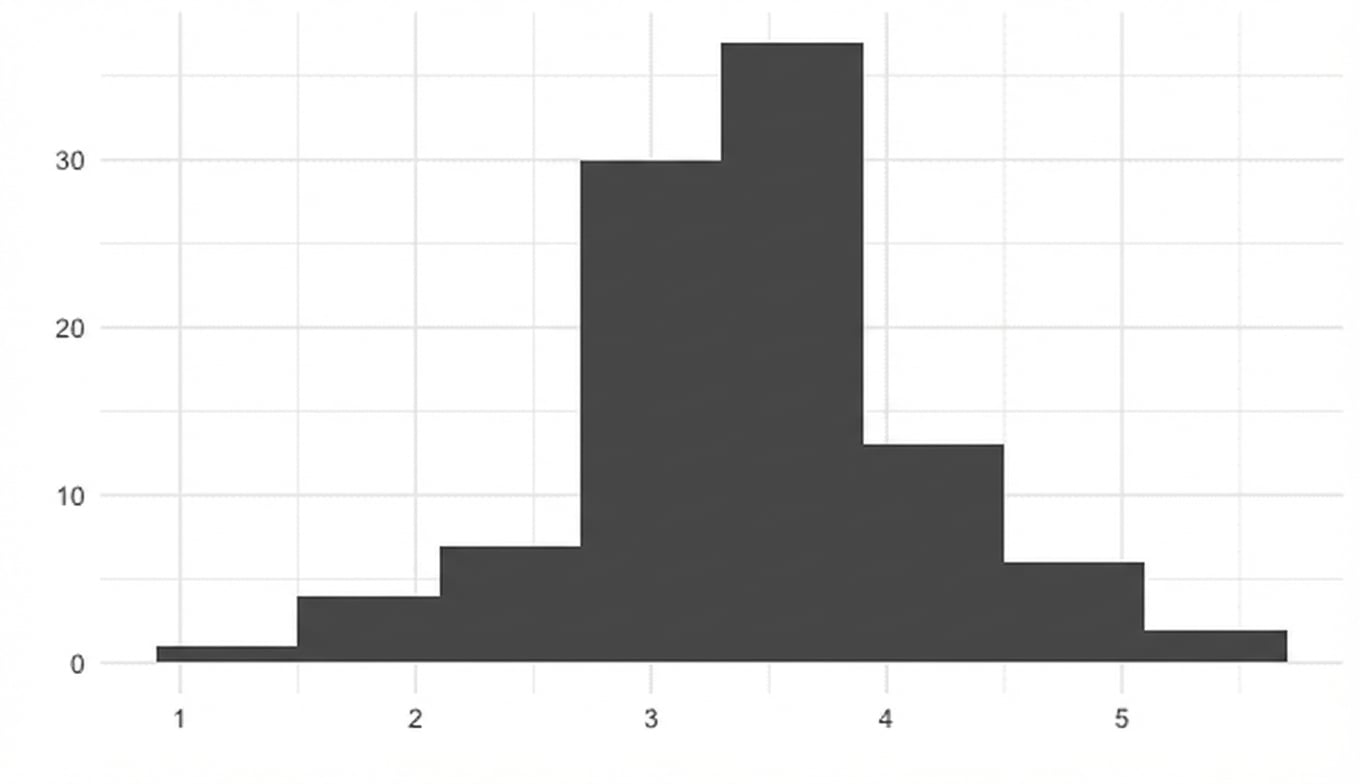
1000 steekproefgemiddelden
sample_means <- replicate(1000, sample(die, 5, replace = TRUE) %>% mean())
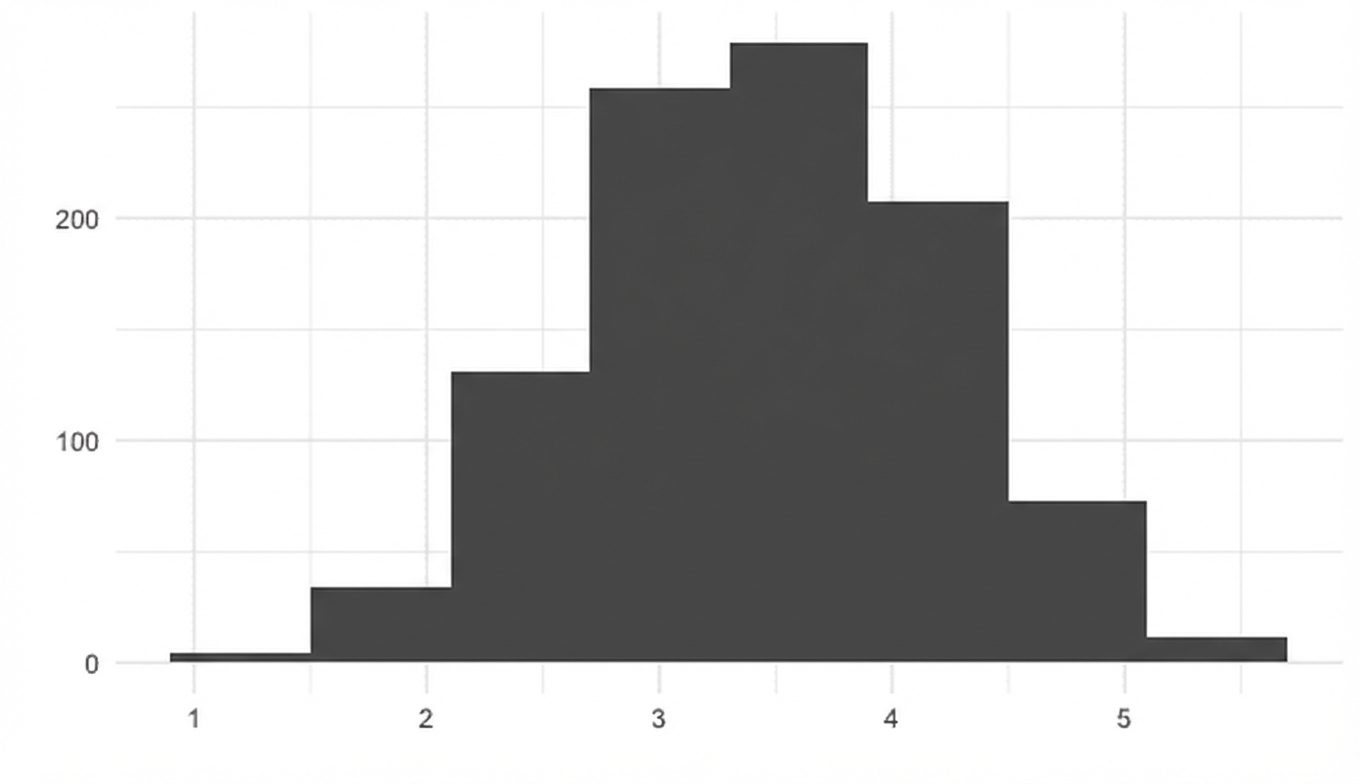
Centrale limietstelling
De steekproevenverdeling van een statistiek wordt met meer trekkingen steeds normaler.
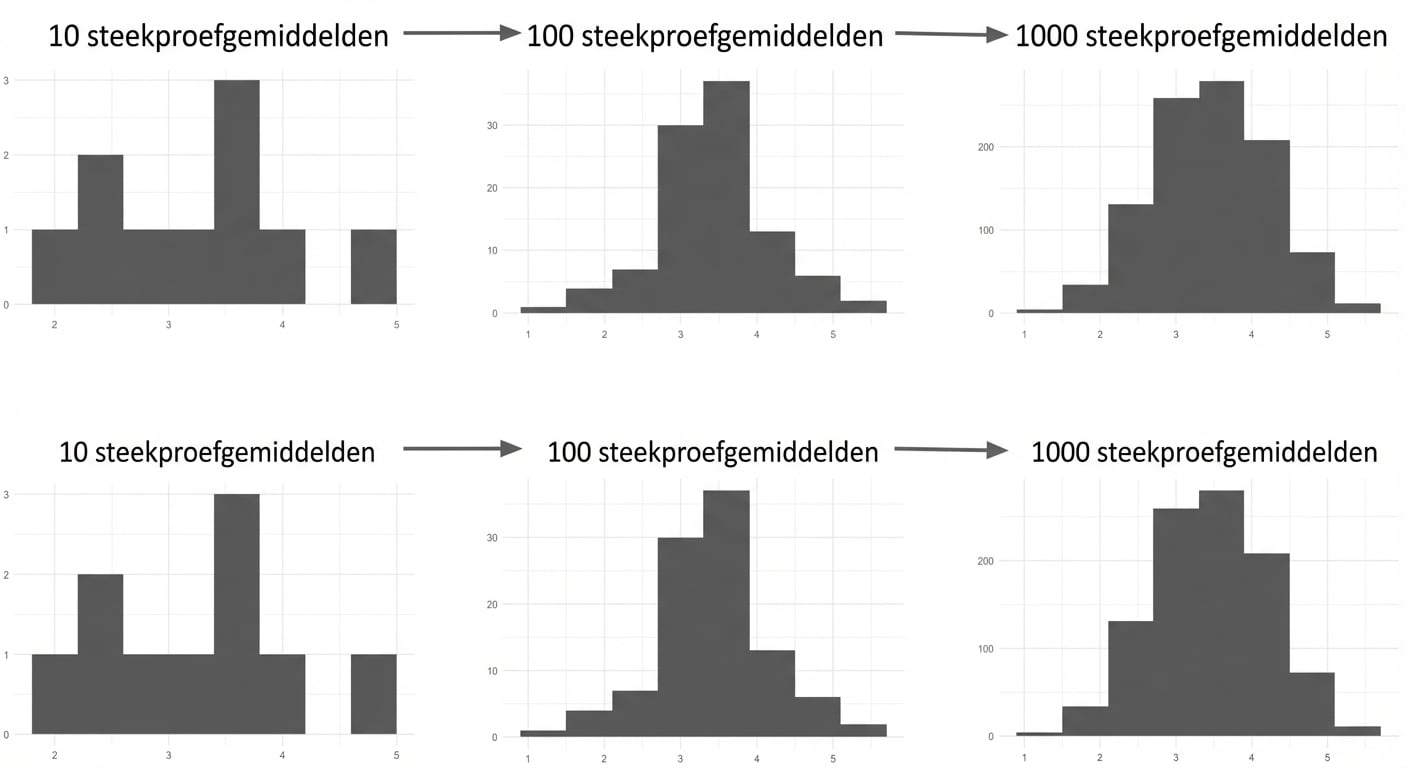
* Steekproeven moeten willekeurig en onafhankelijk zijn
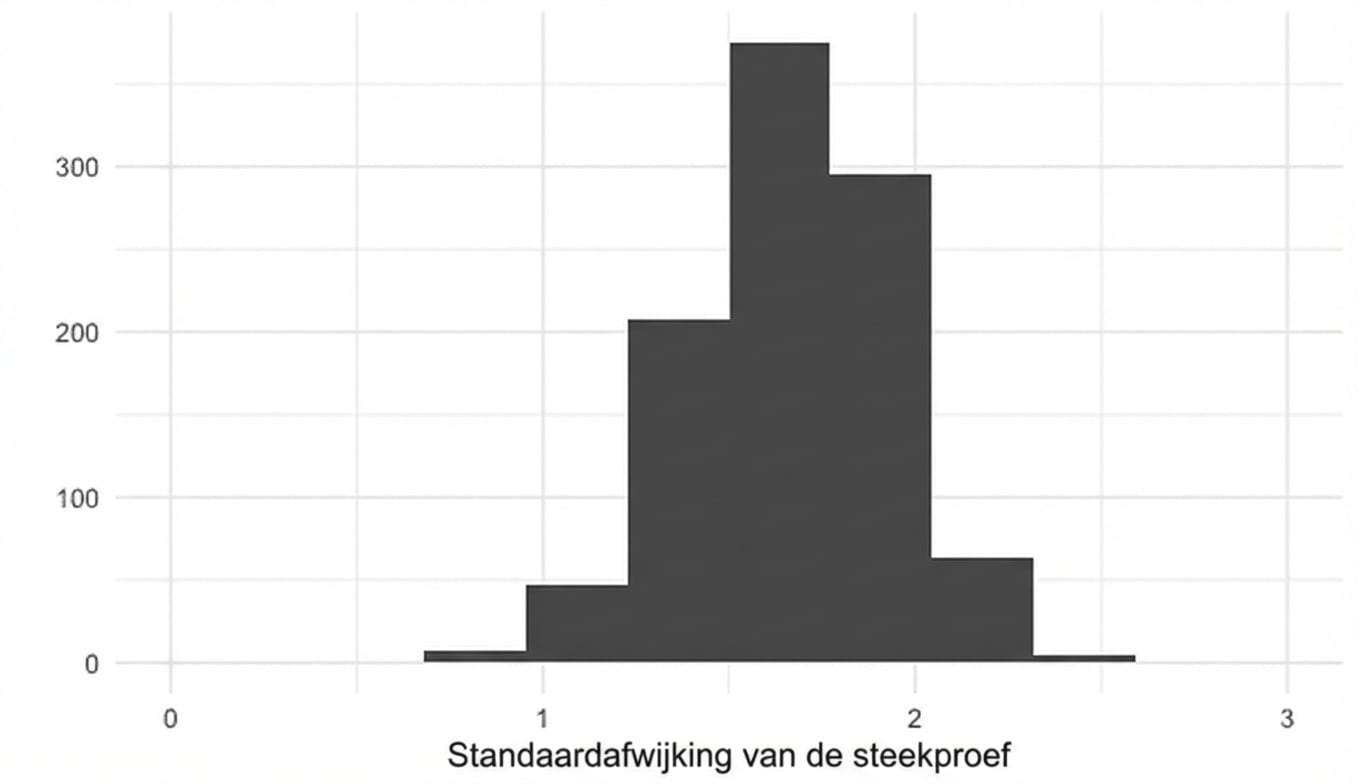
Standaarddeviatie en de CLT
replicate(1000, sample(die, 5, replace = TRUE) %>% sd())
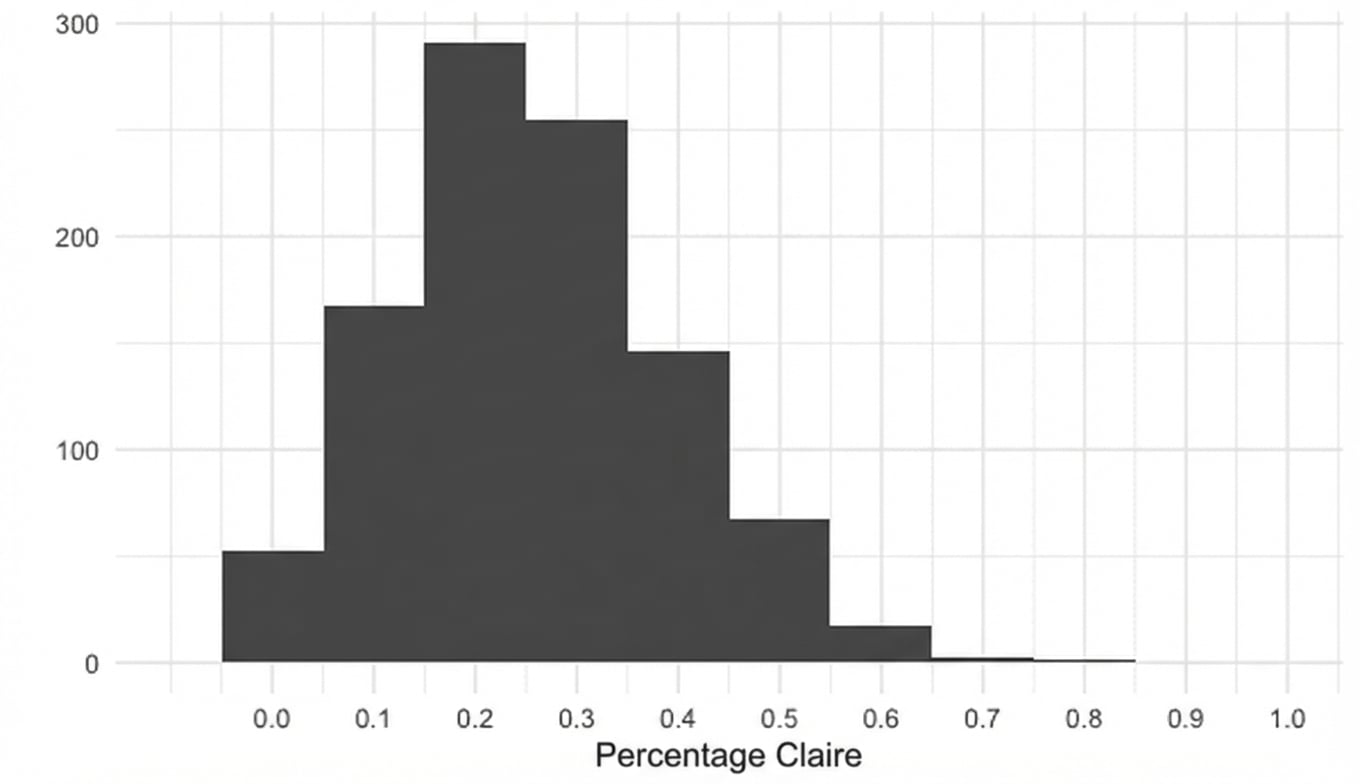
Steekproevenverdeling van proportie
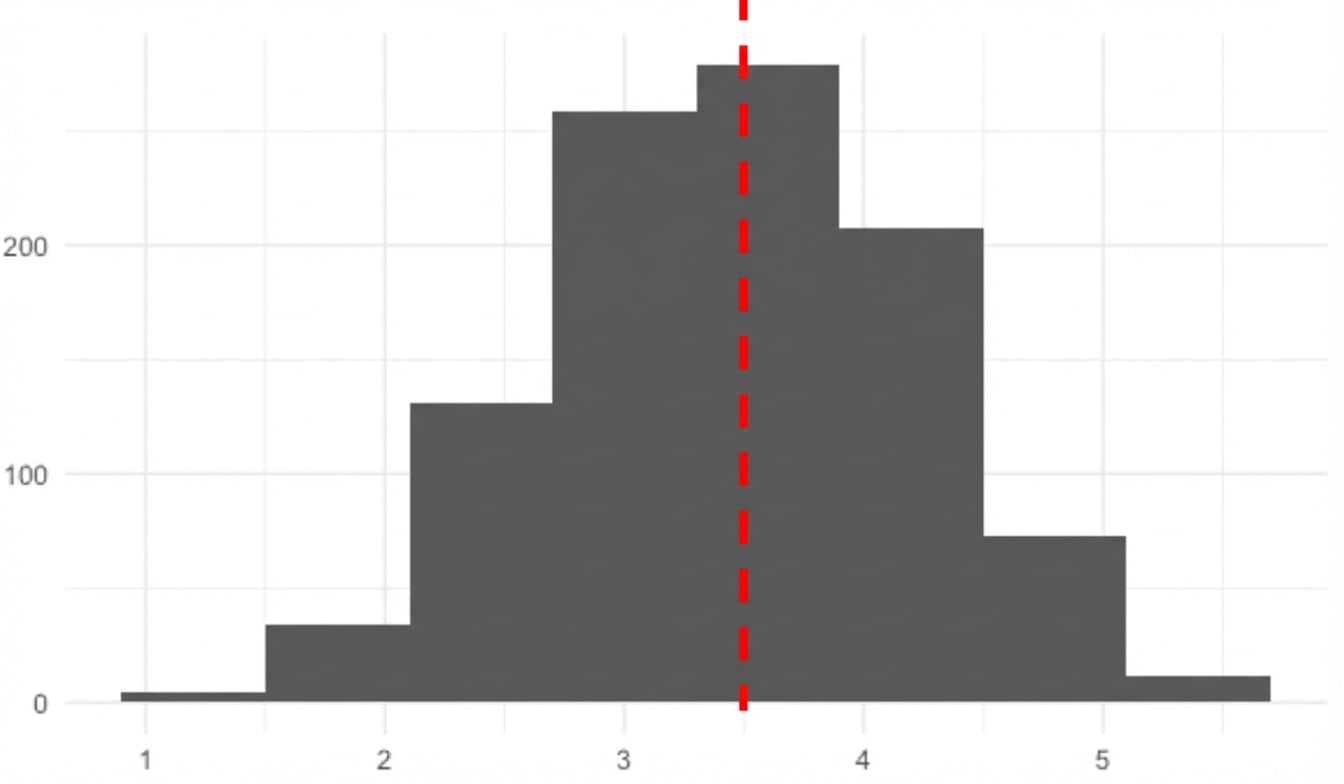
Gemiddelde van de steekproevenverdeling
- Kenmerken van grote populaties makkelijker schatten

