Metrieken voor taal: ROUGE, METEOR, EM
Introductie tot LLM’s in Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
LLM-taken en metriek
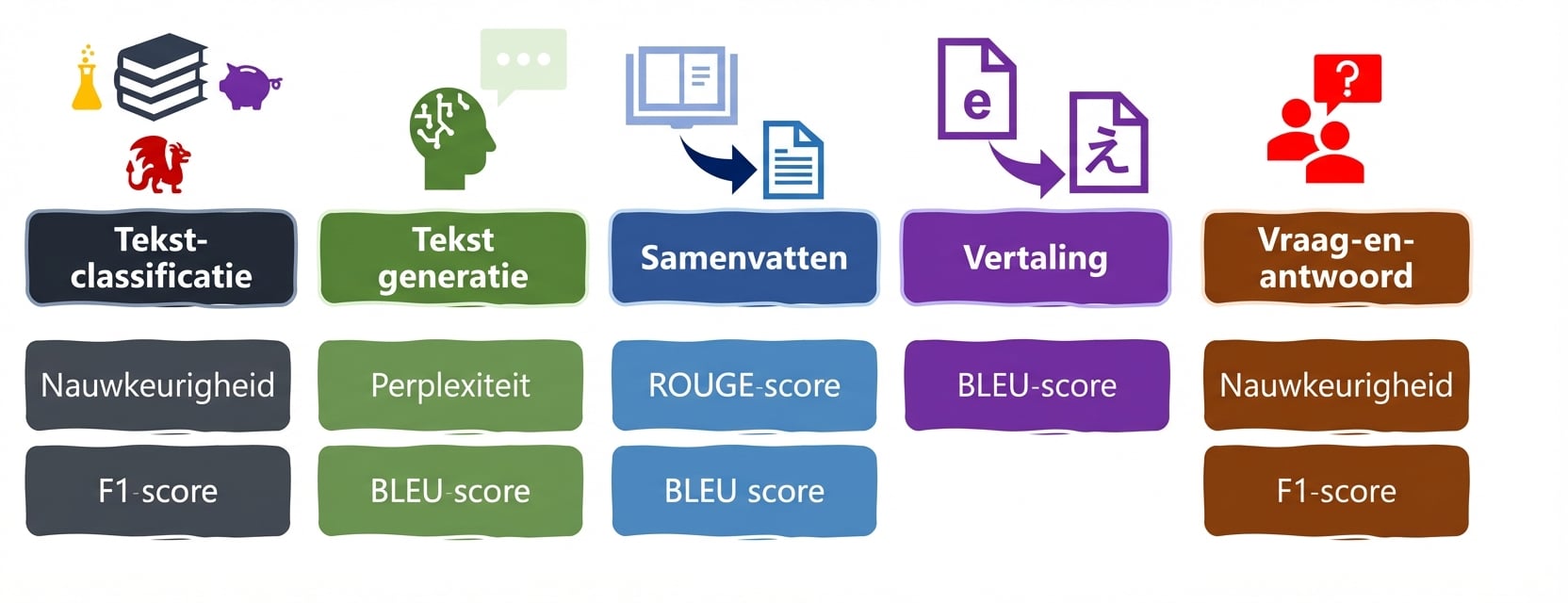
LLM-taken en metriek
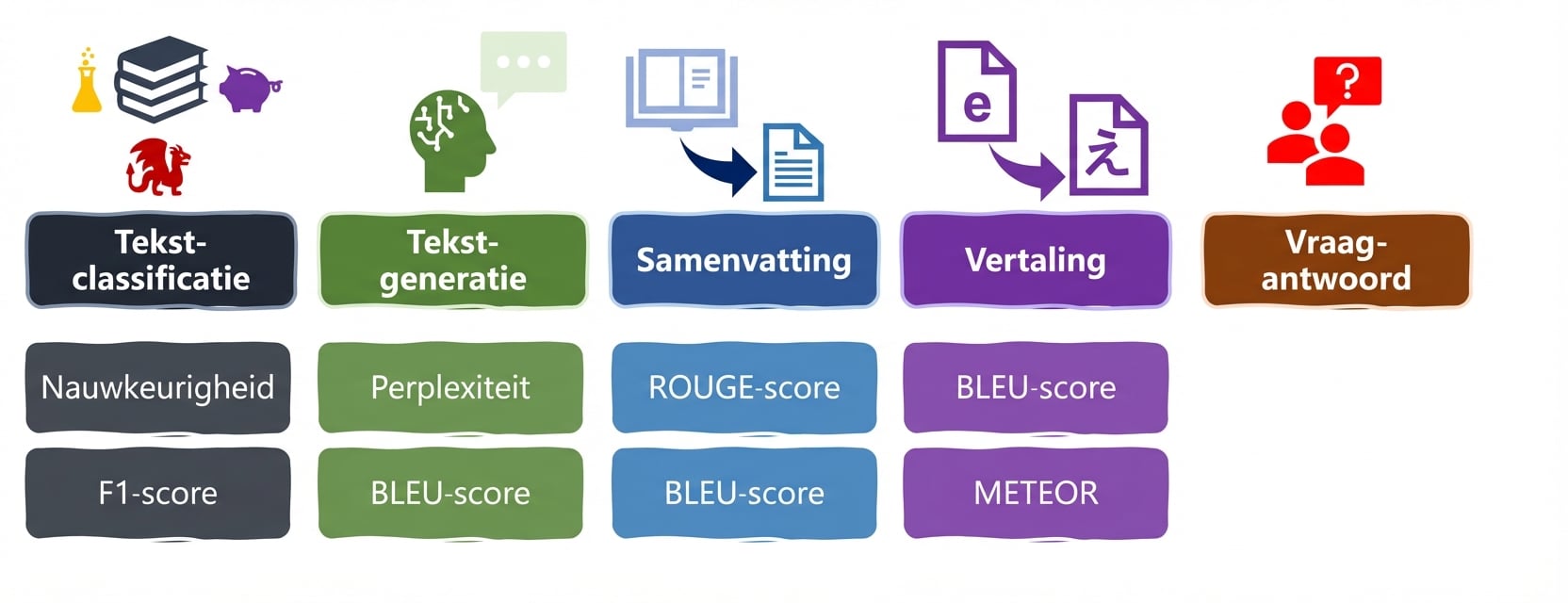
LLM-taken en metriek
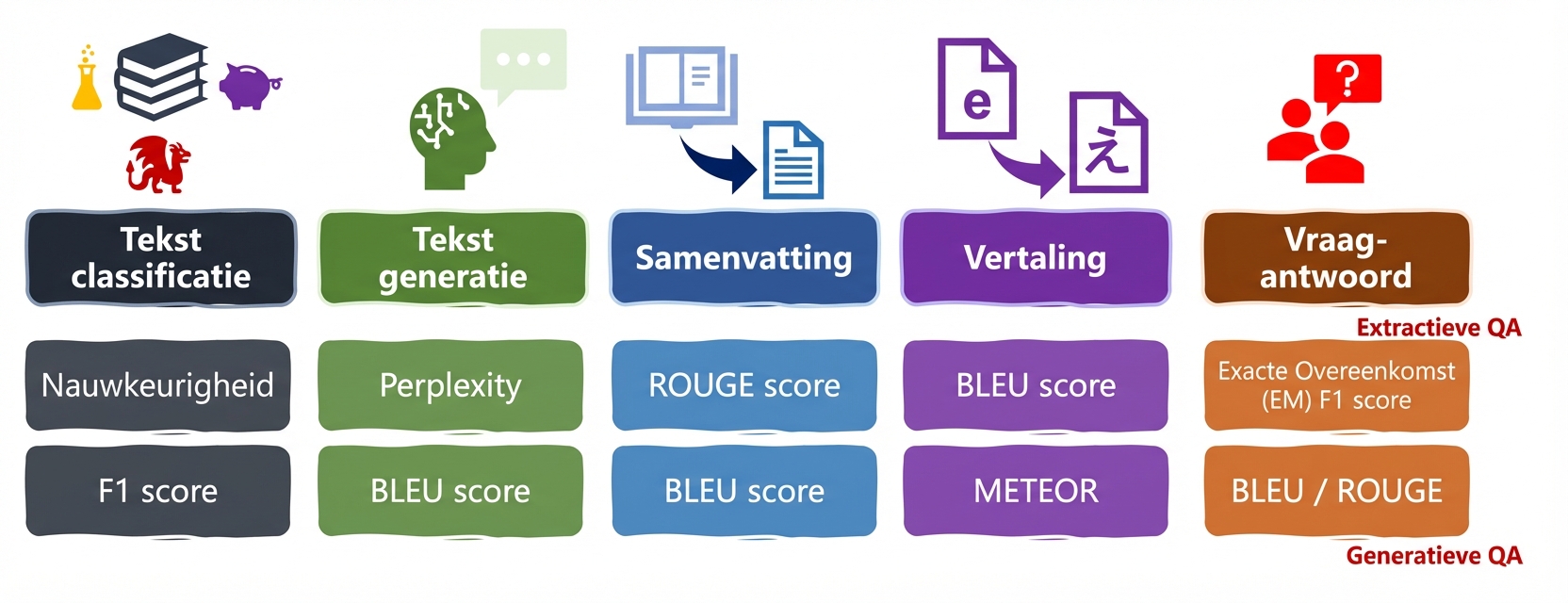
ROUGE
- ROUGE: overeenkomst tussen een gegenereerde samenvatting en referentiesamenvattingen
- Kijkt naar n-grams en overlap
predictions:LLM-uitvoerreferences: door mensen gemaakte samenvattingen

Vraag en antwoord

