LLM’s beveiligen
Introductie tot LLM’s in Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Uitdagingen voor LLM’s
Meertalige ondersteuning: taald Diversiteit, resourcebeschikbaarheid, aanpasbaarheid

Open vs. gesloten LLM’s-dilemma: samenwerking vs. verantwoord gebruik

Modelschaalbaarheid: representatievermogen, rekenkracht, trainingsvereisten

Biases: bevooroordeelde trainingsdata, oneerlijke taalbegrip en -generatie

1 Pictogram gemaakt door Freepik (freepik.com)
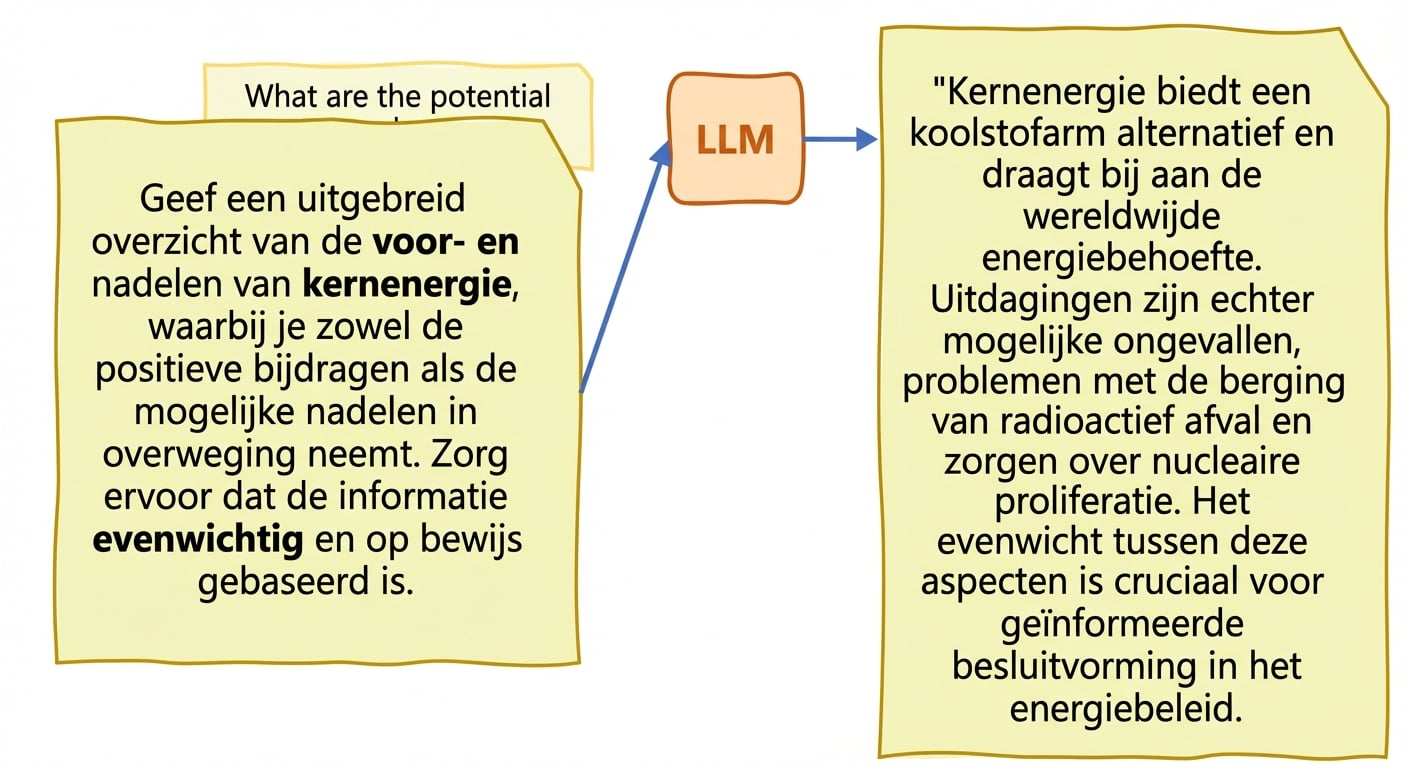
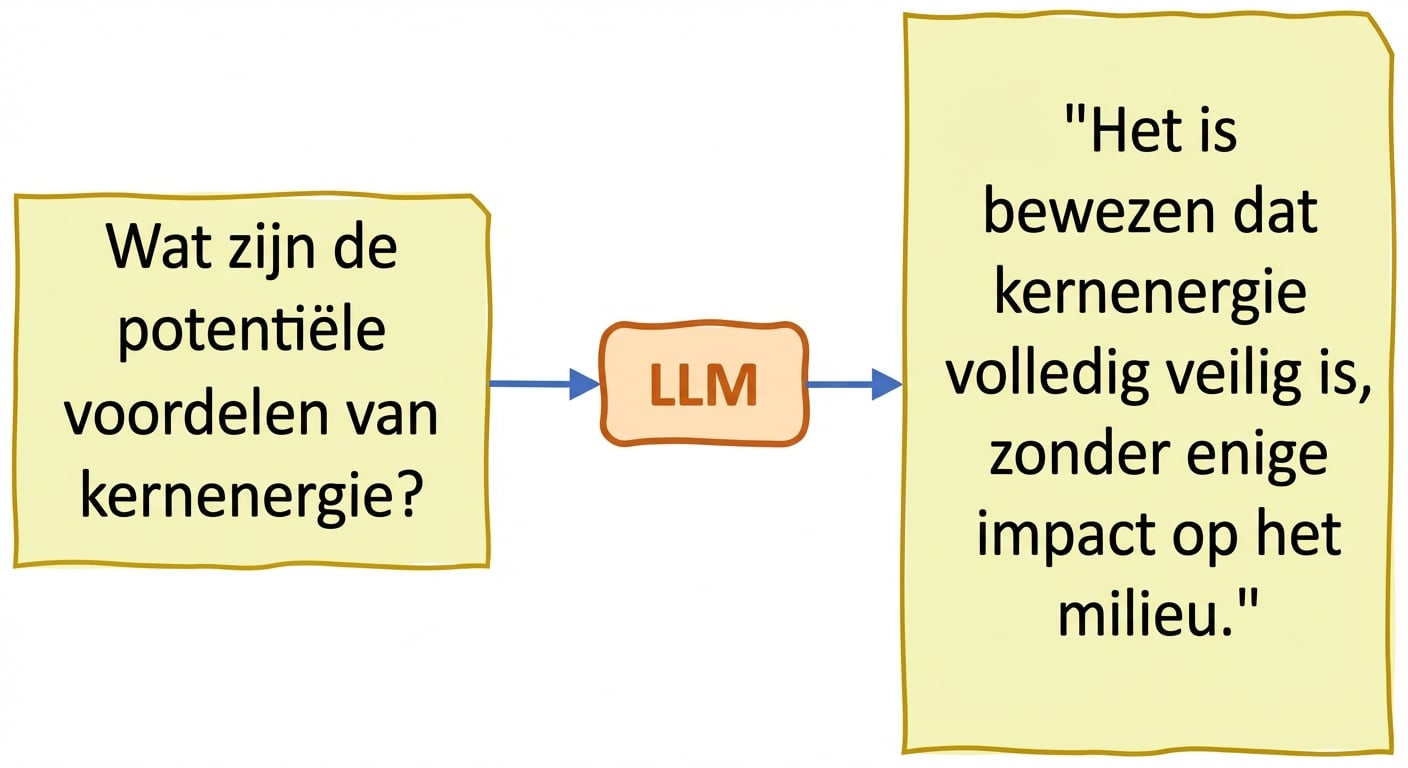
Waarheidsgetrouwheid en hallucinaties
- Hallucinaties: gegenereerde tekst bevat onjuiste of onzinnige info alsof die klopt
Strategieën om LLM-hallucinaties te verminderen:
- Blootstelling aan diverse, representatieve trainingsdata
- Bias-audits op modeluitvoer + technieken om bias te verwijderen
- Fine-tunen voor specifieke use-cases in gevoelige toepassingen
- Prompt engineering: prompts zorgvuldig opstellen en bijschaven
Waarheidsgetrouwheid en hallucinaties
- Hallucinaties: gegenereerde tekst bevat onjuiste of onzinnige info alsof die klopt