Voorbereiden op fine-tuning
Introductie tot LLM’s in Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Pipelines en auto-klassen
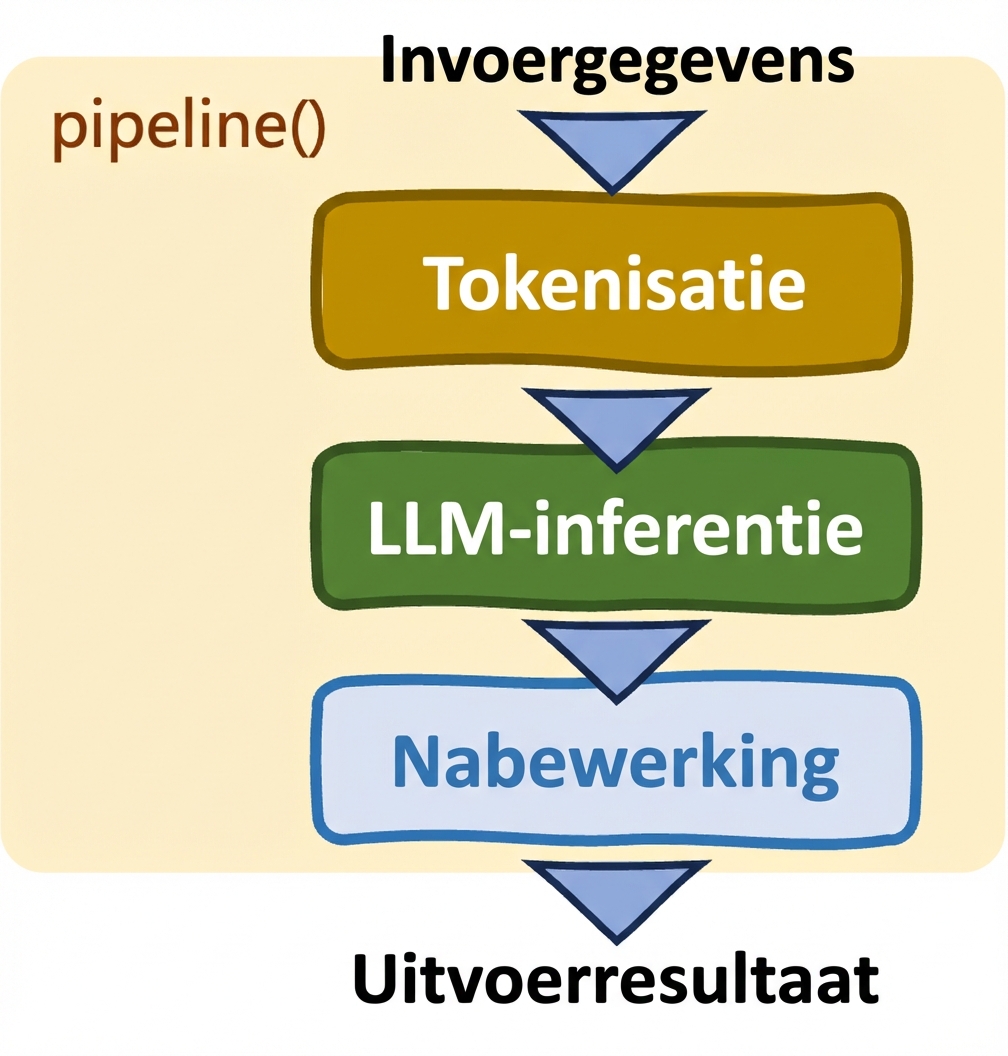
Pipelines: pipeline()
- Vereenvoudigt taken
- Automatische selectie van model en tokenizer
- Beperkte controle
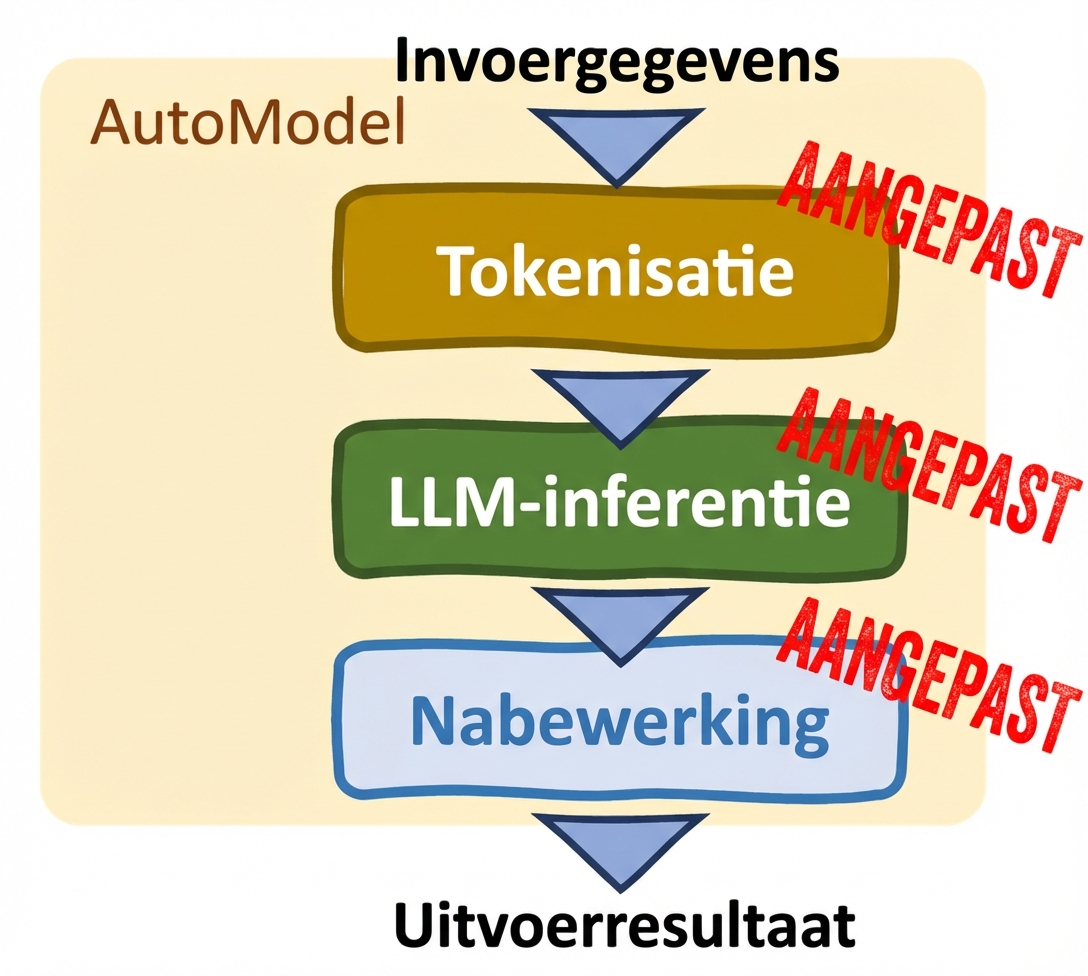
Auto-klassen (AutoModel class)
- Maatwerk
- Handmatige aanpassingen
- Ondersteunt fine-tuning
LLM-levenscyclus
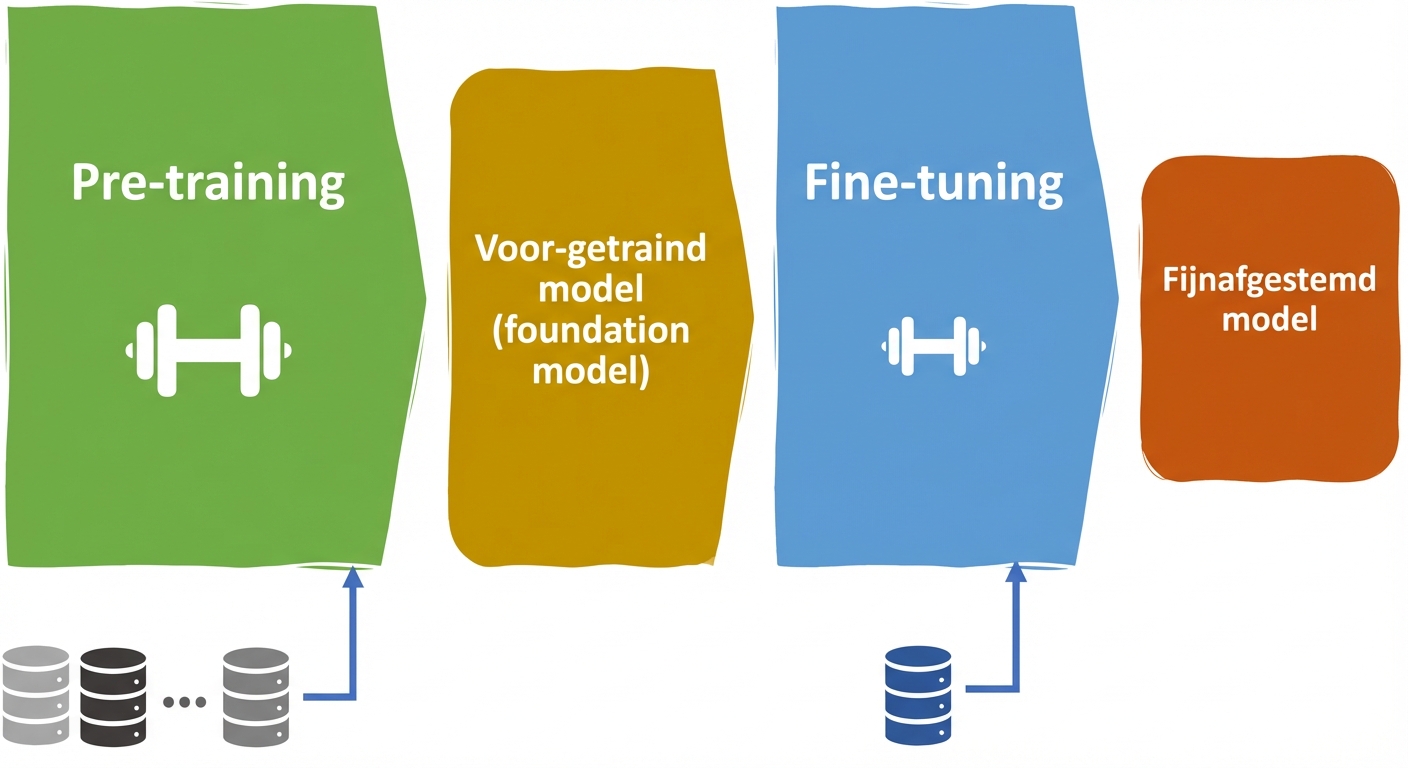
LLM-levenscyclus
Subwoord-tokenization
- Gangbaar in moderne tokenizers
- Woorden gesplitst in betekenisvolle subdelen

Subwoord-tokenization
- Gangbaar in moderne tokenizers
- Woorden gesplitst in betekenisvolle subdelen


