Web scrapen in Python
Gevorderd data importeren in Python

Hugo Bowne-Anderson
Data Scientist at DataCamp
HTML
Mix van ongestructureerde en gestructureerde data
Gestructureerde data:
Heeft een vooraf gedefinieerd datamodel, of
Is georganiseerd op een vaste manier
Ongestructureerde data: geen van beide
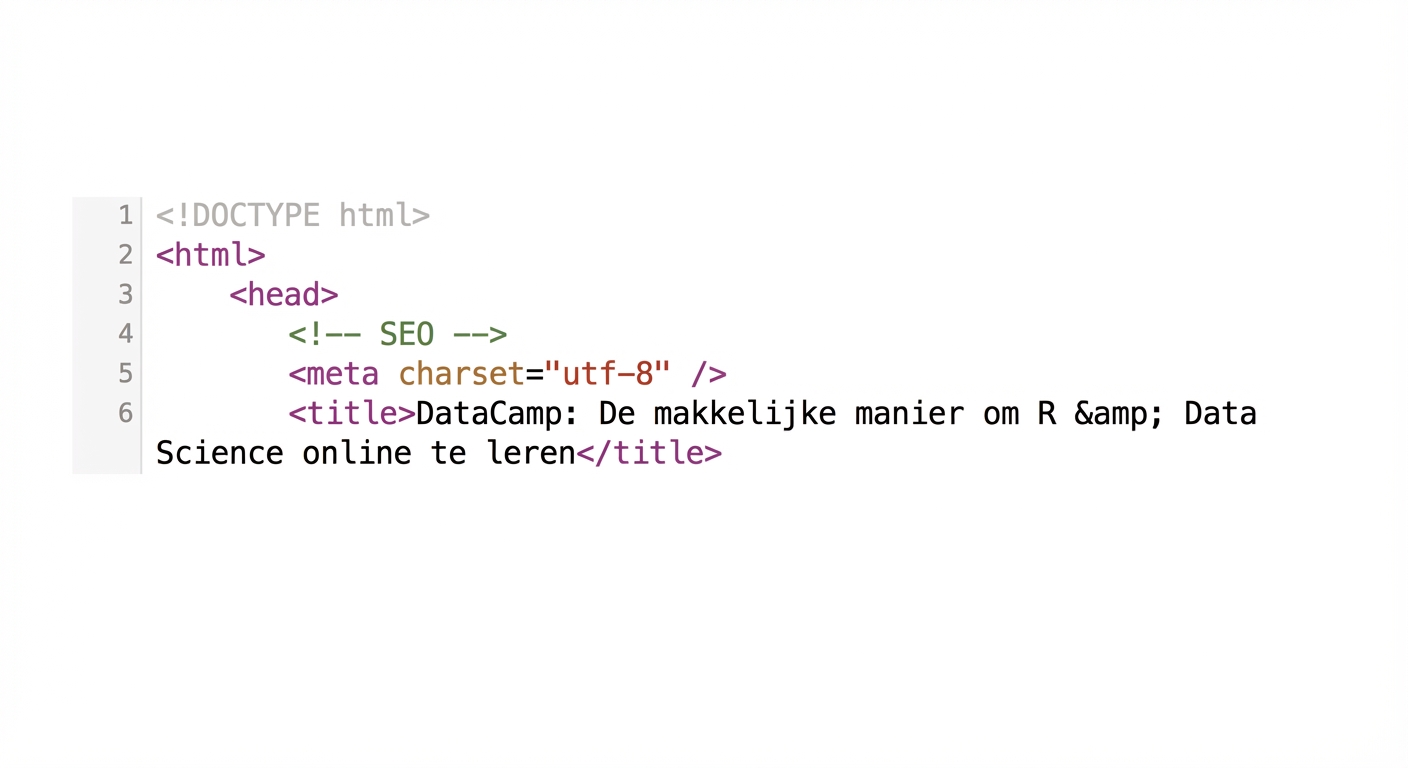
BeautifulSoup
- Parse en haal gestructureerde data uit HTML
- Maak tag-soep overzichtelijk en extraheer info

