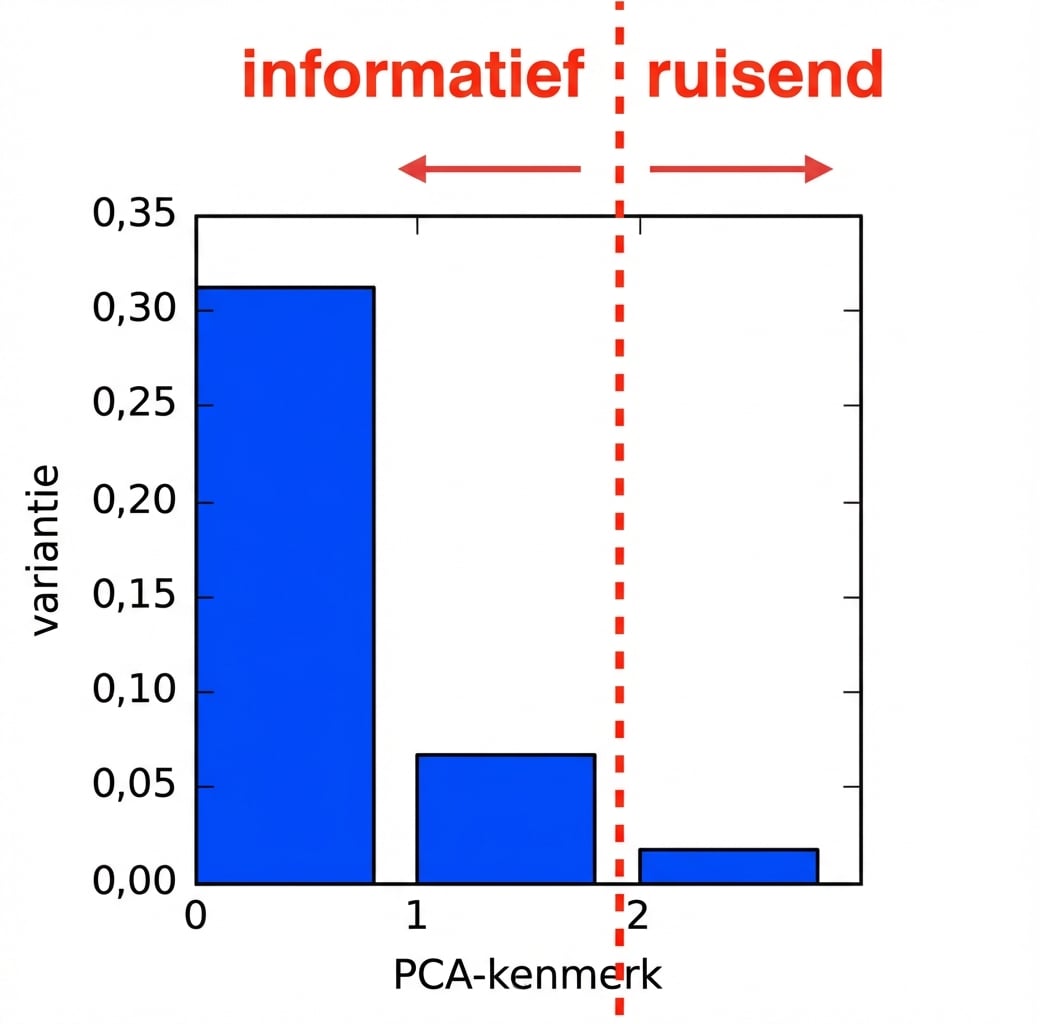
Dimensiereductie met PCA
Unsupervised Learning in Python

Benjamin Wilson
Director of Research at lateral.io
Dimensiereductie met PCA
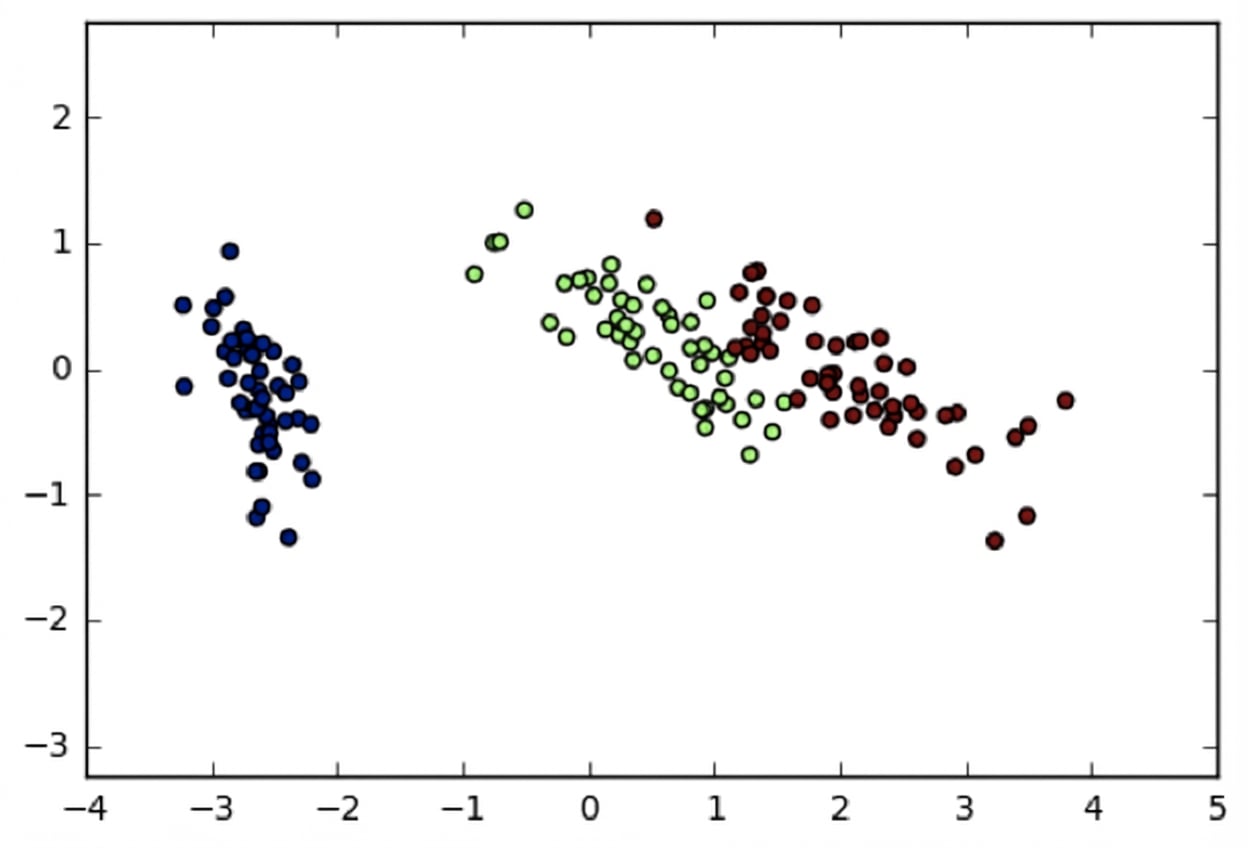
Iris-dataset in 2 dimensies
import matplotlib.pyplot as plt
xs = transformed[:,0]
ys = transformed[:,1]
plt.scatter(xs, ys, c=species)
plt.show()
Woordfrequentiematrices
- Rijen zijn documenten, kolommen woorden
- Waarden meten aanwezigheid van elk woord per document
- ... gemeten met "tf-idf" (later meer)

Sparse arrays en csr_matrix
- "Schaars": de meeste waarden zijn nul
- Gebruik
scipy.sparse.csr_matrixi.p.v. een NumPy-array csr_matrixbewaart alleen niet-nulwaarden (spaart ruimte!)

