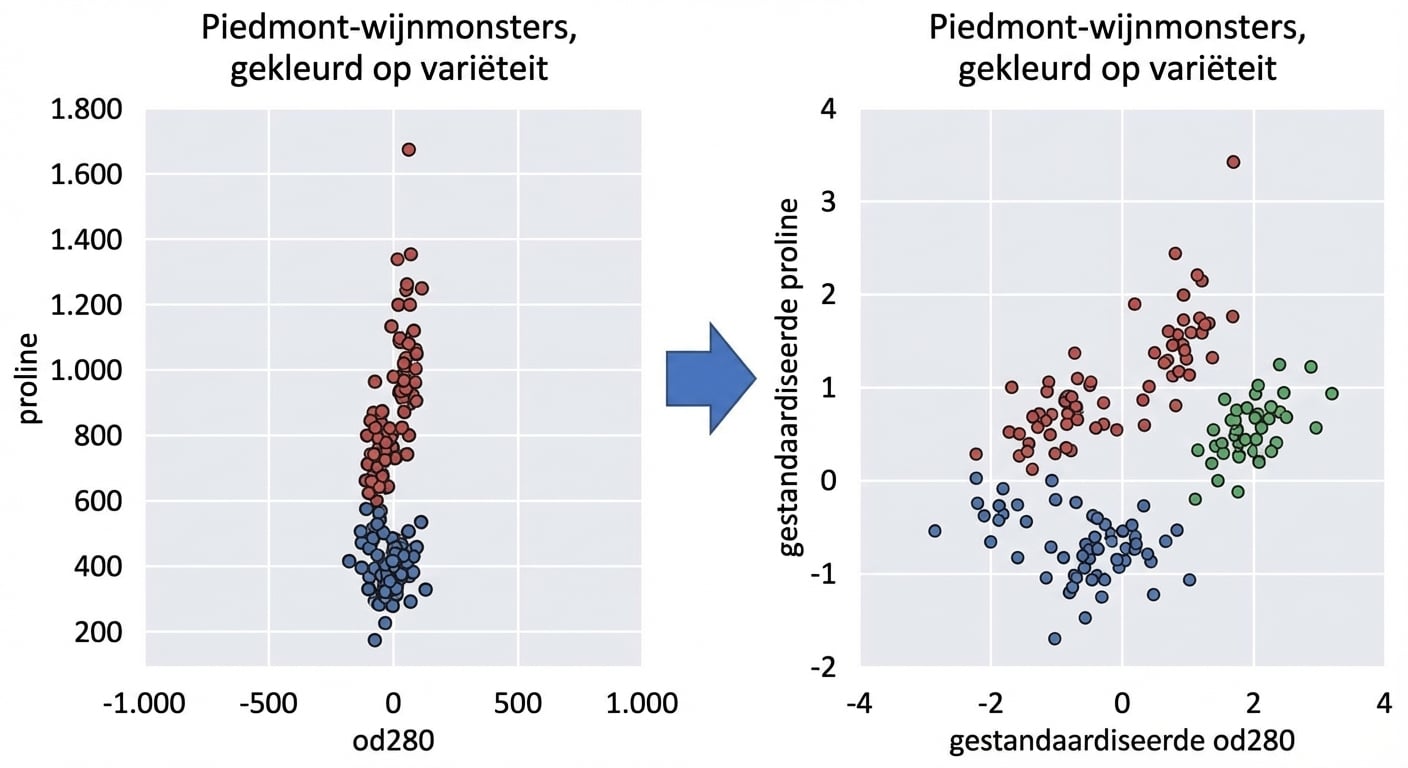
Features transformeren voor betere clustering
Unsupervised Learning in Python

Benjamin Wilson
Director of Research at lateral.io
Featurevarianties
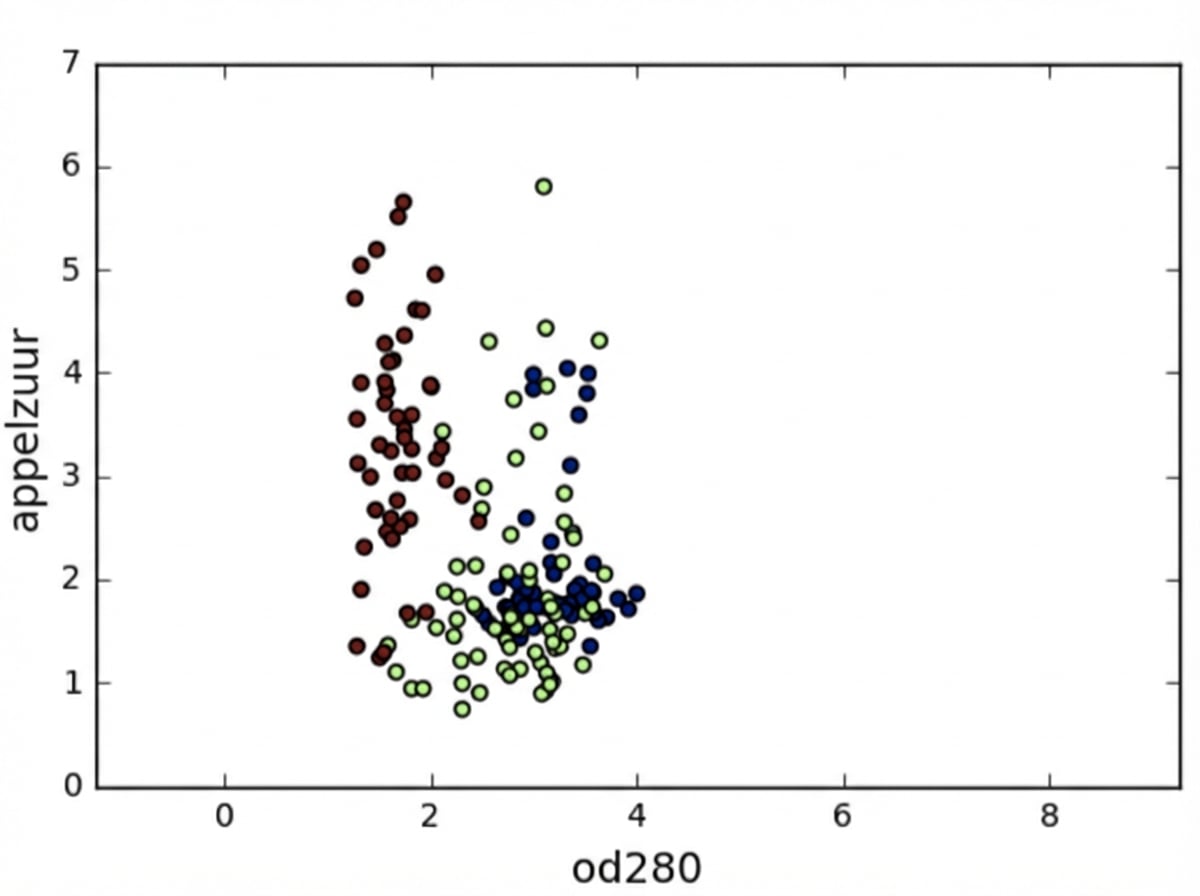
Featurevarianties
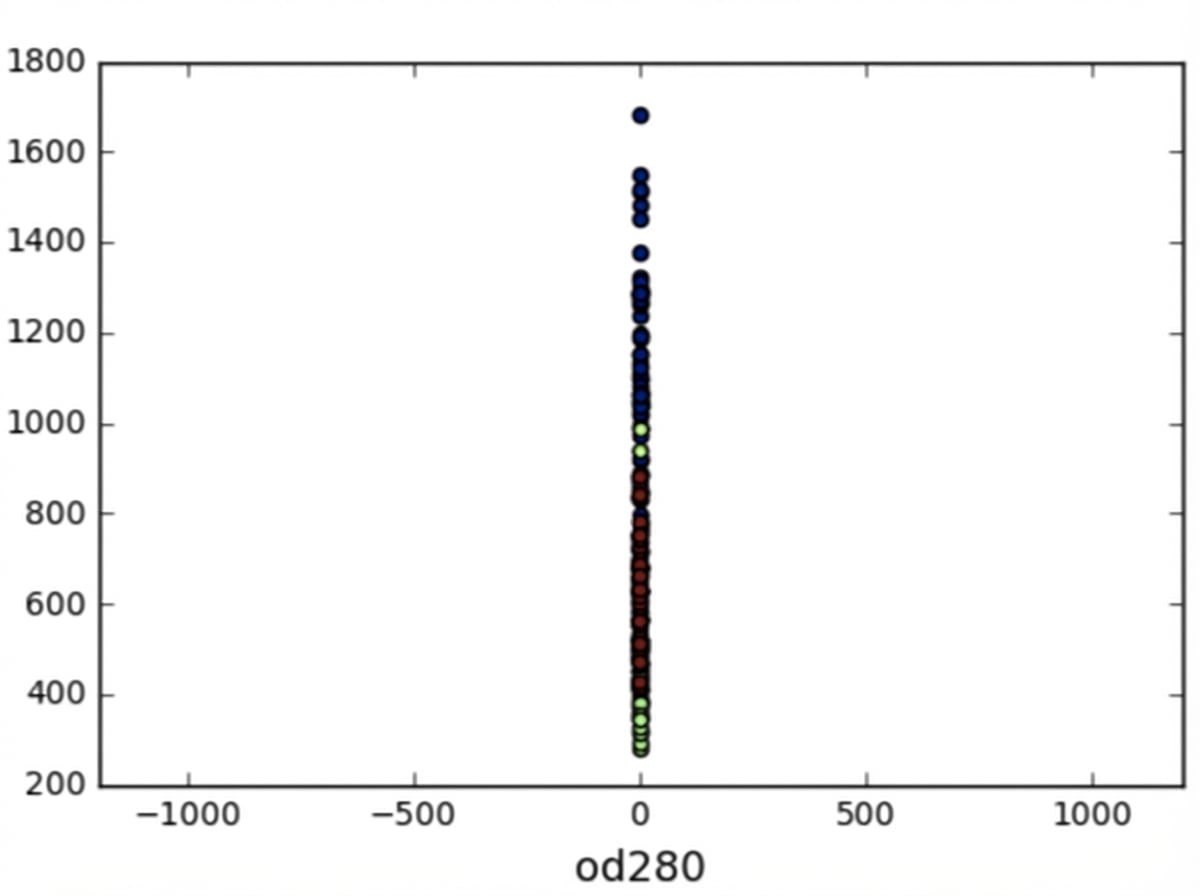
StandardScaler
In kmeans: featurevariantie = invloed van feature
StandardScalerzet elke feature om naar gemiddelde 0 en variantie 1Features zijn dan “gestandaardiseerd”