Bias- en variantieproblemen diagnosticeren
Machine Learning met boomgebaseerde modellen in Python

Elie Kawerk
Data Scientist
Generalisatiefout schatten
Hoe schatten we de generalisatiefout van een model?
Kan niet direct, want:
$f$ is onbekend,
je hebt meestal één dataset,
ruis is onvoorspelbaar.
Generalisatiefout schatten
Oplossing:
- splits de data in train- en testset,
- fit $\hat{f}$ op de trainingsset,
- evalueer de fout van $\hat{f}$ op de onbekende testset.
- generalisatiefout van $\hat{f} \approx$ testfout van $\hat{f}$.
Betere modelevaluatie met cross-validation
Raak de testset pas aan als je zeker bent van $\hat{f}$’s prestaties.
Evalueren op de trainingsset: bevooroordeelde schatting; $\hat{f}$ heeft alle trainingspunten al gezien.
Oplossing $\rightarrow$ Cross-validation (CV):
K-fold CV,
Hold-out CV.
K-fold CV
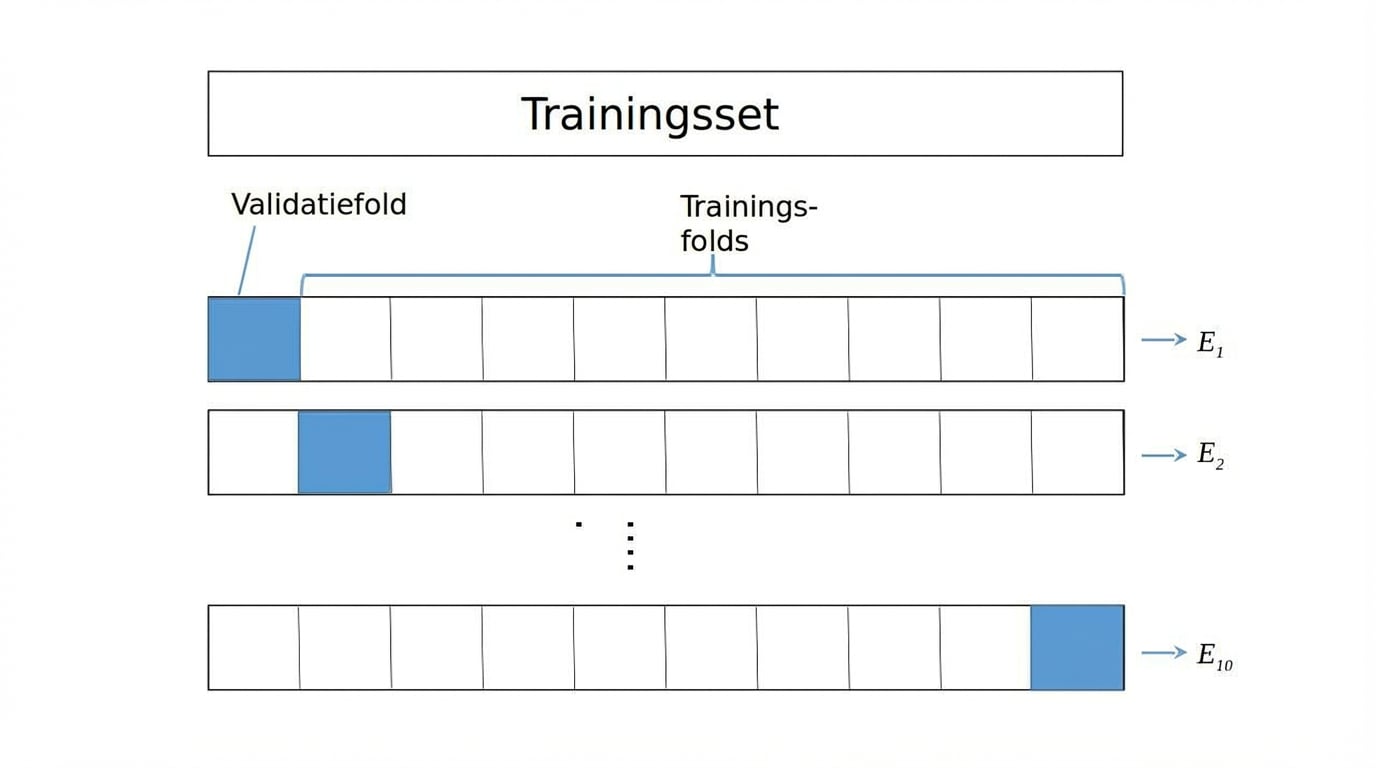
K-fold CV
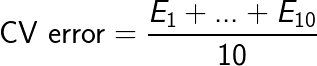
Variantieproblemen diagnosticeren
Als $\hat{f}$ last heeft van hoge variantie:
CV-fout van $\hat{f}$ > trainingsfout van $\hat{f}$.
- $\hat{f}$ overfit op de trainingsset. Aanpak overfitting:
- verlaag modelcomplexiteit,
- bv.: verlaag max diepte, verhoog min samples per leaf, ...
- verzamel meer data, ..
Biasproblemen diagnosticeren
Als $\hat{f}$ last heeft van hoge bias:
CV-fout van $\hat{f} \approx$ trainingsfout van $\hat{f} >>$ gewenste fout.
$\hat{f}$ underfit op de trainingsset. Aanpak underfitting:
- verhoog modelcomplexiteit
- bv.: verhoog max diepte, verlaag min samples per leaf, ...
- verzamel relevantere features
K-fold CV in sklearn op de Auto-dataset
from sklearn.tree import DecisionTreeRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error as MSE from sklearn.model_selection import cross_val_score# Set seed for reproducibility SEED = 123 # Split data into 70% train and 30% test X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=SEED)# Instantiate decision tree regressor and assign it to 'dt' dt = DecisionTreeRegressor(max_depth=4, min_samples_leaf=0.14, random_state=SEED)
K-fold CV in sklearn op de Auto-dataset
# Evalueer de lijst met MSE verkregen via 10-fold CV # Zet n_jobs op -1 om alle CPU-cores te gebruiken MSE_CV = - cross_val_score(dt, X_train, y_train, cv= 10, scoring='neg_mean_squared_error', n_jobs = -1)# Fit 'dt' op de trainingsset dt.fit(X_train, y_train) # Voorspel labels van de trainingsset y_predict_train = dt.predict(X_train) # Voorspel labels van de testset y_predict_test = dt.predict(X_test)
# CV MSE
print('CV MSE: {:.2f}'.format(MSE_CV.mean()))
CV MSE: 20.51
# Training MSE
print('Train MSE: {:.2f}'.format(MSE(y_train, y_predict_train)))
Train MSE: 15.30
# Test MSE
print('Test MSE: {:.2f}'.format(MSE(y_test, y_predict_test)))
Test MSE: 20.92
Laten we oefenen!
Machine Learning met boomgebaseerde modellen in Python

