Machine Learning met boomgebaseerde modellen in Python
Elie Kawerk
Data Scientist
Gradient Boosting: Nadelen
GB gebruikt een uitputtende zoekprocedure.
Elke CART wordt getraind om de beste splits en features te vinden.
Kan leiden tot CART's met dezelfde splits en mogelijk dezelfde features.
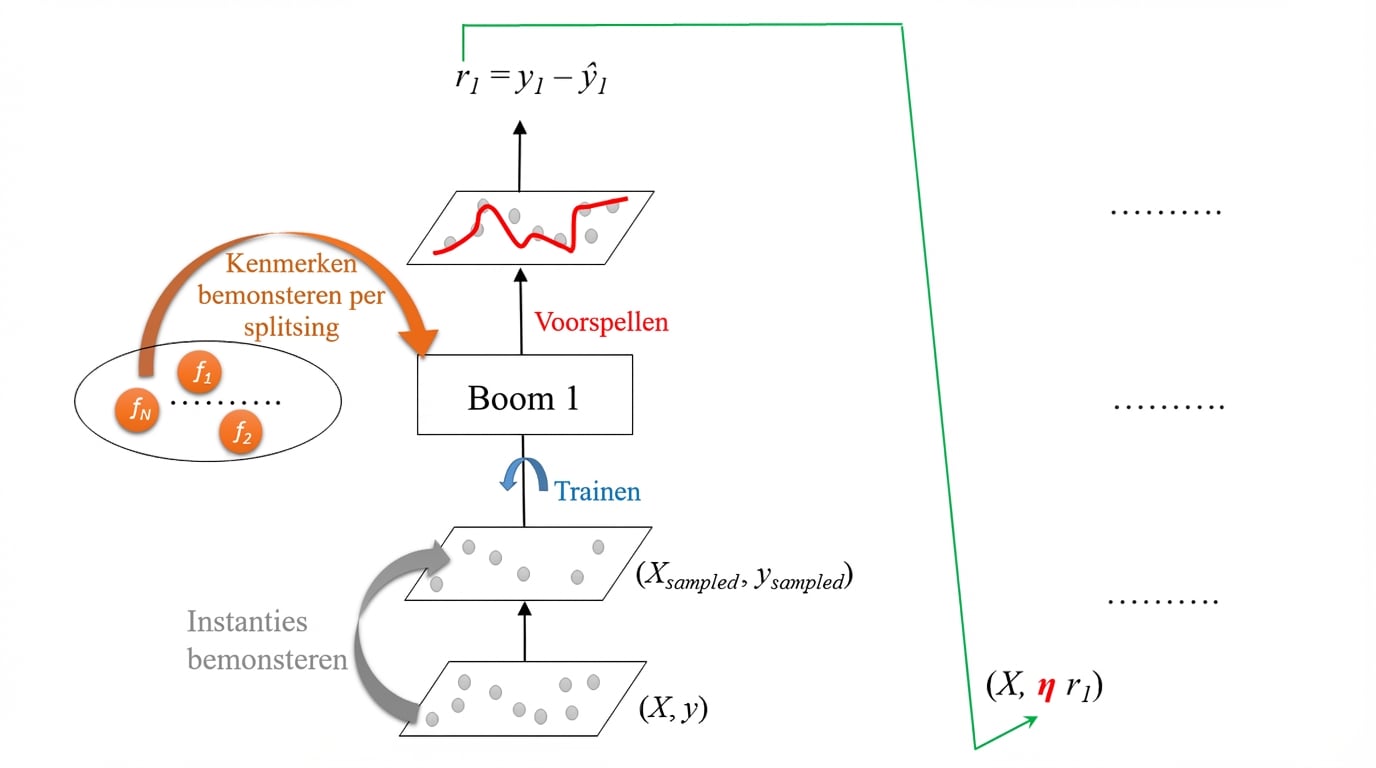
Stochastic Gradient Boosting
Elke tree wordt getraind op een willekeurige subset rijen van de trainingsdata.
De steekproef (40%-80% van de trainingsset) gebeurt zonder terugleggen.
Features worden (zonder terugleggen) bemonsterd bij het kiezen van splits.
Resultaat: extra diversiteit in de ensemble.
Effect: meer variantie in de boom-ensemble.
Stochastic Gradient Boosting: Training
Stochastic Gradient Boosting in sklearn (auto-dataset)
# Import models and utility functions
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MSE
# Set seed for reproducibility
SEED = 1
# Split dataset into 70% train and 30% test
X_train, X_test, y_train, y_test = train_test_split(X,y,
test_size=0.3,
random_state=SEED)
Stochastic Gradient Boosting in sklearn (auto-dataset)
# Instantiate a stochastic GradientBoostingRegressor 'sgbt'
sgbt = GradientBoostingRegressor(max_depth=1,
subsample=0.8,
max_features=0.2,
n_estimators=300,
random_state=SEED)
# Fit 'sgbt' to the training set
sgbt.fit(X_train, y_train)
# Predict the test set labels
y_pred = sgbt.predict(X_test)
Stochastic Gradient Boosting in sklearn (auto-dataset)
# Evaluate test set RMSE 'rmse_test'
rmse_test = MSE(y_test, y_pred)**(1/2)
# Print 'rmse_test'
print('Test set RMSE: {:.2f}'.format(rmse_test))
Test set RMSE: 3.95
Laten we oefenen!
Machine Learning met boomgebaseerde modellen in Python