Random forests
Machine Learning met boomgebaseerde modellen in Python

Elie Kawerk
Data Scientist
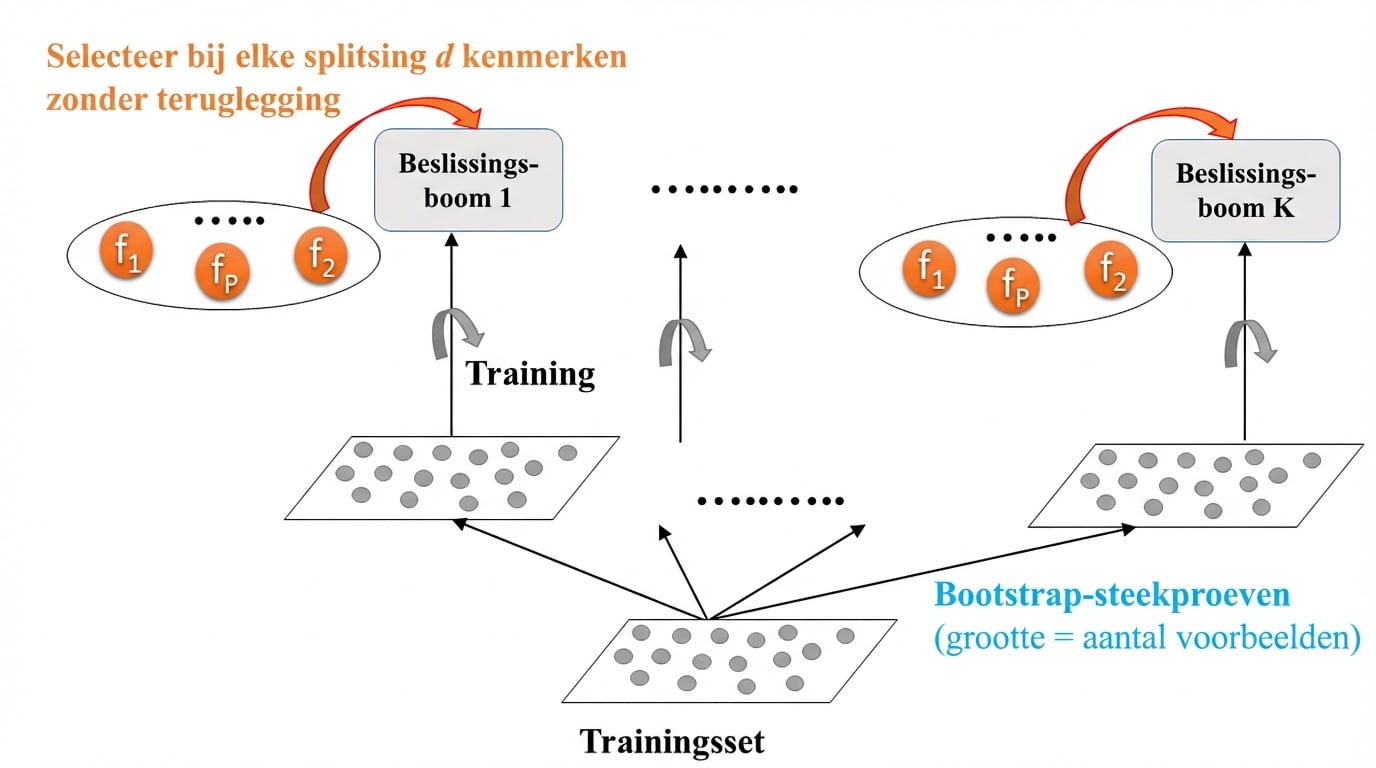
Random forests: training
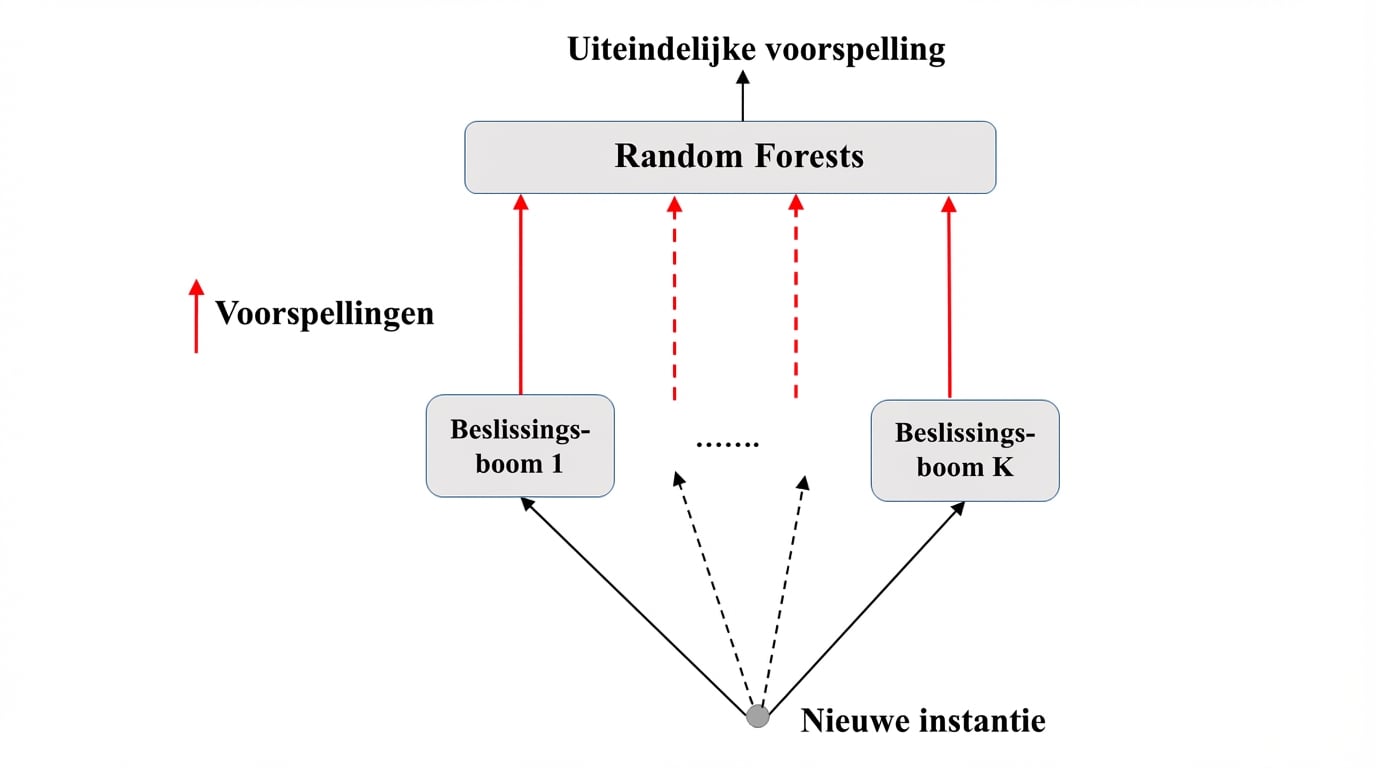
Random forests: predictie
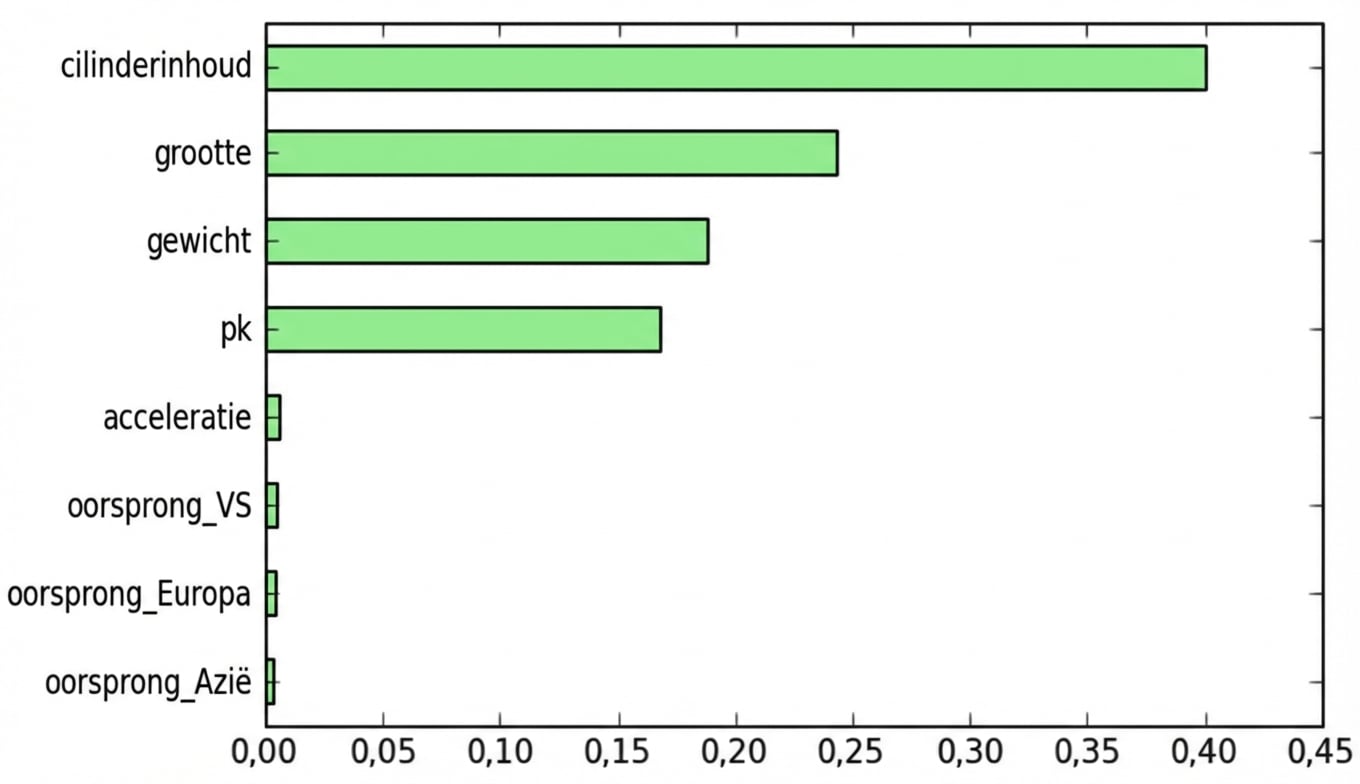
Feature-importance in sklearn
Machine Learning met boomgebaseerde modellen in Python
Elie Kawerk
Data Scientist

