Ensemble learning
Machine Learning met boomgebaseerde modellen in Python

Elie Kawerk
Data Scientist
Voordelen van CART's
Eenvoudig te begrijpen.
Eenvoudig te interpreteren.
Makkelijk te gebruiken.
Flexibel: kan niet-lineaire verbanden modelleren.
Voorbewerking: features niet standaardiseren of normaliseren, …
Beperkingen van CART's
Classificatie: produceert alleen orthogonale beslissingsgrenzen.
Gevoelig voor kleine variaties in de trainingsset.
Hoge variantie: onbegrensde CART's kunnen overfitten.
Oplossing: ensemble learning.
Ensemble learning
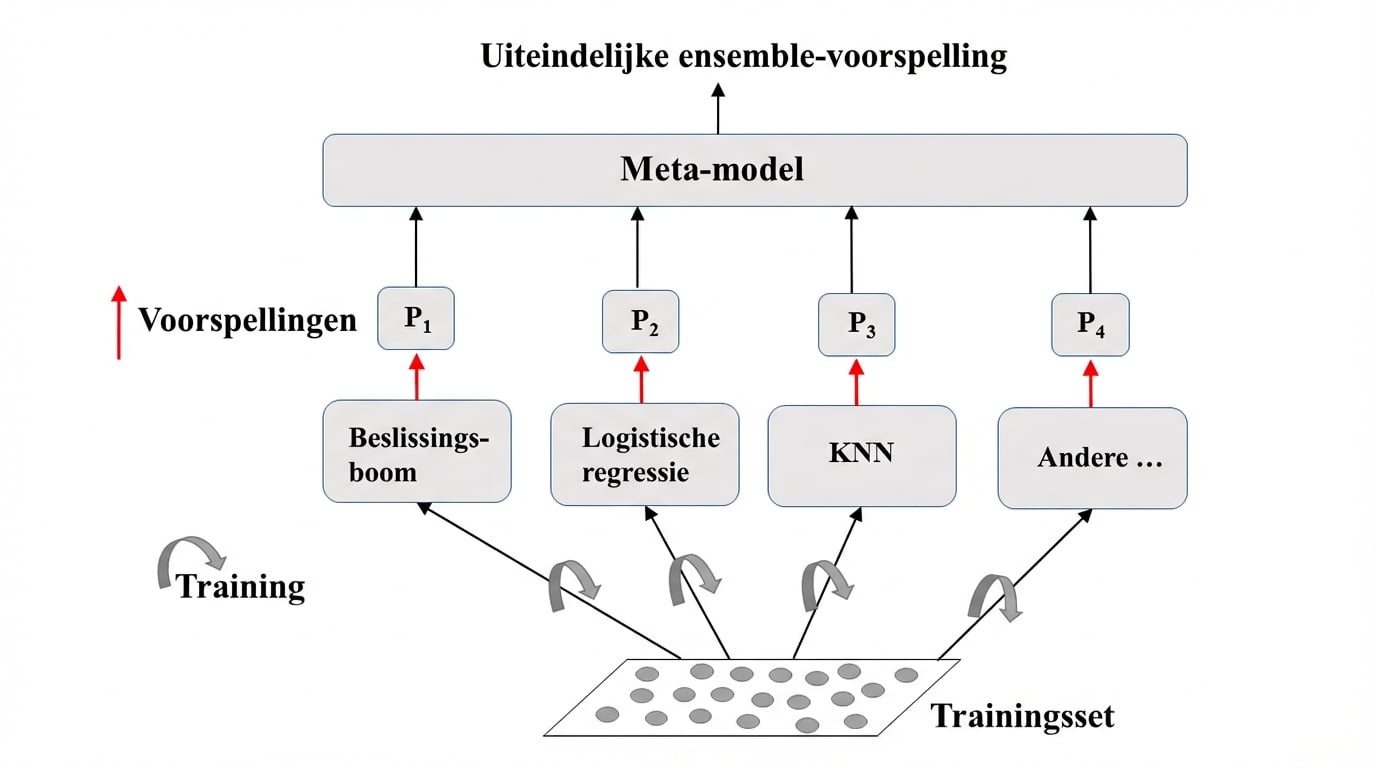
Train verschillende modellen op dezelfde dataset.
Laat elk model voorspellen.
Meta-model: voegt voorspellingen van modellen samen.
Eindvoorspelling: robuuster en minder foutgevoelig.
Beste resultaat: modellen hebben verschillende sterke punten.
Ensemble learning: visuele uitleg
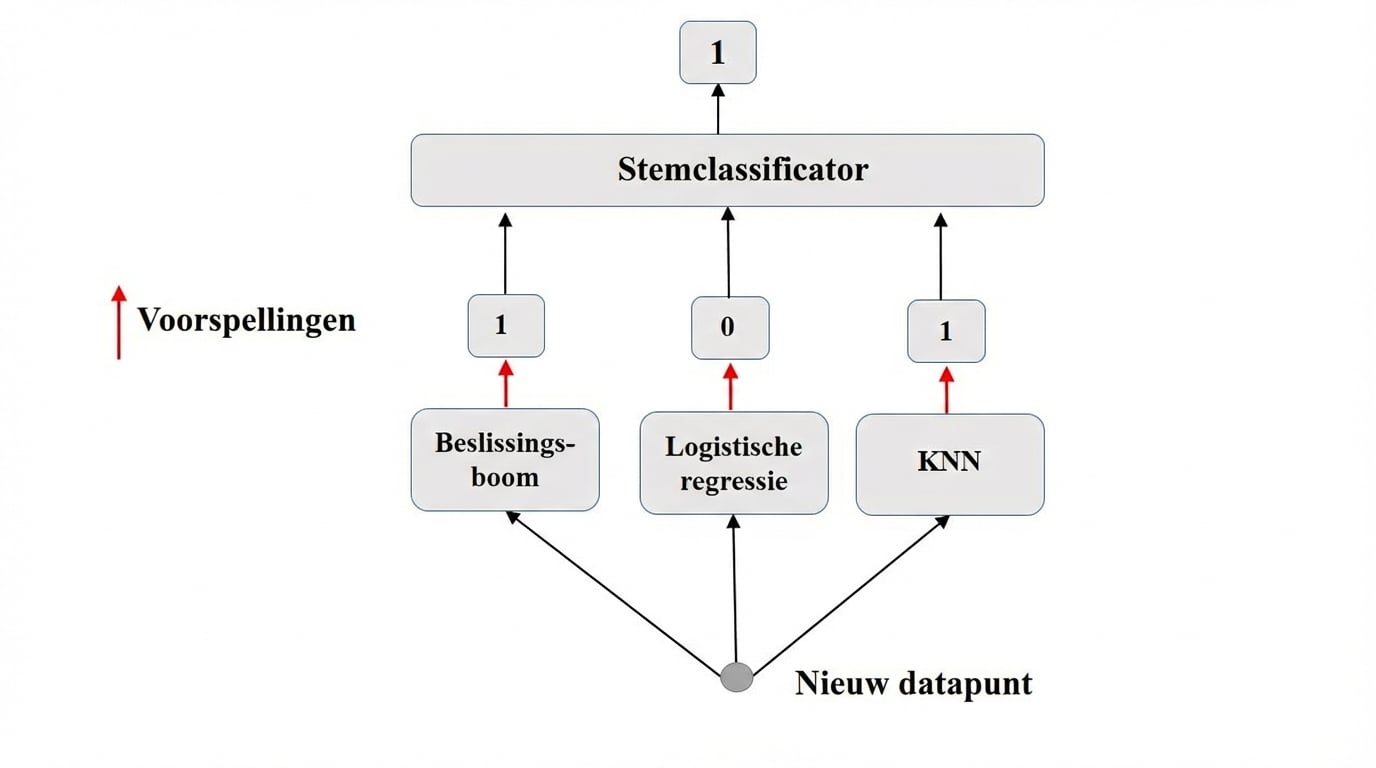
Ensemble in de praktijk: VotingClassifier
Binaire classificatie.
$N$ classifiers doen voorspellingen: $P_1$, $P_2$, ..., $P_N$ met $P_i$ = 0 of 1.
Voorspelling meta-model: hard voting.
Hard voting
VotingClassifier in sklearn (Breast-Cancer dataset)
# Import functions to compute accuracy and split data
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# Import models, including VotingClassifier meta-model
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.ensemble import VotingClassifier
# Set seed for reproducibility
SEED = 1
VotingClassifier in sklearn (Breast-Cancer dataset)
# Split data into 70% train and 30% test X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.3, random_state= SEED) # Instantiate individual classifiers lr = LogisticRegression(random_state=SEED) knn = KNN() dt = DecisionTreeClassifier(random_state=SEED)# Define a list called classifier that contains the tuples (classifier_name, classifier) classifiers = [('Logistic Regression', lr), ('K Nearest Neighbours', knn), ('Classification Tree', dt)]
# Iterate over the defined list of tuples containing the classifiers
for clf_name, clf in classifiers:
#fit clf to the training set
clf.fit(X_train, y_train)
# Predict the labels of the test set
y_pred = clf.predict(X_test)
# Evaluate the accuracy of clf on the test set
print('{:s} : {:.3f}'.format(clf_name, accuracy_score(y_test, y_pred)))
Logistic Regression: 0.947
K Nearest Neighbours: 0.930
Classification Tree: 0.930
VotingClassifier in sklearn (Breast-Cancer dataset)
# Instantiate a VotingClassifier 'vc'
vc = VotingClassifier(estimators=classifiers)
# Fit 'vc' to the traing set and predict test set labels
vc.fit(X_train, y_train)
y_pred = vc.predict(X_test)
# Evaluate the test-set accuracy of 'vc'
print('Voting Classifier: {.3f}'.format(accuracy_score(y_test, y_pred)))
Voting Classifier: 0.953
Laten we oefenen!
Machine Learning met boomgebaseerde modellen in Python

