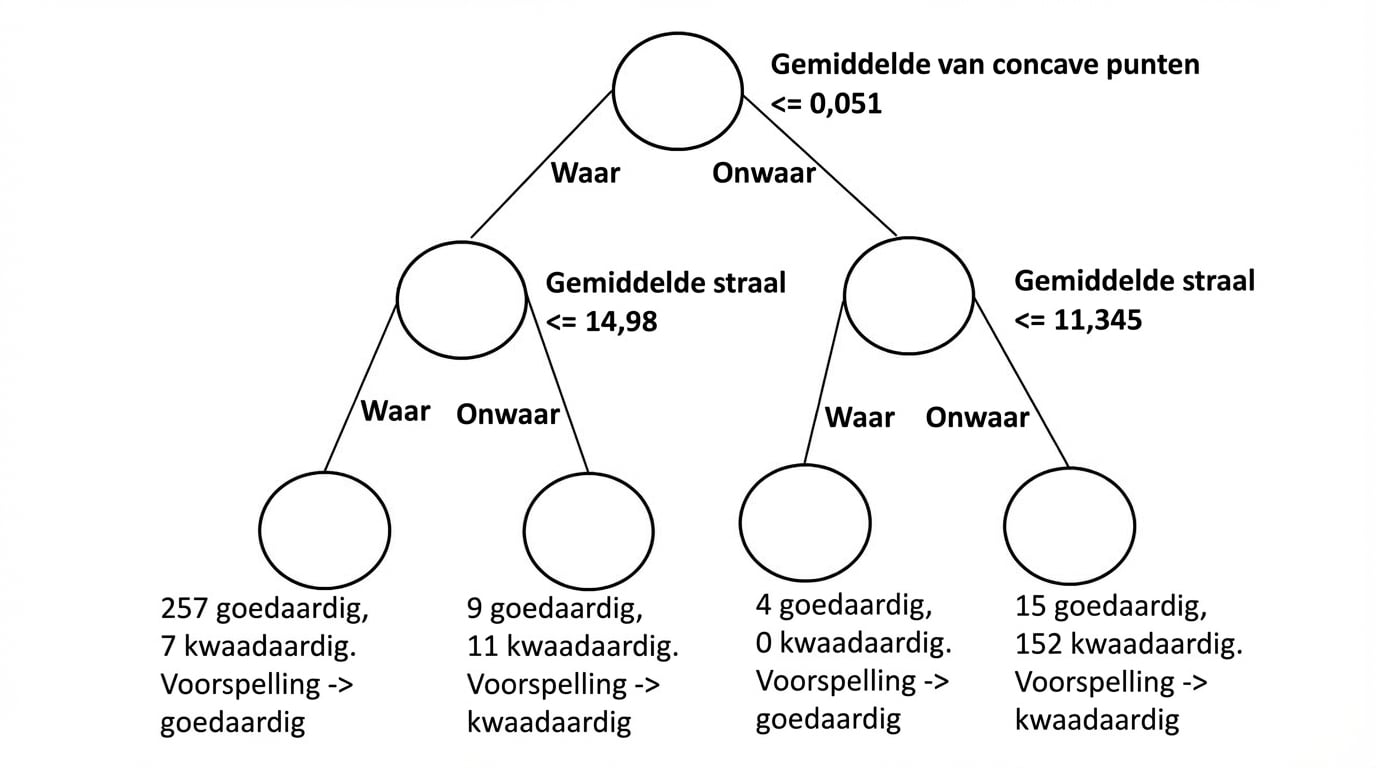
Beslissingsboom voor classificatie
Machine Learning met boomgebaseerde modellen in Python

Elie Kawerk
Data Scientist
Borstkankerdataset in 2D
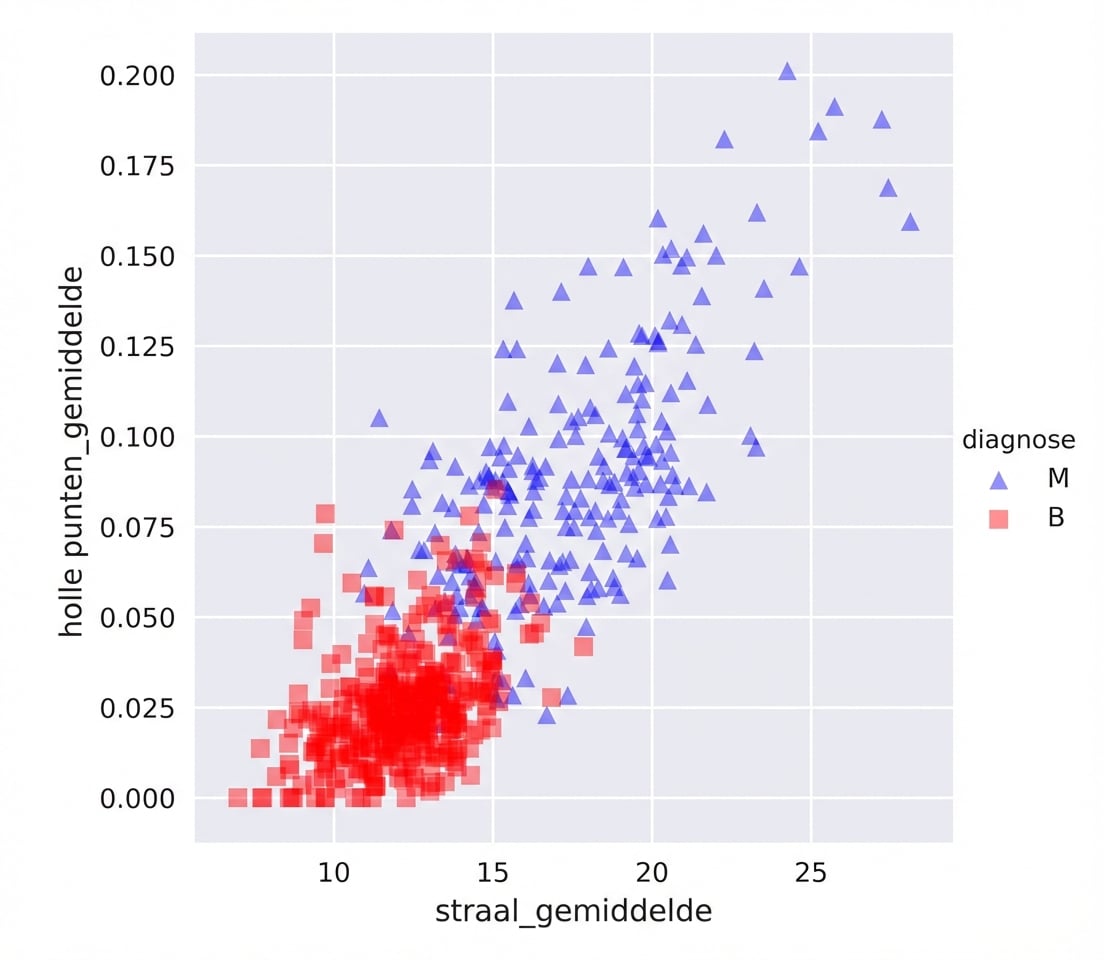
Diagram van beslissingsboom
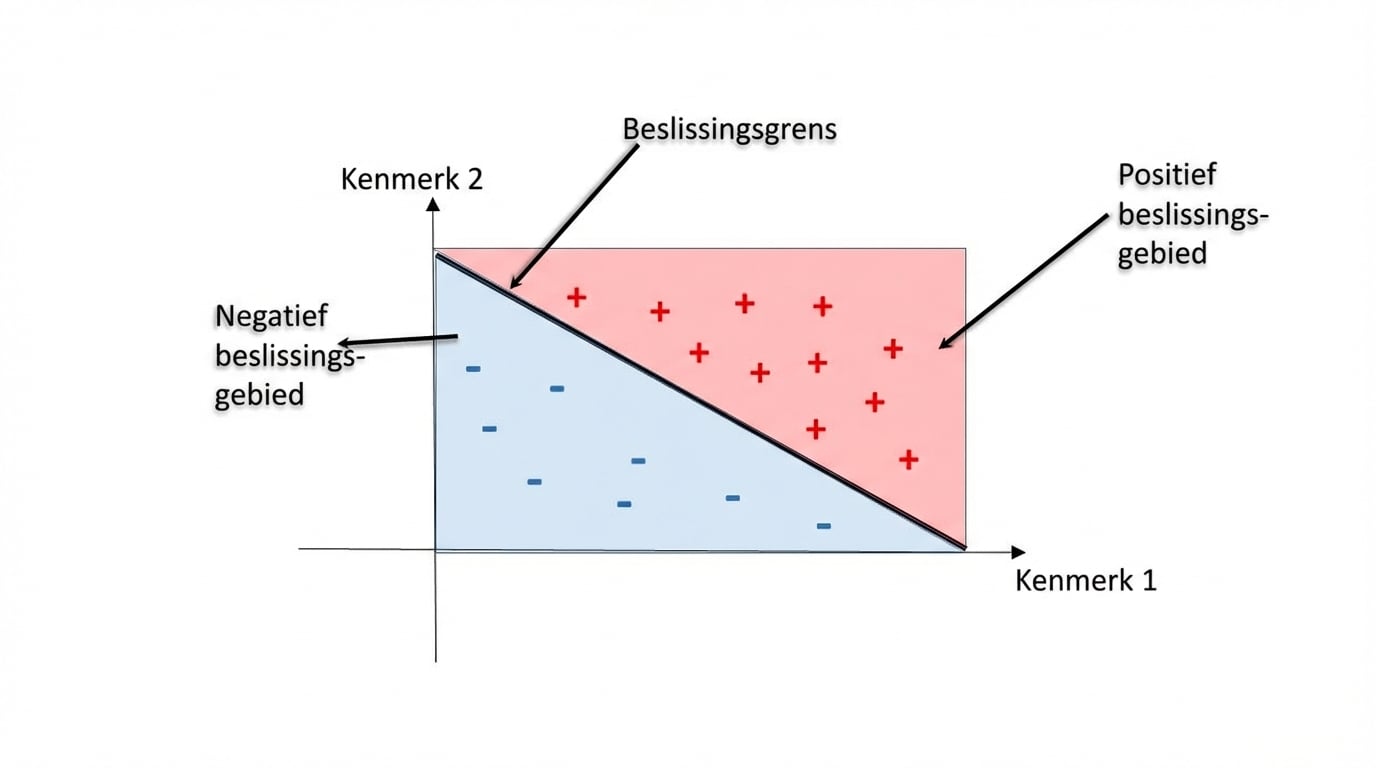
Beslissingsregio’s
Beslissingsregio: gebied in de feature-ruimte waar alle instanties één label krijgen.
Beslissingsgrens: grens die beslissingsregio’s scheidt.
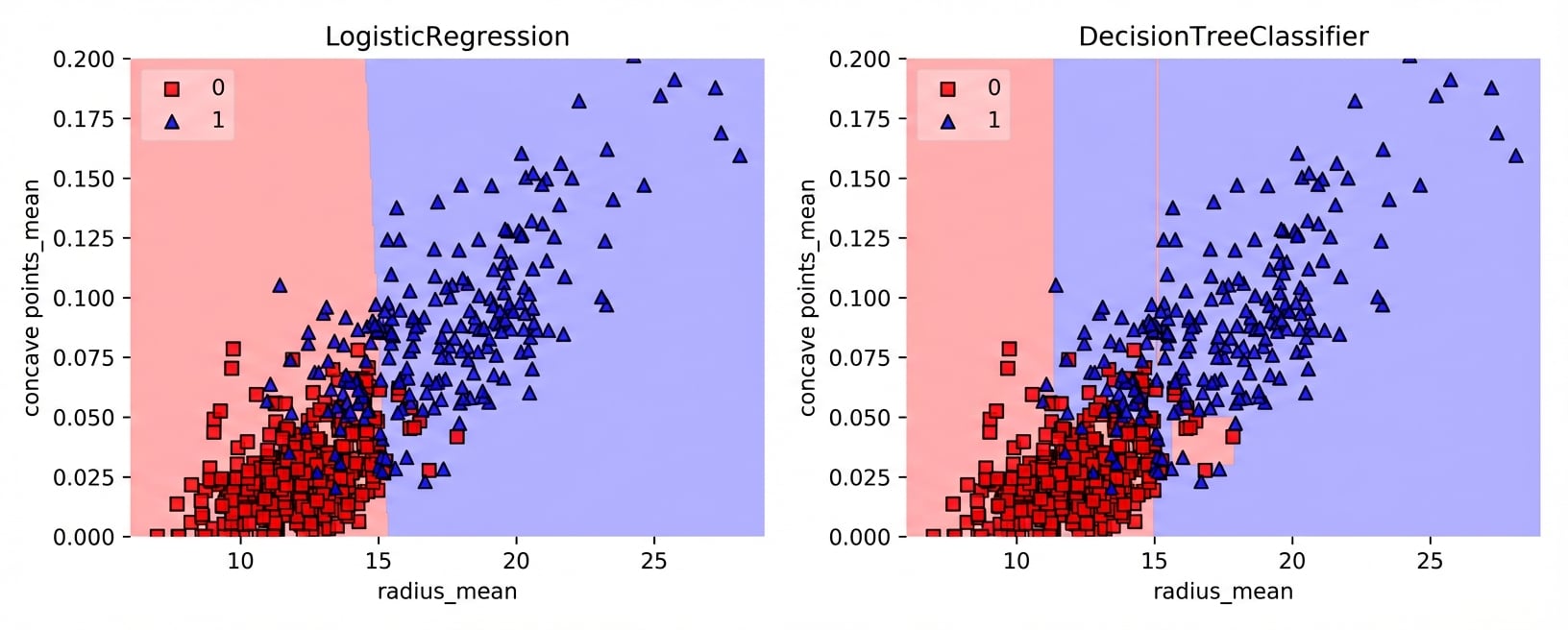
Beslissingsregio’s: CART vs. lineair model