Variabelen transformeren
Introductie tot regressie met statsmodels in Python

Maarten Van den Broeck
Content Developer at DataCamp
Baars-dataset

Het is geen lineair verband
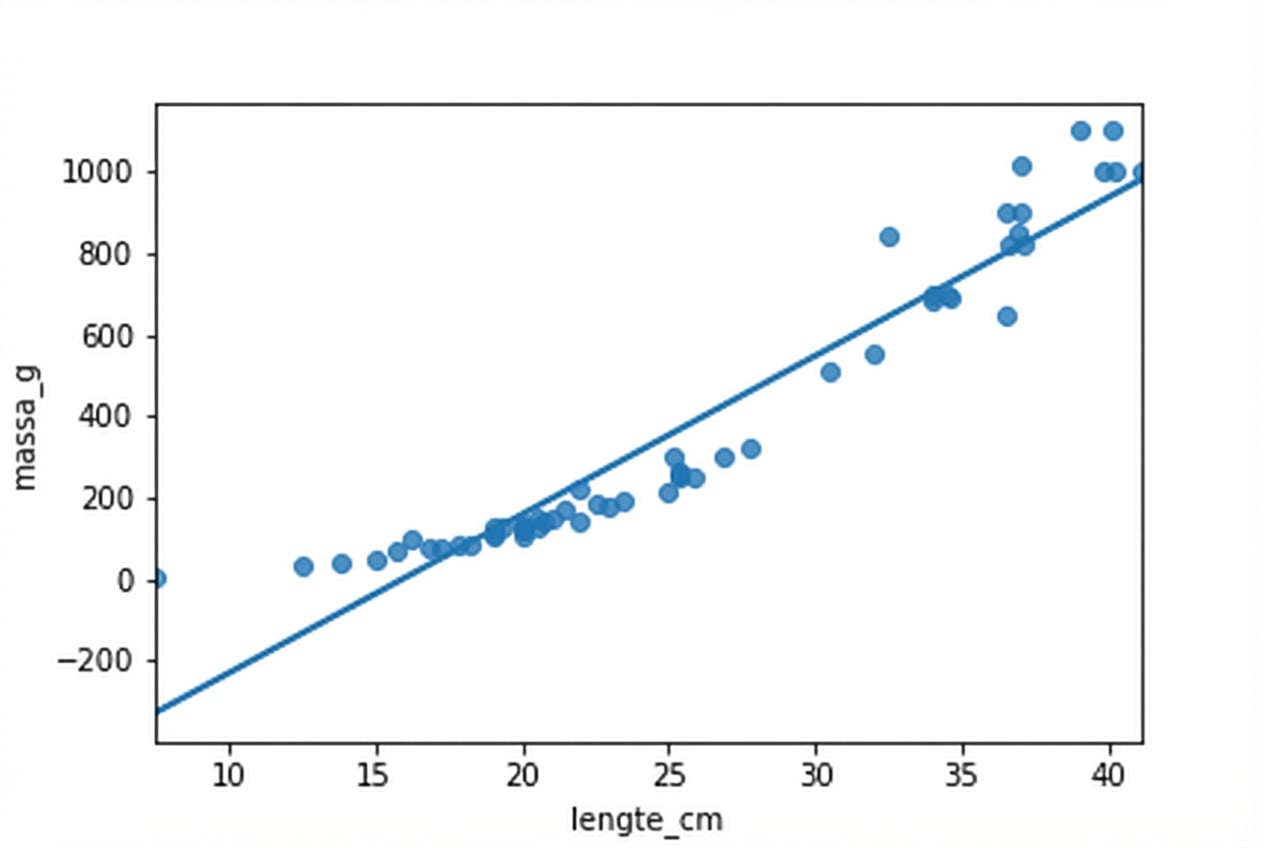
Brasem vs. baars

Massa vs. lengte tot de derde macht plotten
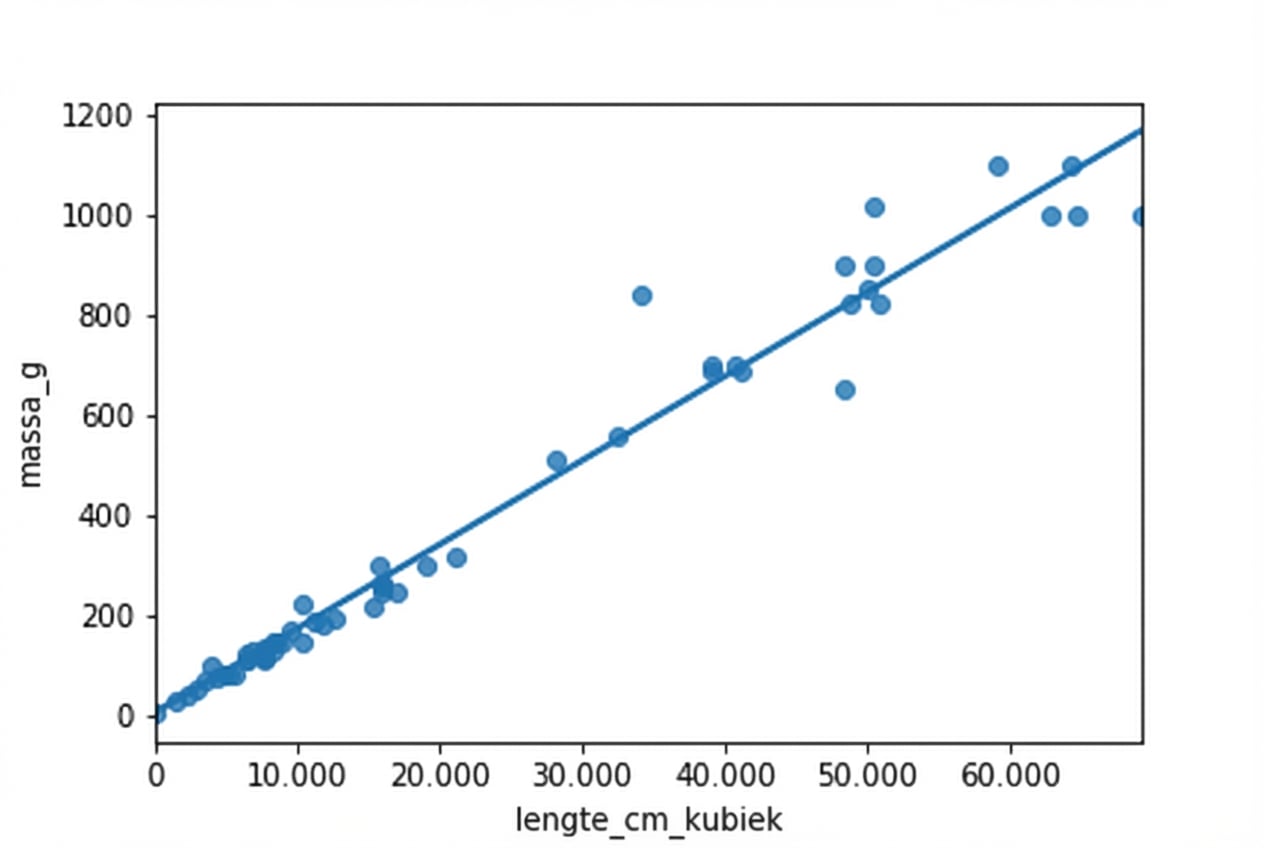
Massa vs. lengte tot de derde macht plotten
fig = plt.figure()
sns.regplot(x="length_cm_cubed", y="mass_g",
data=perch, ci=None)
sns.scatterplot(data=prediction_data,
x="length_cm_cubed", y="mass_g",
color="red", marker="s")
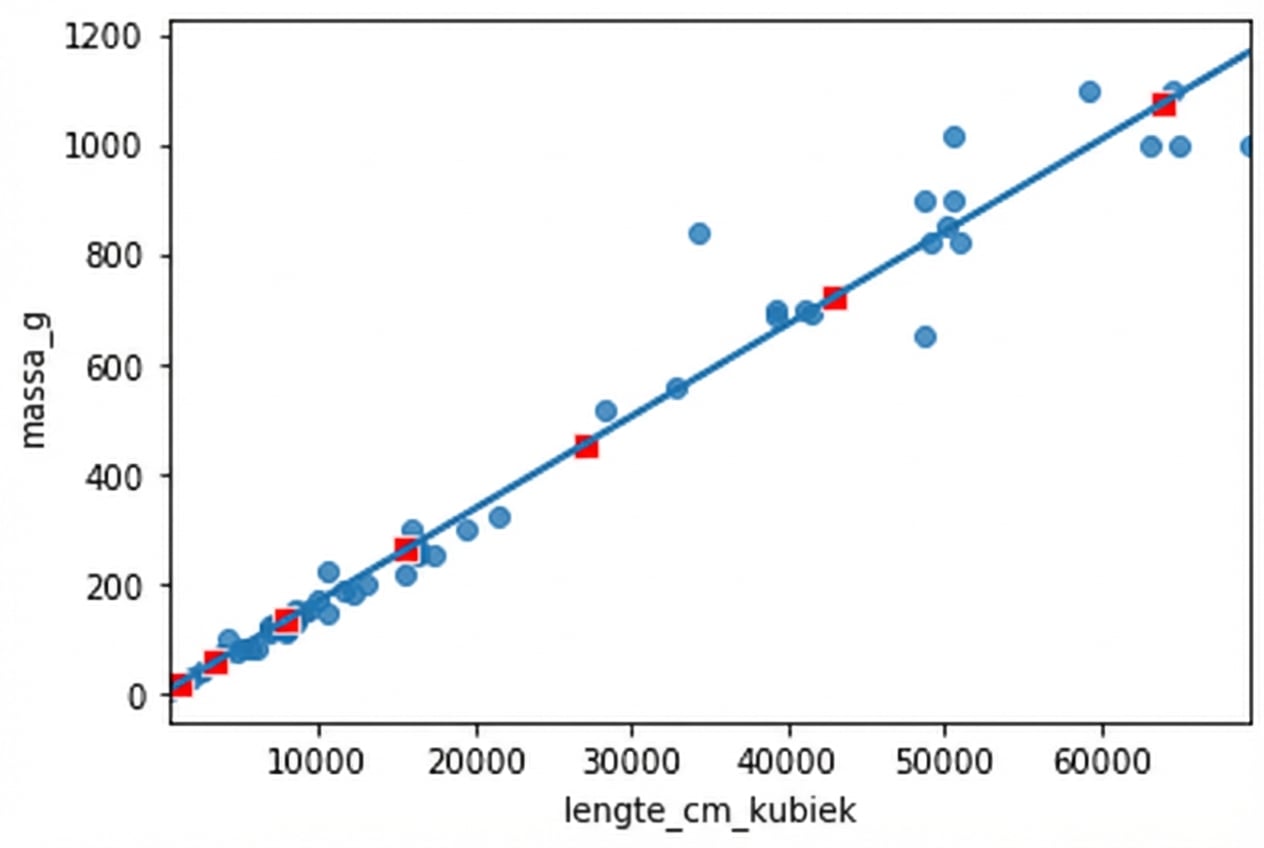
fig = plt.figure()
sns.regplot(x="length_cm", y="mass_g",
data=perch, ci=None)
sns.scatterplot(data=prediction_data,
x="length_cm", y="mass_g",
color="red", marker="s")
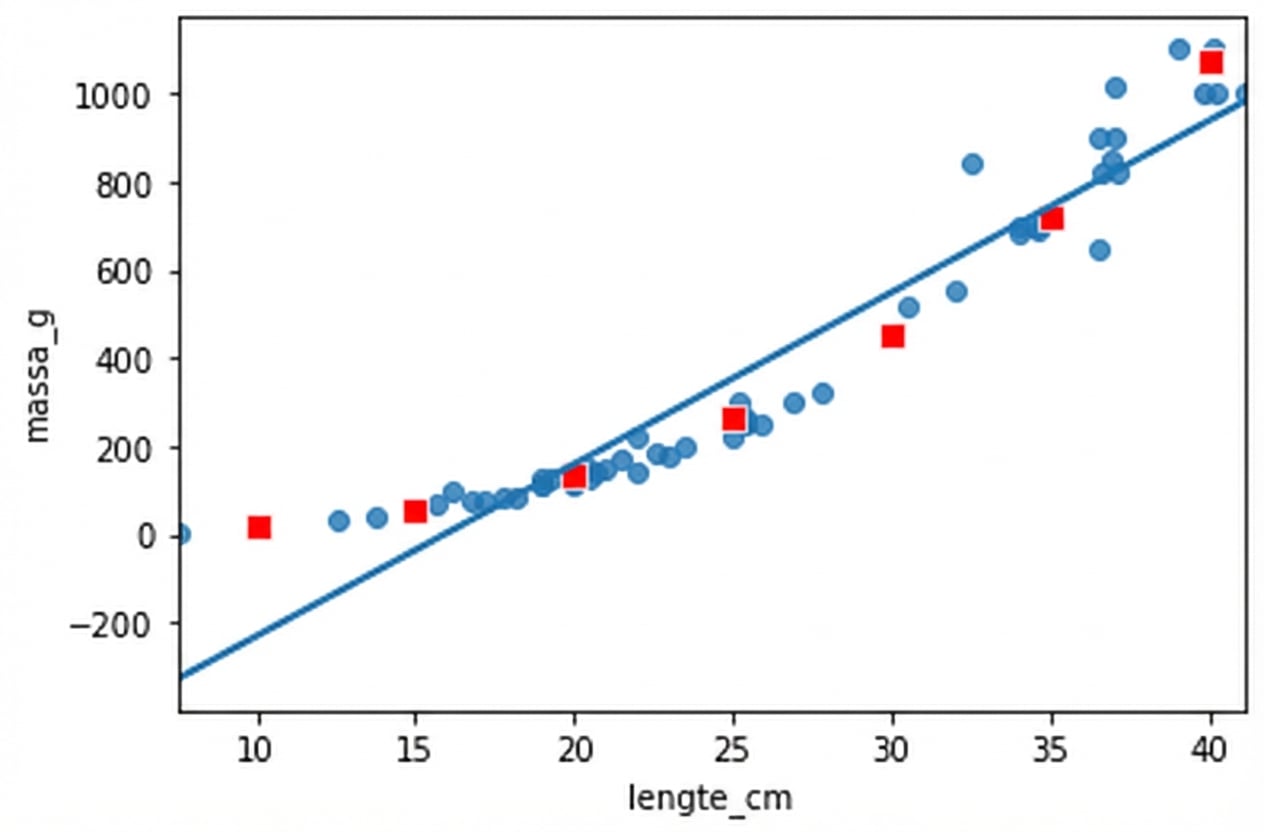
Plot is opgepakt
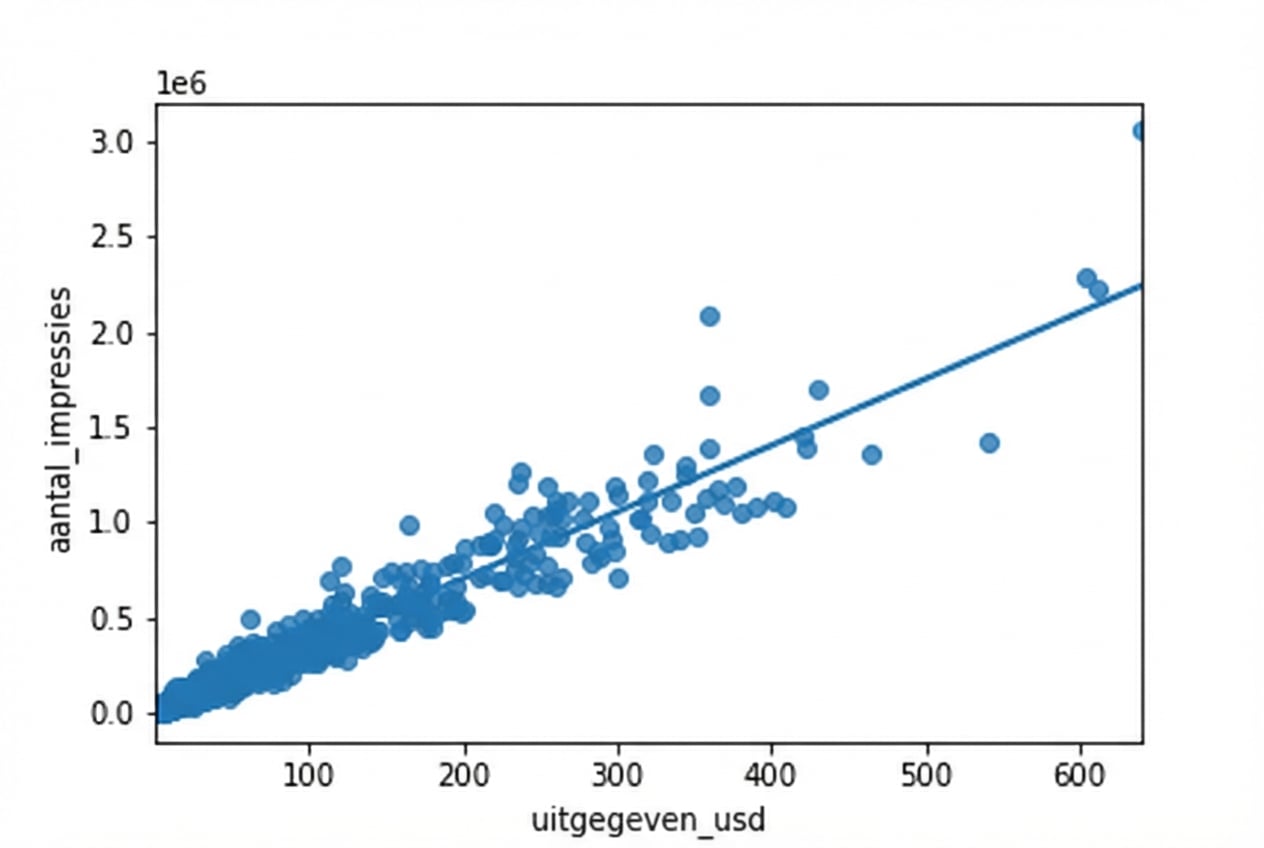
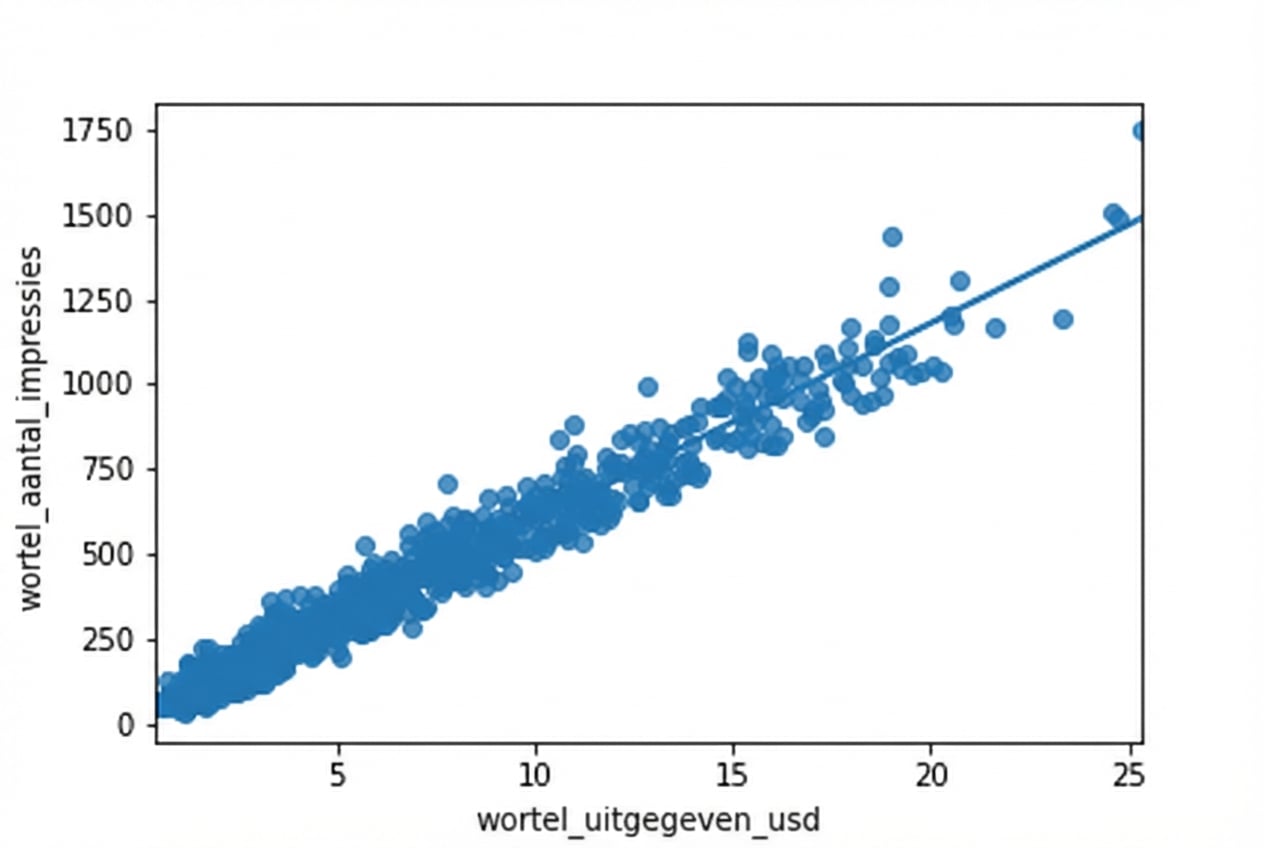
Wortel vs. wortel