Optimizers, training en evaluatie
Gevorderde Deep Learning met PyTorch

Michal Oleszak
Machine Learning Engineer
Hoe een optimizer werkt

Hoe een optimizer werkt
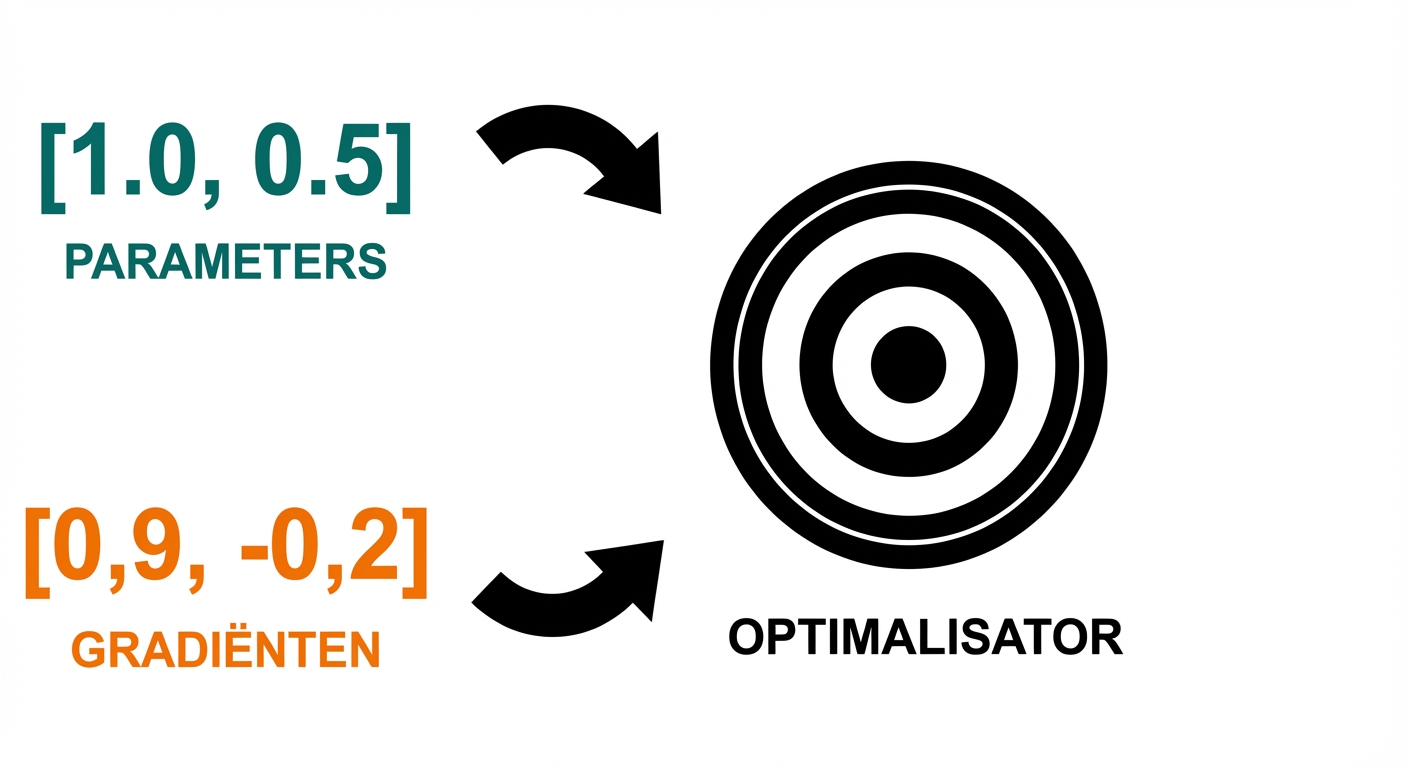
Hoe een optimizer werkt
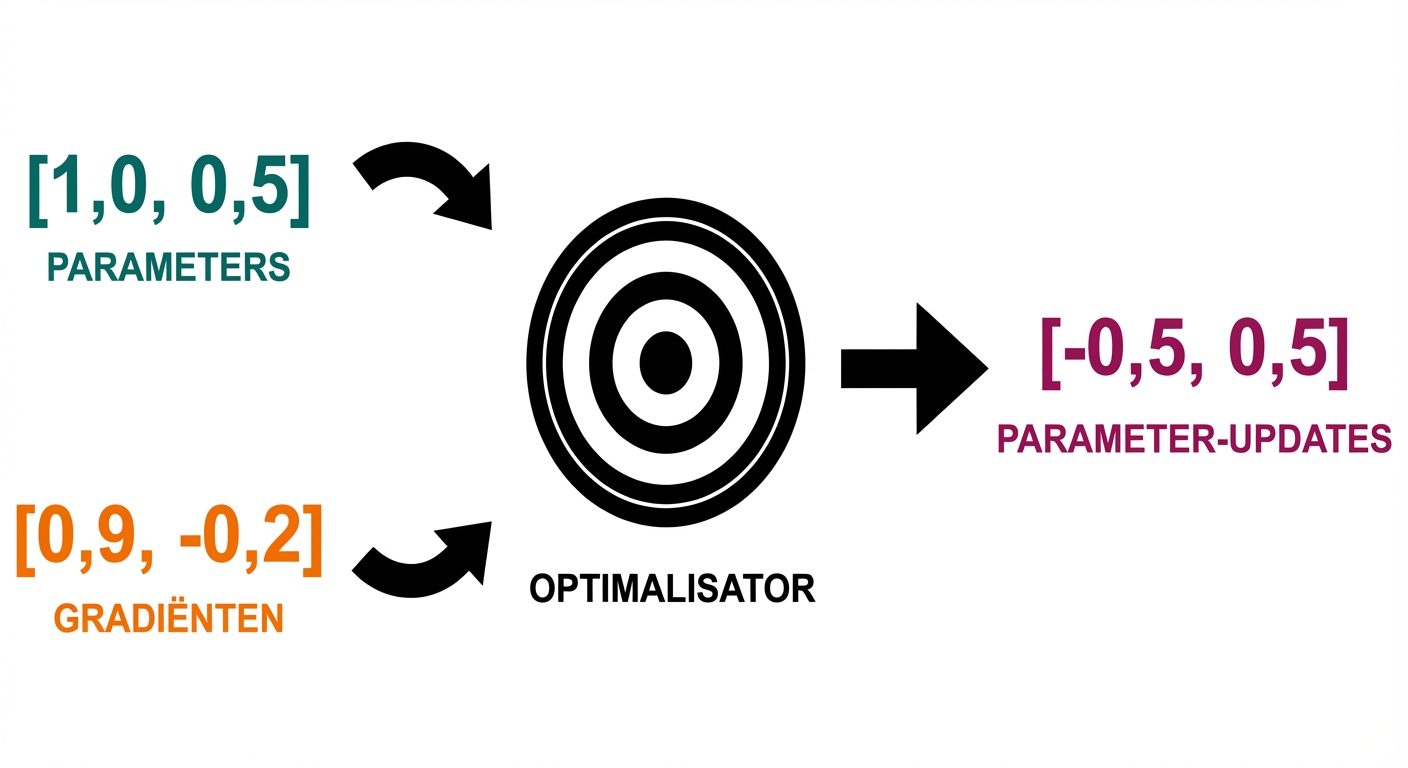
Hoe een optimizer werkt
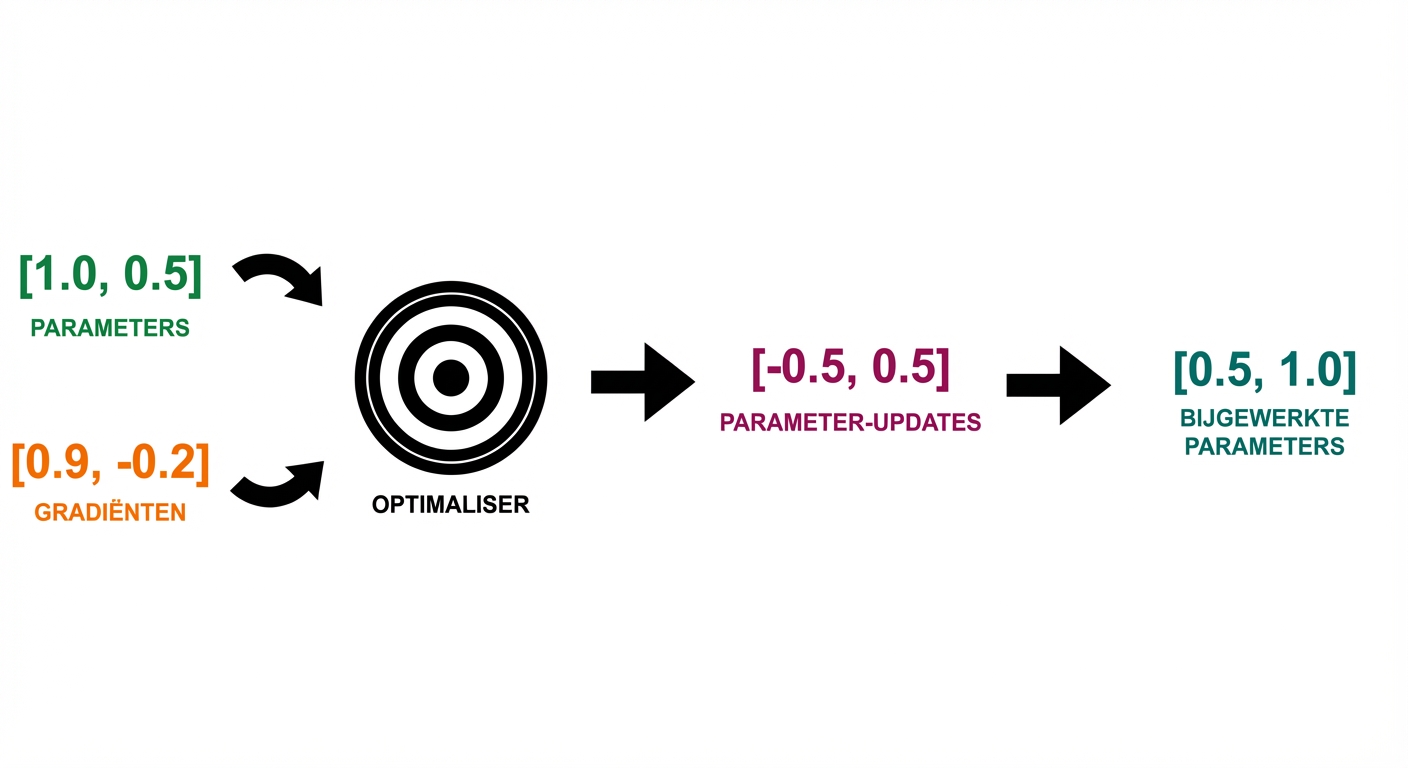
Hoe een optimizer werkt
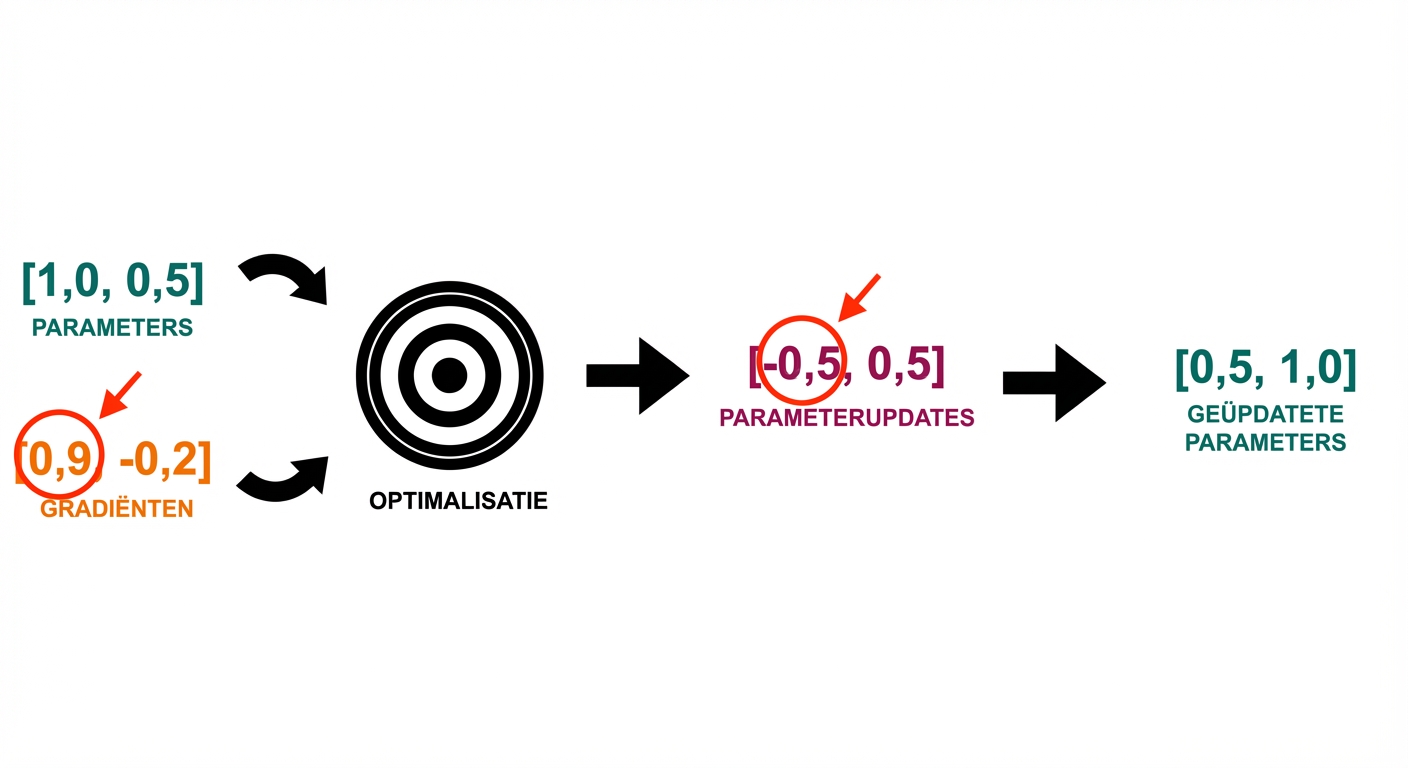
Gevorderde Deep Learning met PyTorch
Michal Oleszak
Machine Learning Engineer

