LSTM- en GRU-cellen
Gevorderde Deep Learning met PyTorch

Michal Oleszak
Machine Learning Engineer
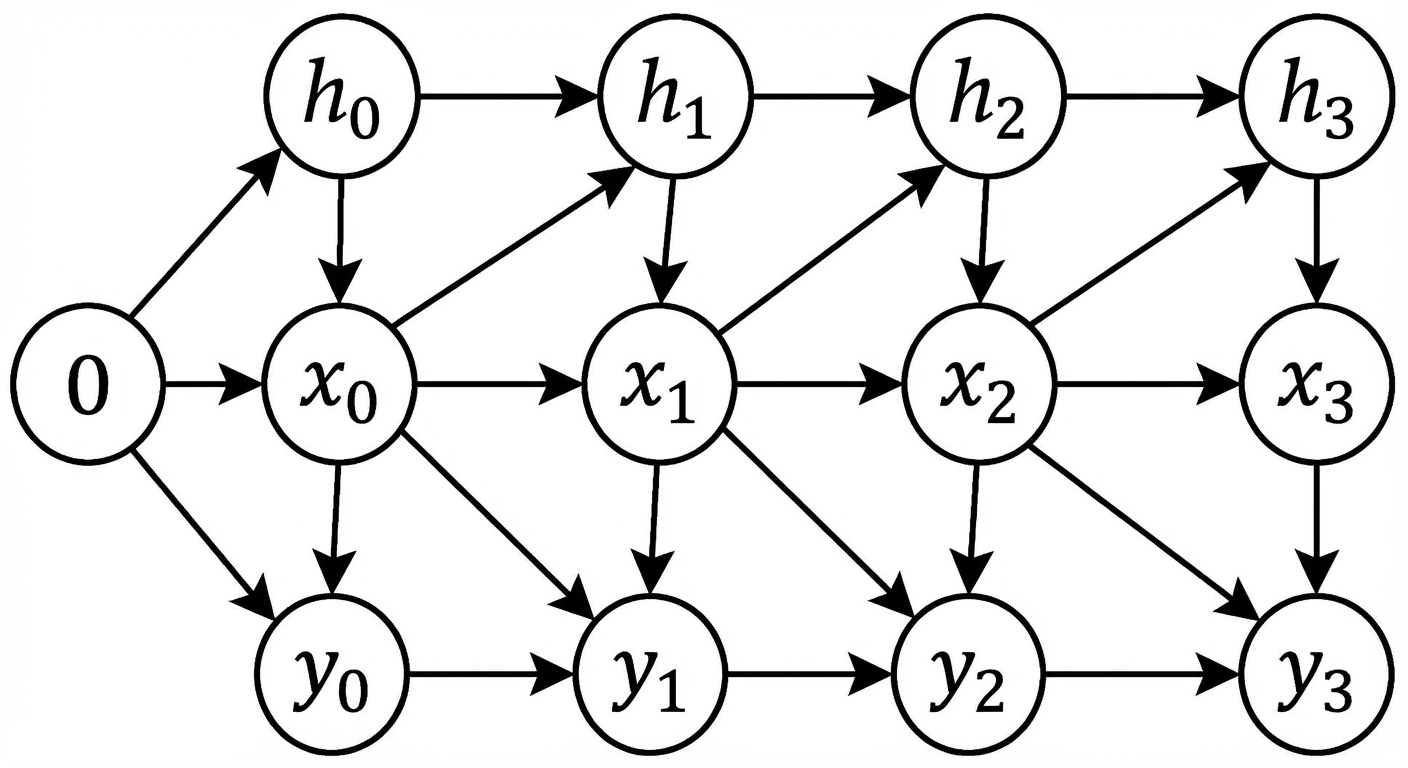
Kortetermijngeheugenprobleem
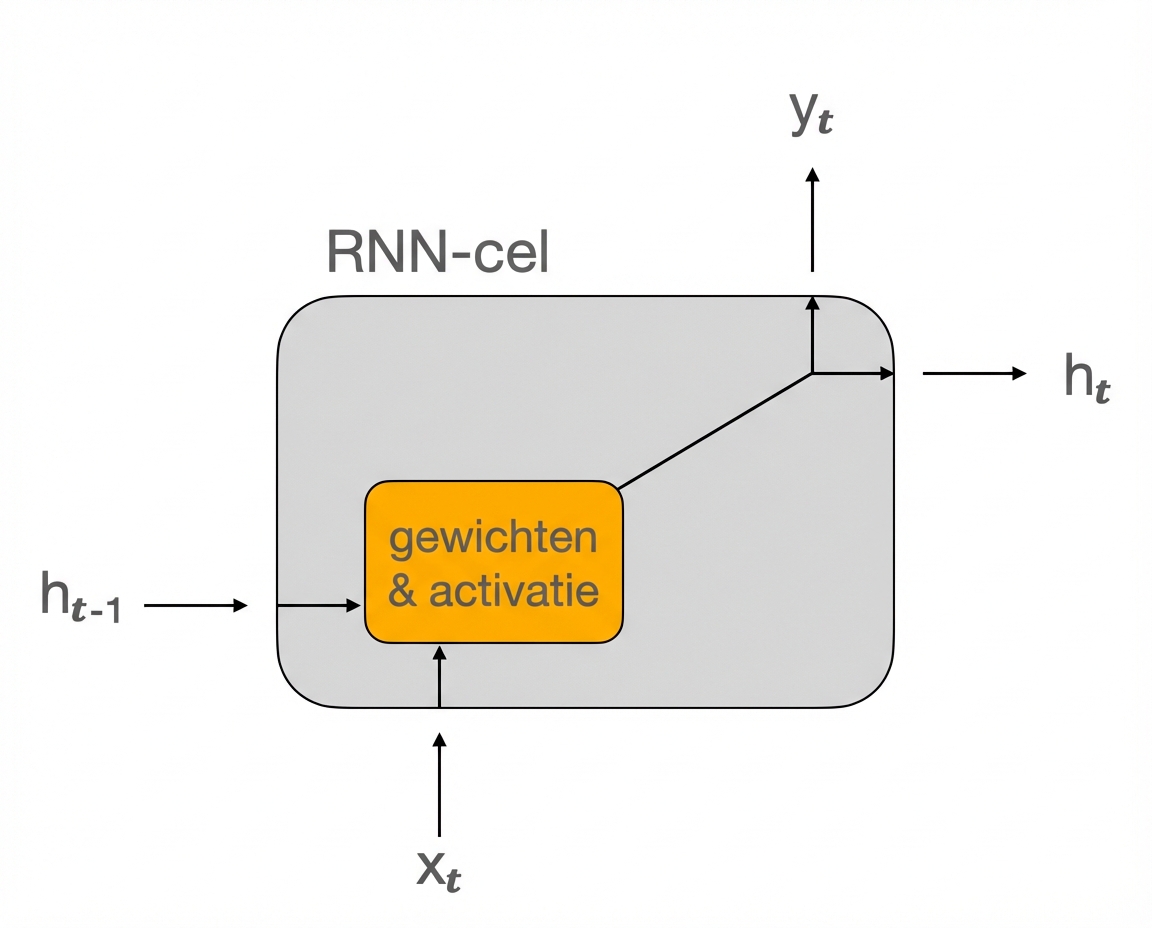
RNN-cel
LSTM-cel
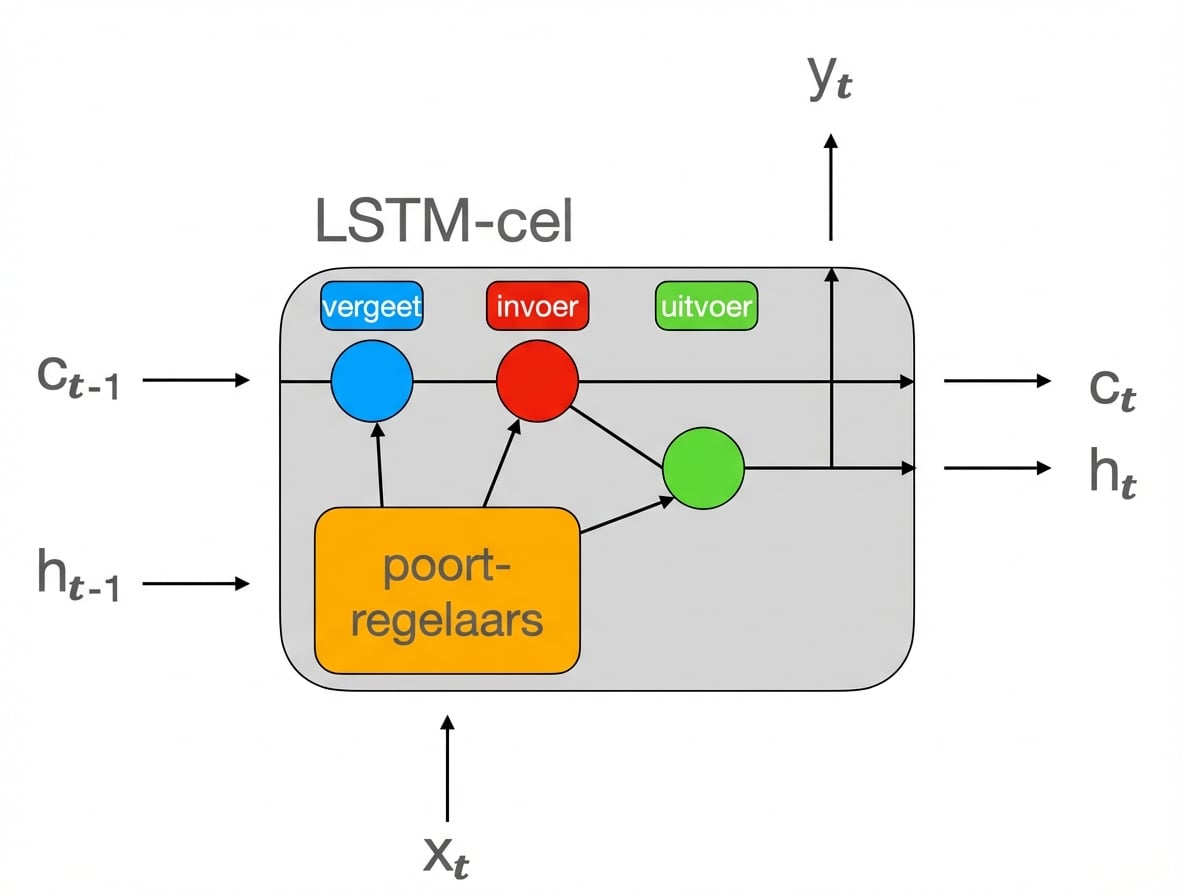
- Outputs
henyzijn hetzelfde
GRU-cel
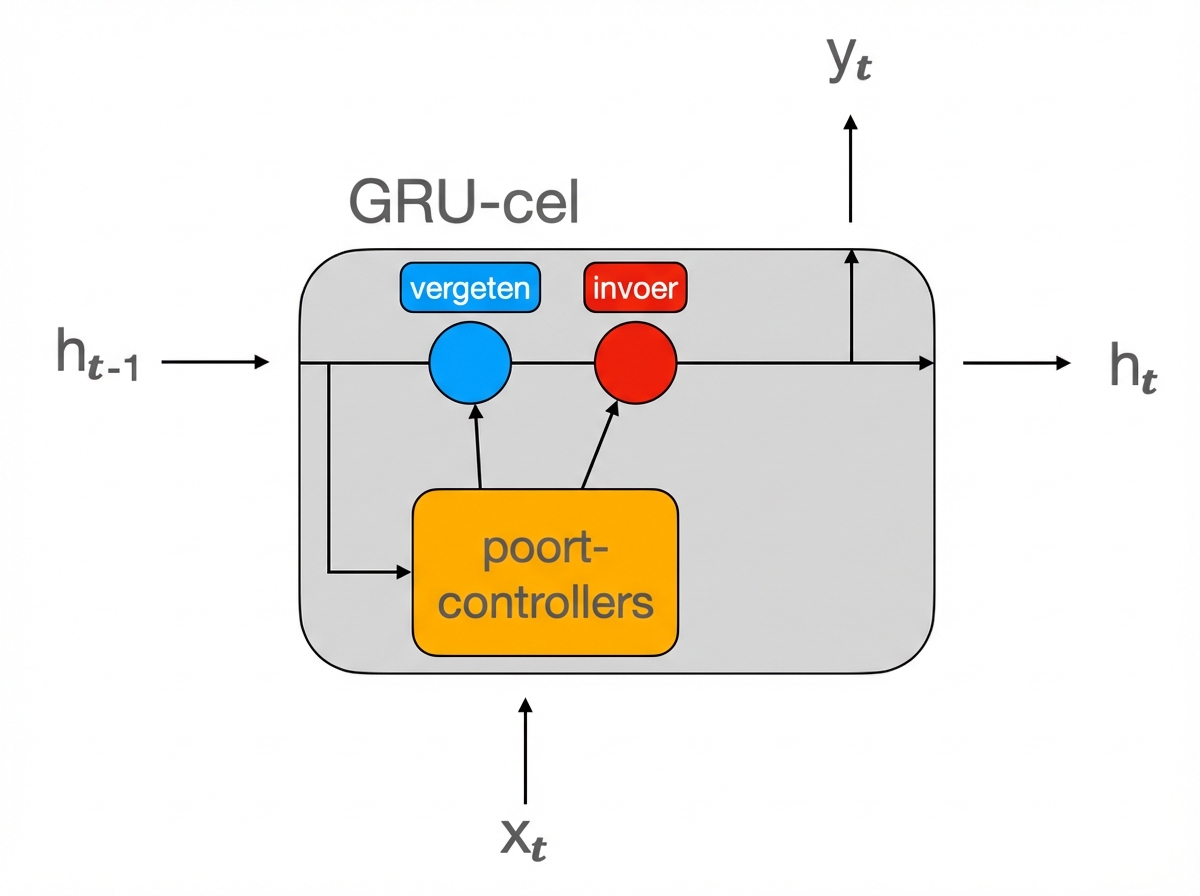
Moet ik RNN, LSTM of GRU gebruiken?
- RNN wordt weinig meer gebruikt
- GRU is eenvoudiger dan LSTM = minder rekenwerk
- Relatieve performance verschilt per use-case
- Probeer beide en vergelijk


