Verwijnende en exploderende gradiënten
Gevorderde Deep Learning met PyTorch

Michal Oleszak
Machine Learning Engineer
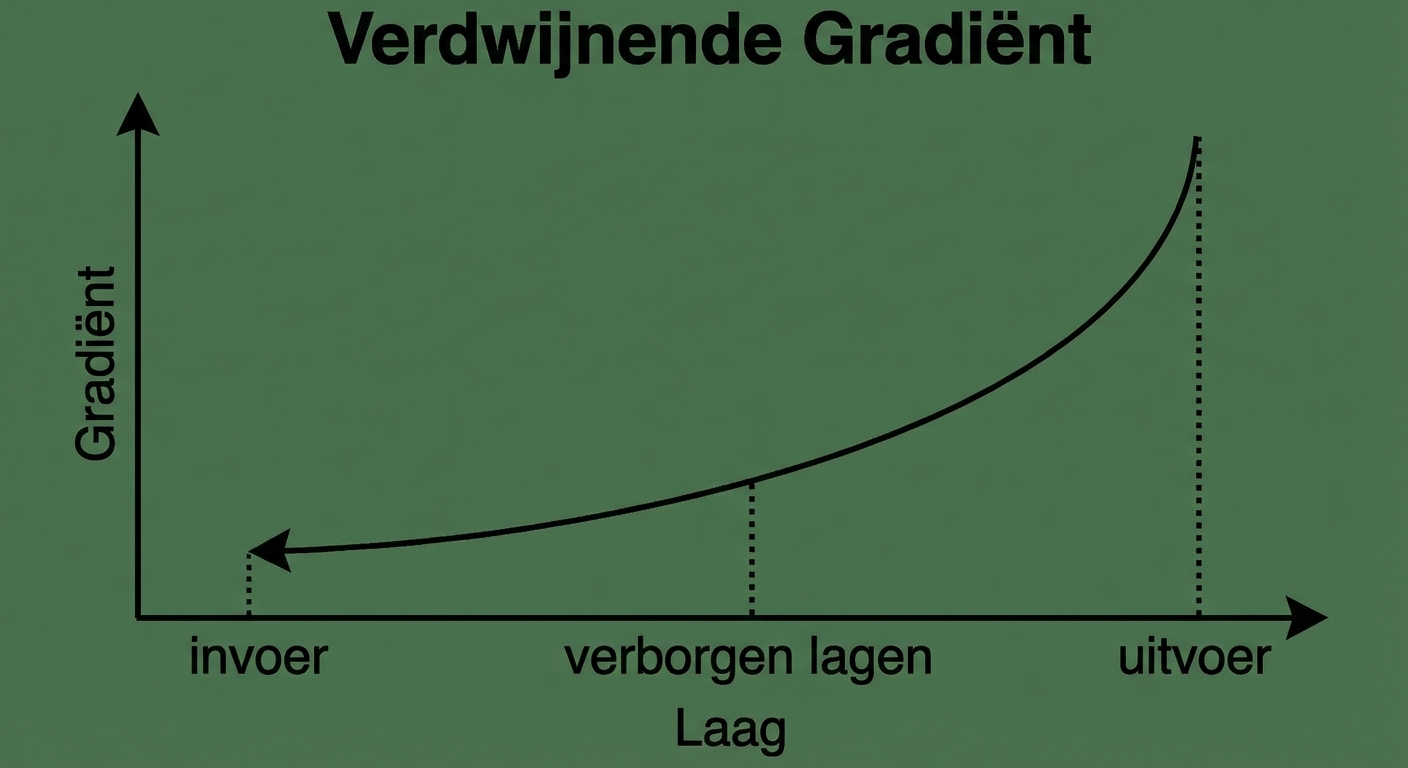
Verwijnende gradiënten
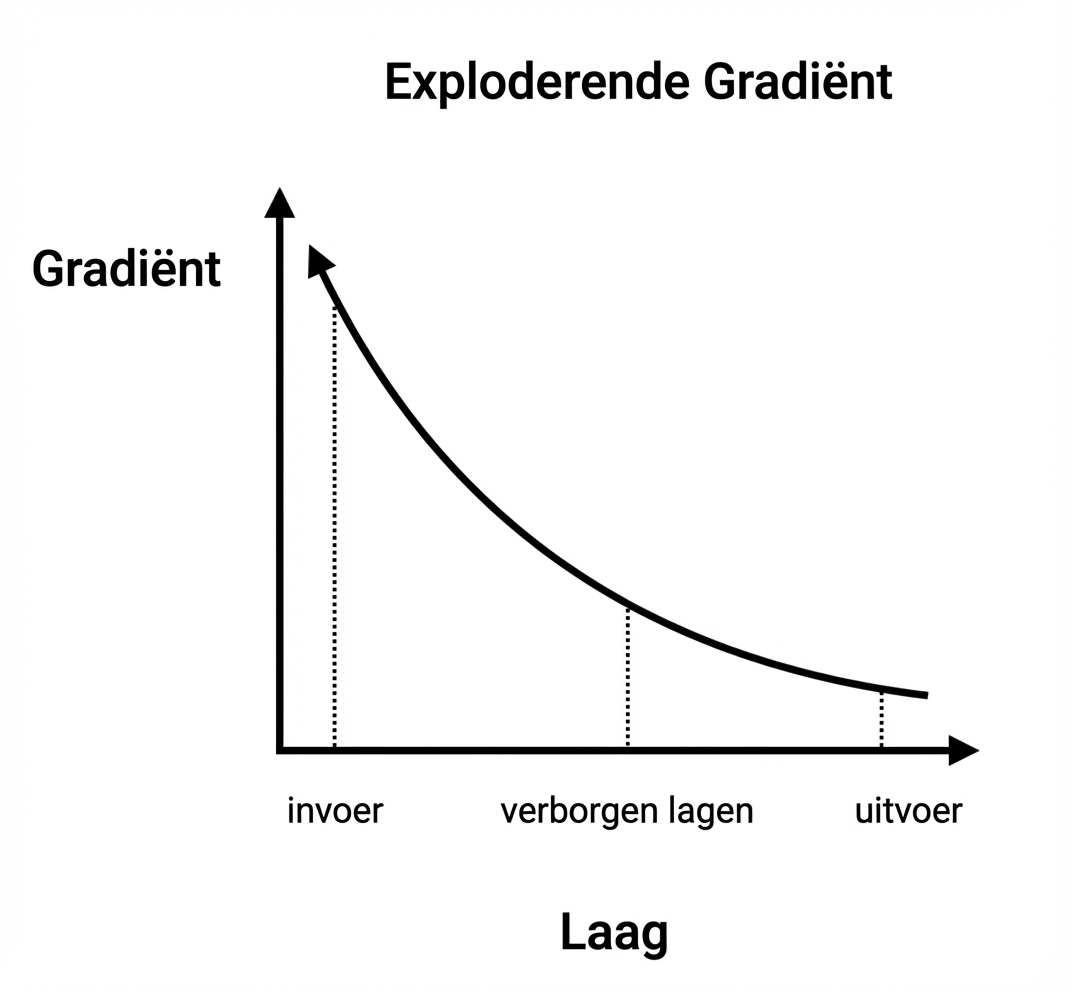
Exploderende gradiënten
Oplossing voor onstabiele gradiënten
- Juiste gewichtsinitialisatie
- Goede activaties
- Batch-normalisatie

Activatiefuncties
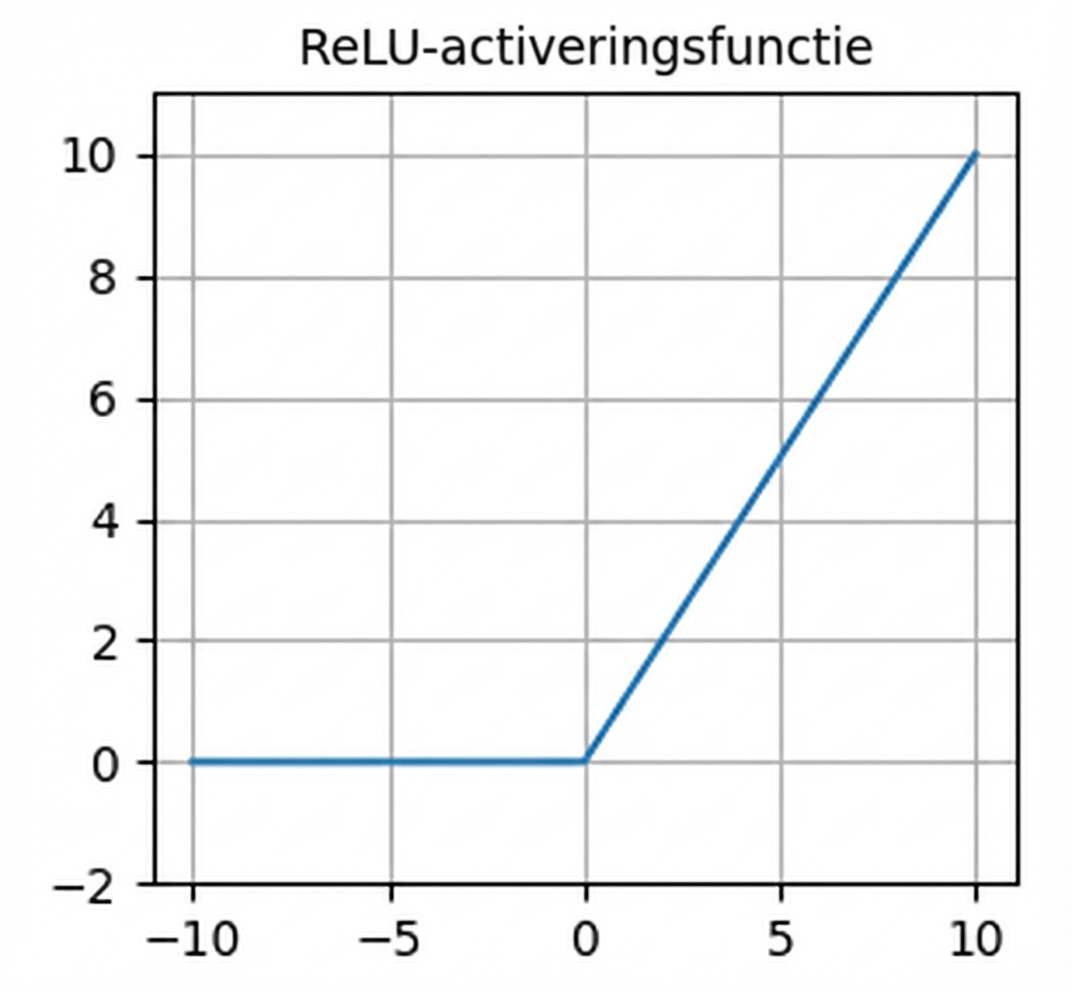
- Vaak de standaardactivatie
nn.functional.relu()- Nul voor negatieve inputs – dode neuronen
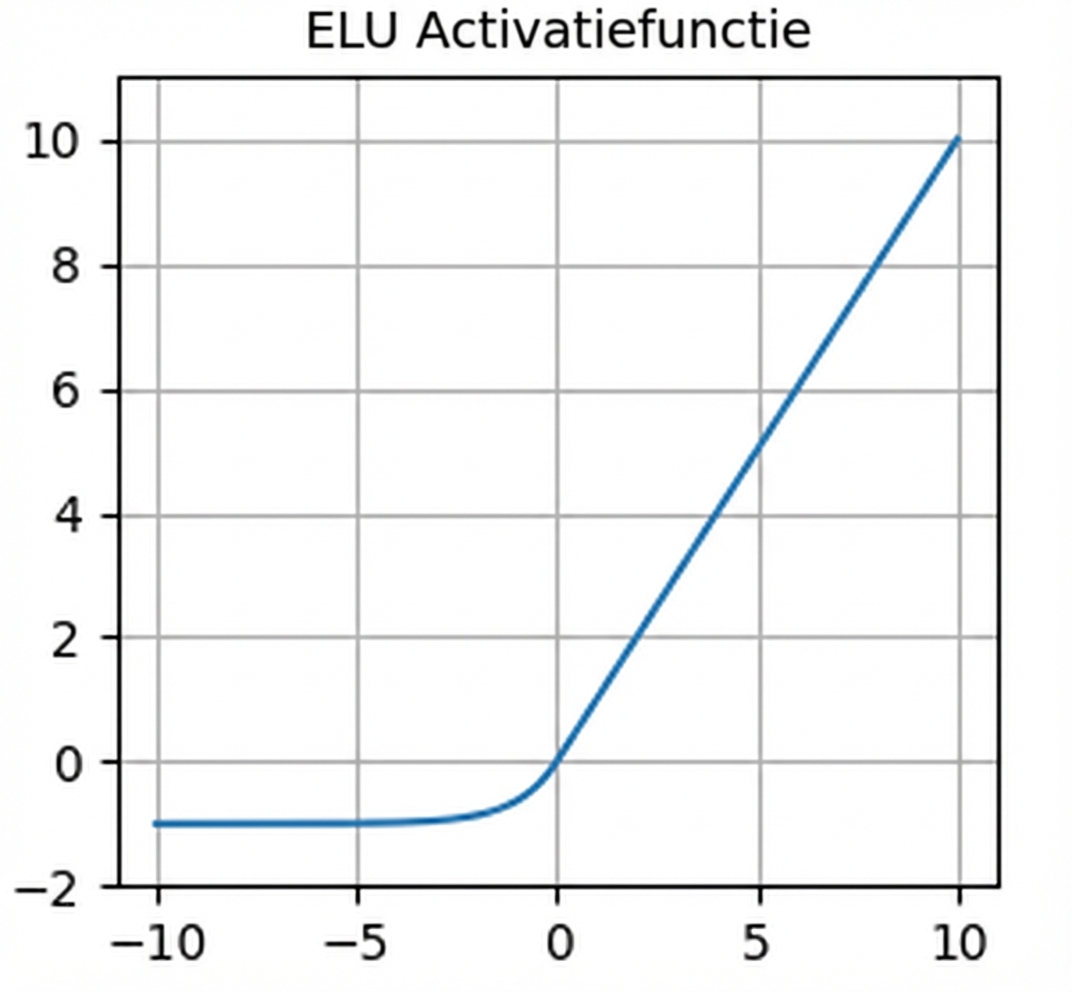
nn.functional.elu()- Niet-nul gradiënten voor negatieve waarden – helpt tegen dode neuronen
- Gemiddelde output rond nul – helpt tegen verdwijnende gradiënten

