Steekproef- vs. bootstrapverdelingen vergelijken
Steekproeven in Python

James Chapman
Curriculum Manager, DataCamp
Subset gericht op koffie
coffee_sample = coffee_ratings[["variety", "country_of_origin", "flavor"]]\
.reset_index().sample(n=500)
index variety country_of_origin flavor
132 132 Other Costa Rica 7.58
51 51 None United States (Hawaii) 8.17
42 42 Yellow Bourbon Brazil 7.92
569 569 Bourbon Guatemala 7.67
.. ... ... ... ...
643 643 Catuai Costa Rica 7.42
356 356 Caturra Colombia 7.58
494 494 None Indonesia 7.58
169 169 None Brazil 7.81
[500 rows x 4 columns]
Bootstrap van gemiddelde koffiesmaken
import numpy as np
mean_flavors_5000 = []
for i in range(5000):
mean_flavors_5000.append(
np.mean(coffee_sample.sample(frac=1, replace=True)['flavor'])
)
bootstrap_distn = mean_flavors_5000
Bootstrapverdeling van het gemiddelde ‘flavor’
import matplotlib.pyplot as plt
plt.hist(bootstrap_distn, bins=15)
plt.show()
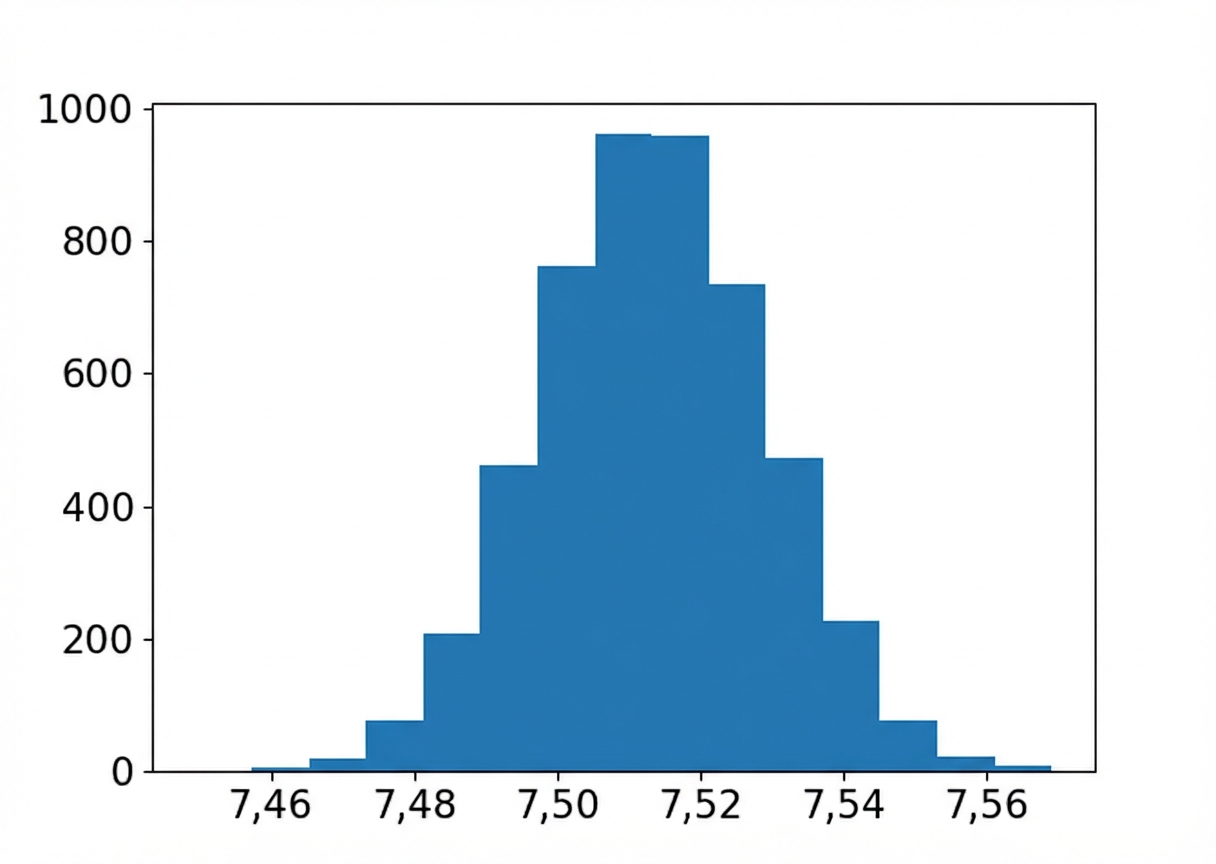
Steekproef-, bootstrapverdeling- en populatiegemiddelden
Steekproefgemiddelde:
coffee_sample['flavor'].mean()
7.5132200000000005
Geschat populatiegemiddelde:
np.mean(bootstrap_distn)
7.513357731999999
Waar populatiegemiddelde:
coffee_ratings['flavor'].mean()
7.526046337817639
De gemiddelden interpreteren
Gemiddelde van de bootstrapverdeling:
- Meestal dicht bij het steekproefgemiddelde
- Misschien geen goede schatting van het populatiegemiddelde
Bootstrapping corrigeert geen steekproefbias
Steekproef-sd vs. bootstrapverdeling-sd
Steekproefstandaarddeviatie:
coffee_sample['flavor'].std()
0.3540883911928703
Geschatte populatiestandaarddeviatie?
np.std(bootstrap_distn, ddof=1)
0.015768474367958217
Steekproef-, bootstrap- en populatie-standaarddeviaties
Steekproefstandaarddeviatie:
coffee_sample['flavor'].std()
0.3540883911928703
Geschatte populatiestandaarddeviatie:
standard_error = np.std(bootstrap_distn, ddof=1)
Standaardfout is de standaarddeviatie van de statistiek van interesse
Ware standaarddeviatie:
coffee_ratings['flavor'].std(ddof=0)
0.34125481224622645
standard_error * np.sqrt(500)
0.3525938058821761
Standaardfout maal wortel van steekproefgrootte schat de populatiestandaarddeviatie
De standaardfouten interpreteren
- Geschatte standaardfout → standaarddeviatie van de bootstrapverdeling voor een steekproefstatistiek
- $\text{Populatie-std. dev} \approx \text{Standaardfout} \times \sqrt{\text{Steekproefgrootte}}$
Laten we oefenen!
Steekproeven in Python

