Introductie tot bootstrapping
Steekproeven in Python

James Chapman
Curriculum Manager, DataCamp
Met of zonder
Steekproeven zonder teruglegging:

Steekproeven met teruglegging ("resampling"):

Aselecte steekproef zonder teruglegging
Populatie:

Steekproef:

Aselecte steekproef met teruglegging
Populatie:
Hersteekproef:

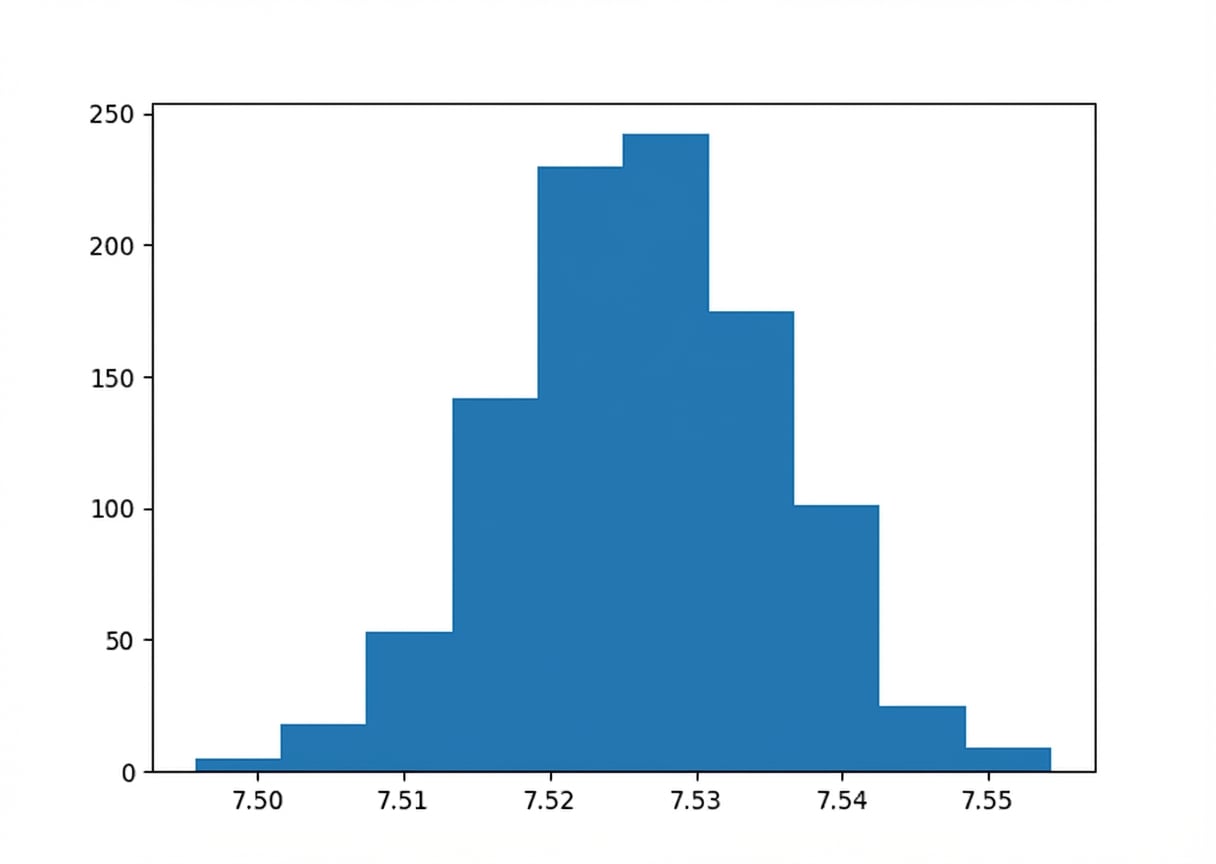
Bootstrapping

Histogram van bootstrapverdeling