Hypothesetoetsen in Python
James Chapman
Curriculum Manager, DataCamp
$H_{0}$: De gemiddelde beloning (in USD) is hetzelfde voor wie eerst als kind codeerde en wie eerst als volwassene codeerde
$H_{A}$: De gemiddelde beloning (in USD) is groter voor wie eerst als kind codeerde dan voor wie eerst als volwassene codeerde
Gebruik een rechtseenzijdige toets
$\alpha = 0,1$
Als $p \le \alpha$, verwerp $H_{0}$.
from scipy.stats import norm 1 - norm.cdf(z_score)
$SE(\bar{x}_{\text{child}} - \bar{x}_{\text{adult}}) \approx \sqrt{\dfrac{s_{\text{child}}^2}{n_{\text{child}}} + \dfrac{s_{\text{adult}}^2}{n_{\text{adult}}}}$
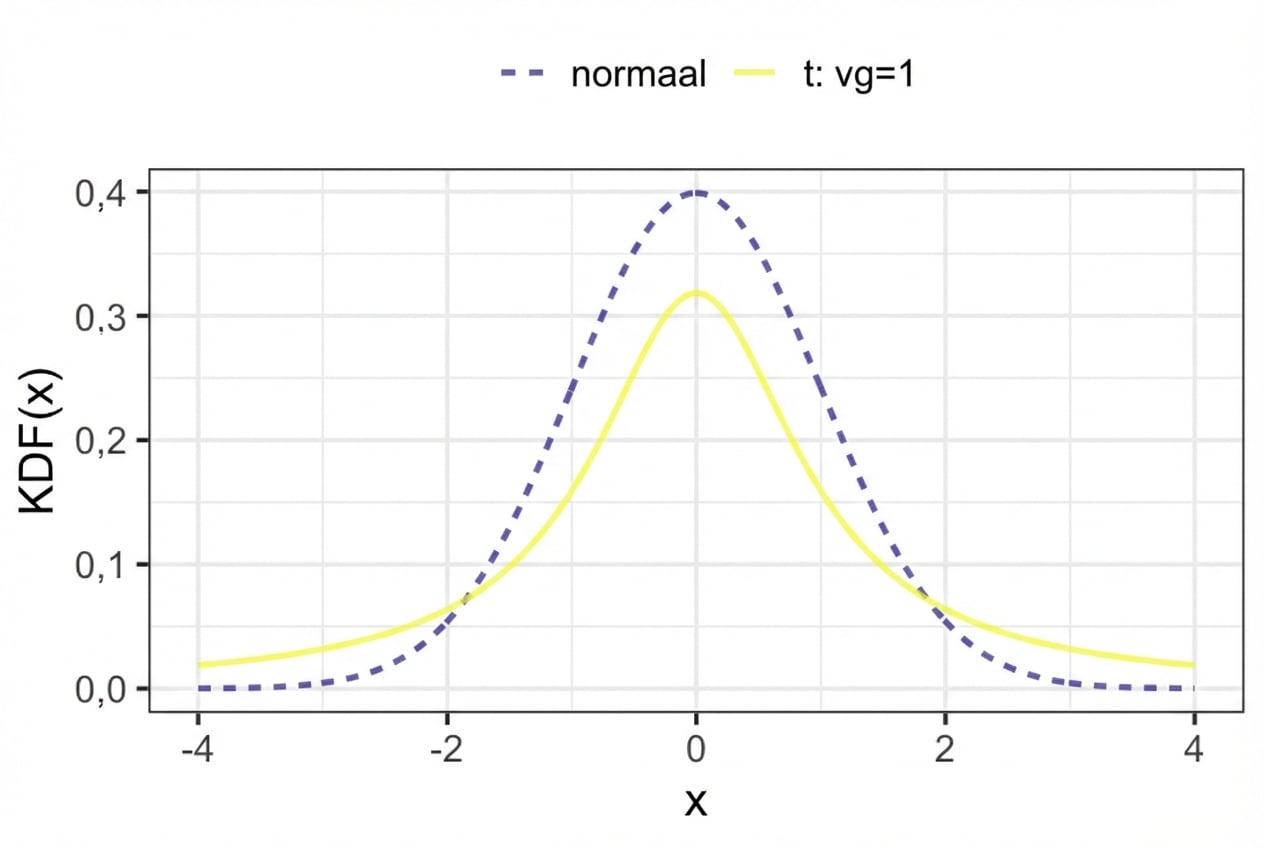
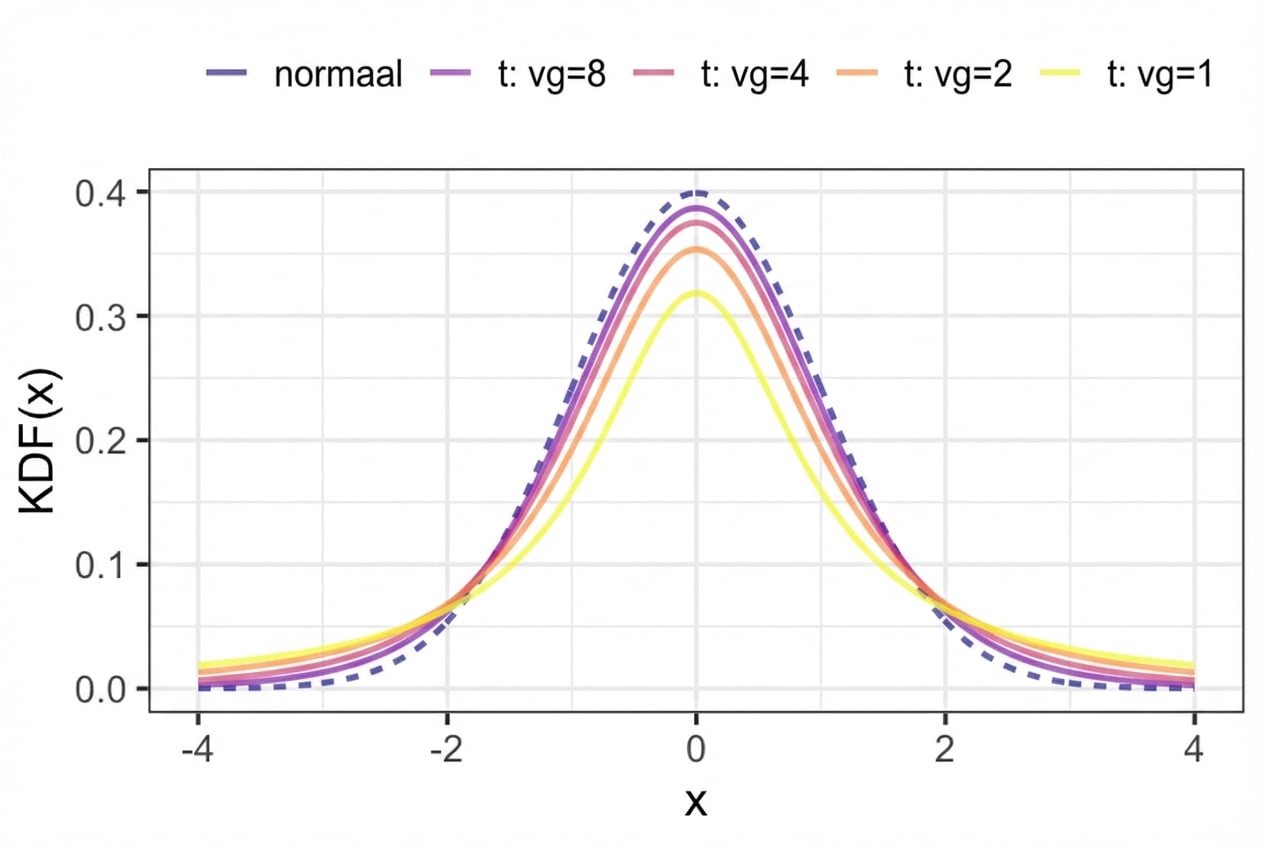
z-statistiek: nodig bij één steekproefstatistiek om een populatieparameter te schatten
t-statistiek: nodig bij meerdere steekproefstatistieken om een populatieparameter te schatten
numerator = xbar_child - xbar_adult denominator = np.sqrt(s_child ** 2 / n_child + s_adult ** 2 / n_adult) t_stat = numerator / denominator
1.8699313316221844
degrees_of_freedom = n_child + n_adult - 2
2259
from scipy.stats import t 1 - t.cdf(t_stat, df=degrees_of_freedom)
0.030811302165157595