Geavanceerde splitsmethoden
Retrieval Augmented Generation (RAG) met LangChain

Meri Nova
Machine Learning Engineer
Splitsen op tokens

Splitsen op tokens
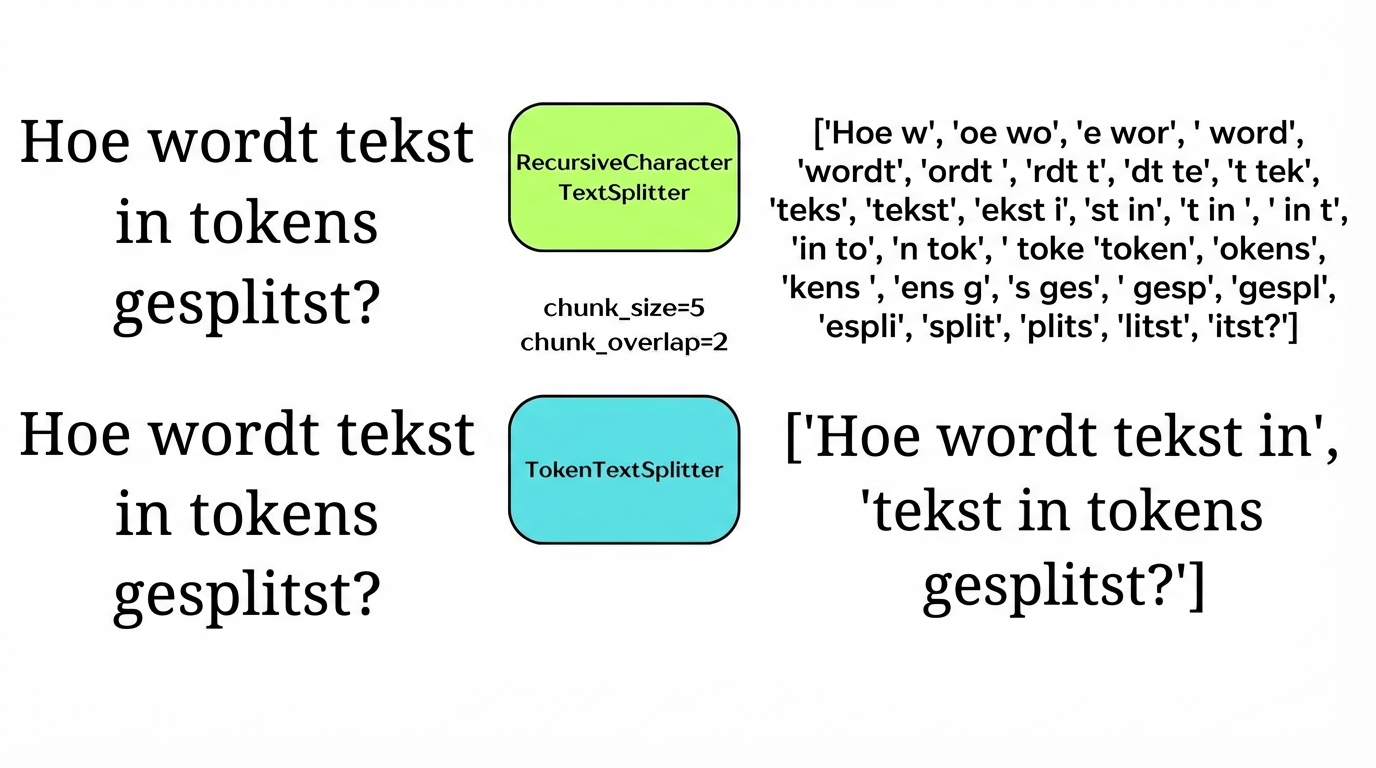
Splitsen op tokens
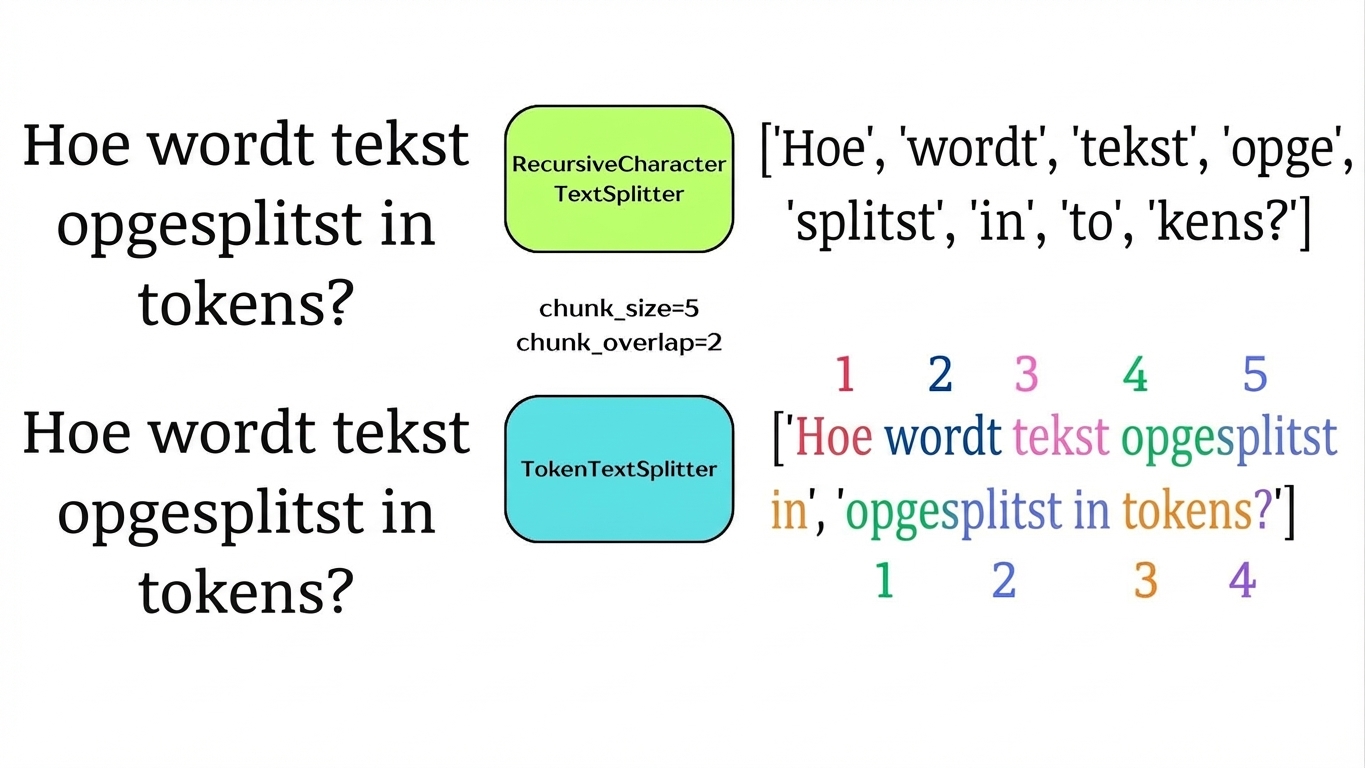
Semantisch splitsen

Semantisch splitsen

Semantisch splitsen

Retrieval Augmented Generation (RAG) met LangChain
Meri Nova
Machine Learning Engineer

