Introductie tot RAG-evaluatie
Retrieval Augmented Generation (RAG) met LangChain

Meri Nova
Machine Learning Engineer
Typen RAG-evaluatie
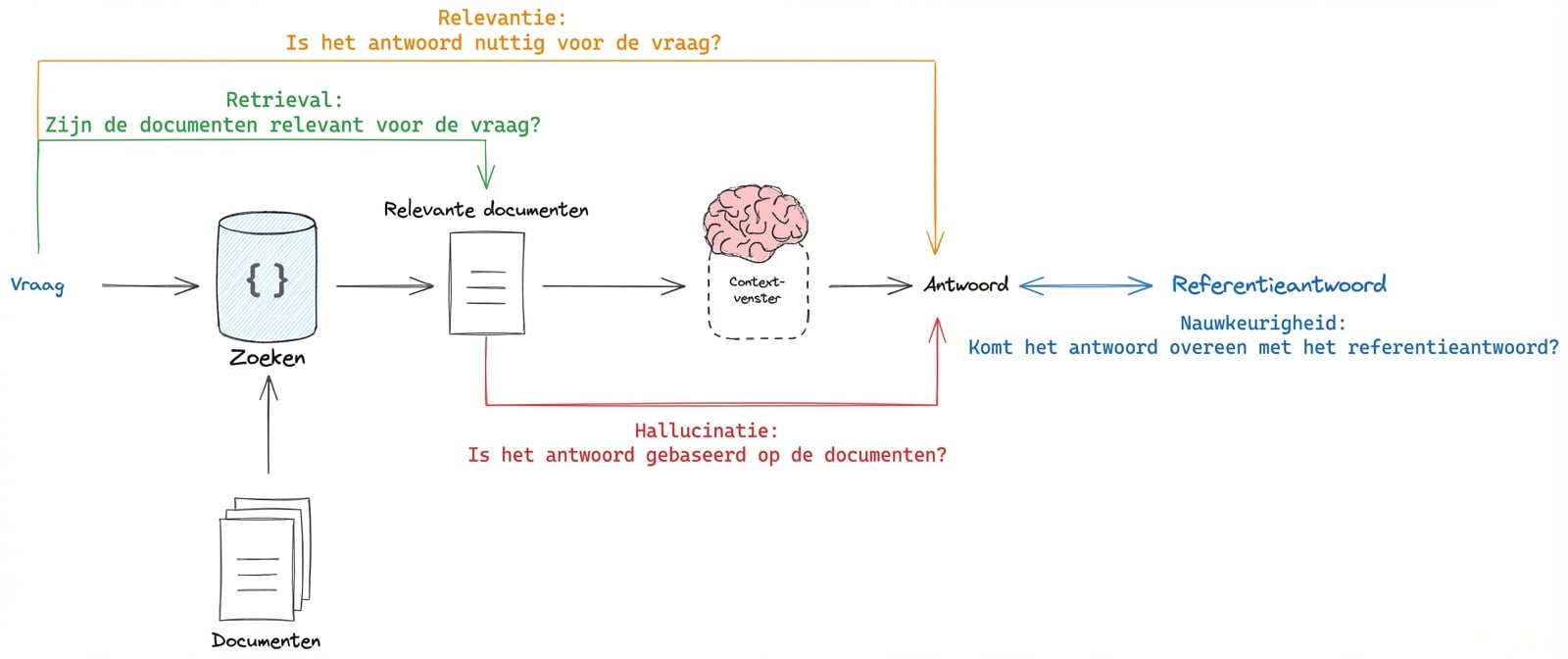
1 Beeldbron: LangSmith
Outputnauwkeurigheid: stringevaluatie
query = "What are the main components of RAG architecture?"
predicted_answer = "Training and encoding"
ref_answer = "Retrieval and Generation"
Outputnauwkeurigheid: stringevaluatie
prompt_template = """You are an expert professor specialized in grading students' answers to questions.
You are grading the following question:{query}
Here is the real answer:{answer}
You are grading the following predicted answer:{result}
Respond with CORRECT or INCORRECT:
Grade:"""
prompt = PromptTemplate(
input_variables=["query", "answer", "result"],
template=prompt_template
)
eval_llm = ChatOpenAI(temperature=0, model="gpt-4o-mini", openai_api_key='...')
Outputnauwkeurigheid: stringevaluatie
from langsmith.evaluation import LangChainStringEvaluator qa_evaluator = LangChainStringEvaluator( "qa", config={ "llm": eval_llm, "prompt": PROMPT } )score = qa_evaluator.evaluator.evaluate_strings( prediction=predicted_answer, reference=ref_answer, input=query )
Outputnauwkeurigheid: stringevaluatie
print(f"Score: {score}")
Score: {'reasoning': 'INCORRECT', 'value': 'INCORRECT', 'score': 0}
query = "What are the main components of RAG architecture?"
predicted_answer = "Training and encoding"
ref_answer = "Retrieval and Generation"
Ragas-framework
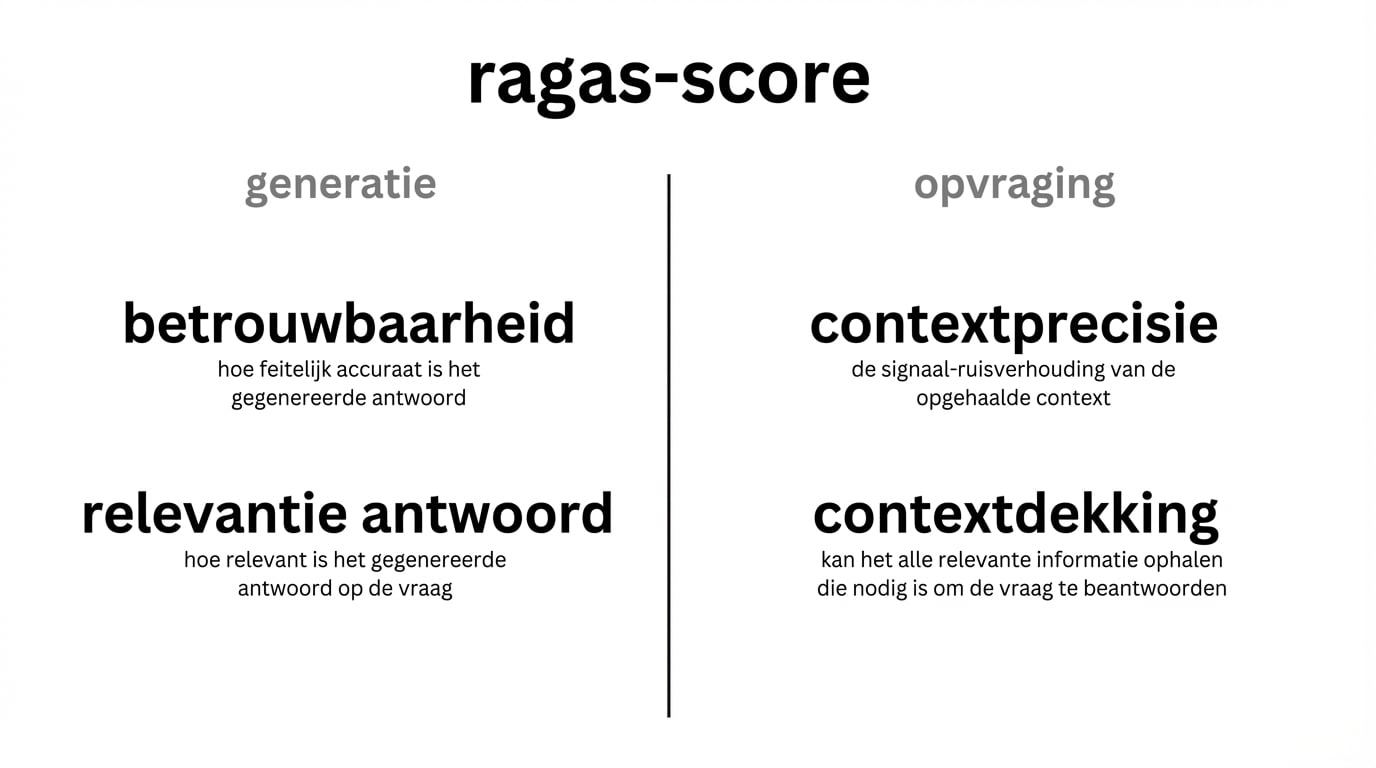
1 Beeldbron: Ragas
Faithfulness (getrouwheid)
- Geeft de gegenereerde output het contextmateriaal getrouw weer?
$$ \text{Faithfulness} = \frac{\text{Aantal beweringen afleidbaar uit de context}}{\text{Totaal aantal beweringen}} $$
- Genormaliseerd naar
(0, 1)
Getrouwheid evalueren
from langchain_openai import ChatOpenAI, OpenAIEmbeddingsfrom ragas.integrations.langchain import EvaluatorChain from ragas.metrics import faithfulnessllm = ChatOpenAI(model="gpt-4o-mini", api_key="...") embeddings = OpenAIEmbeddings(model="text-embedding-3-small", api_key="...")faithfulness_chain = EvaluatorChain( metric=faithfulness, llm=llm, embeddings=embeddings )
Getrouwheid evalueren
eval_result = faithfulness_chain({"question": "How does the RAG model improve question answering with LLMs?","answer": "The RAG model improves question answering by combining the retrieval of documents...","contexts": [ "The RAG model integrates document retrieval with LLMs by first retrieving relevant passages...", "By incorporating retrieval mechanisms, RAG leverages external knowledge sources, allowing the...", ]})print(eval_result)
'faithfulness': 1.0
Context precision
- Hoe relevant zijn de opgehaalde documenten voor de query?
- Genormaliseerd naar
(0, 1)→1= zeer relevant
from ragas.metrics import context_precision
llm = ChatOpenAI(model="gpt-4o-mini", api_key="...")
embeddings = OpenAIEmbeddings(model="text-embedding-3-small", api_key="...")
context_precision_chain = EvaluatorChain(
metric=context_precision,
llm=llm,
embeddings=embeddings
)
Context precision evalueren
eval_result = context_precision_chain({ "question": "How does the RAG model improve question answering with large language models?", "ground_truth": "The RAG model improves question answering by combining the retrieval of...", "contexts": [ "The RAG model integrates document retrieval with LLMs by first retrieving...", "By incorporating retrieval mechanisms, RAG leverages external knowledge sources...", ] })print(f"Context Precision: {eval_result['context_precision']}")
Context Precision: 0.99999999995
Laten we oefenen!
Retrieval Augmented Generation (RAG) met LangChain

