Tekstsplitsing, embeddings en vectoropslag
Retrieval Augmented Generation (RAG) met LangChain

Meri Nova
Machine Learning Engineer
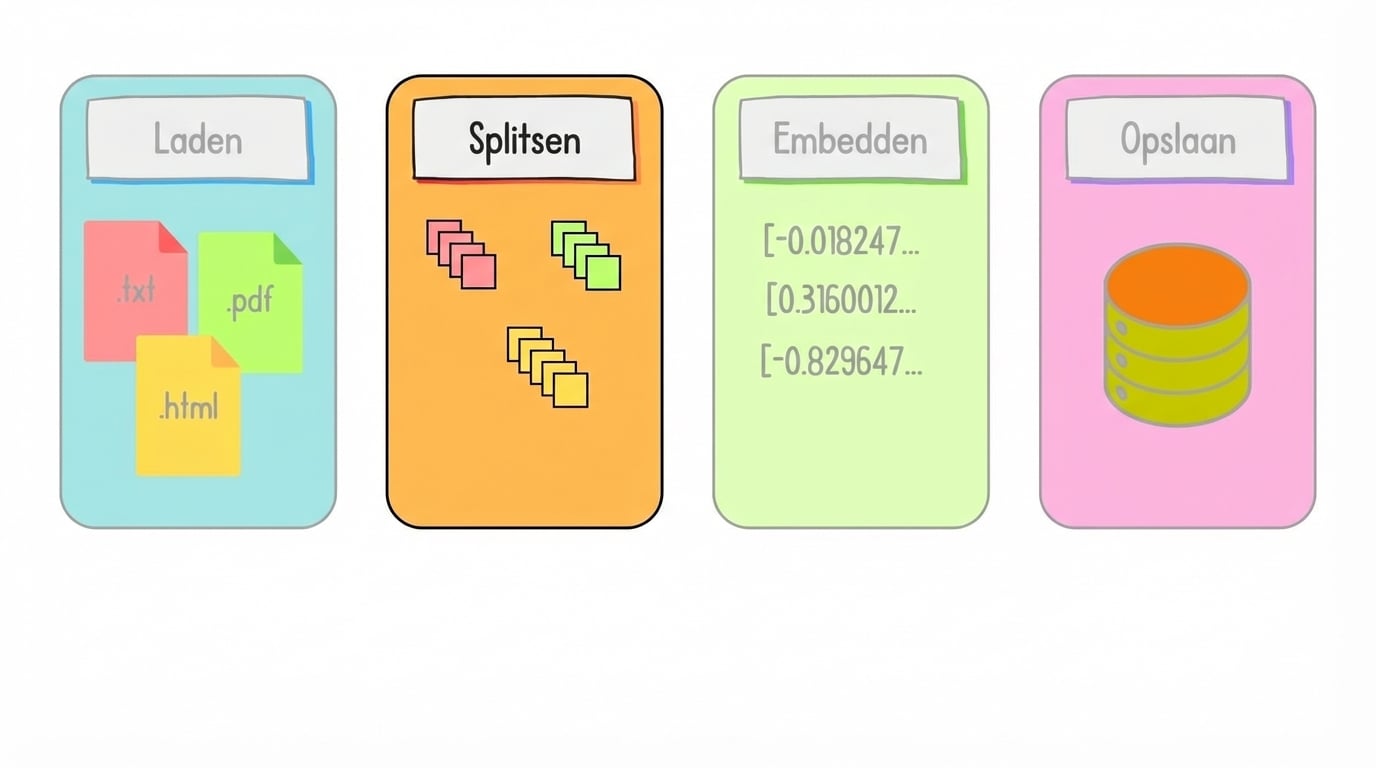
Data voorbereiden voor retrieval

Data voorbereiden voor retrieval
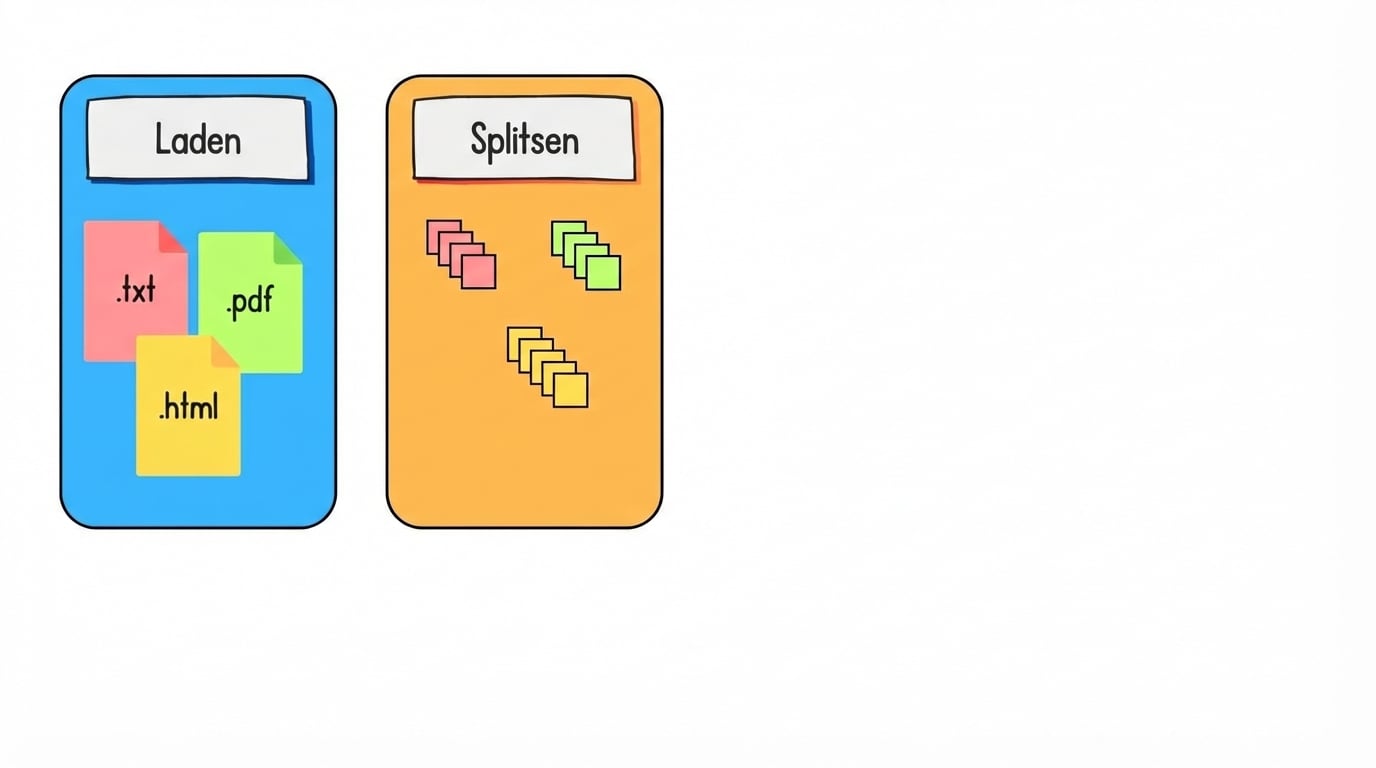
Data voorbereiden voor retrieval
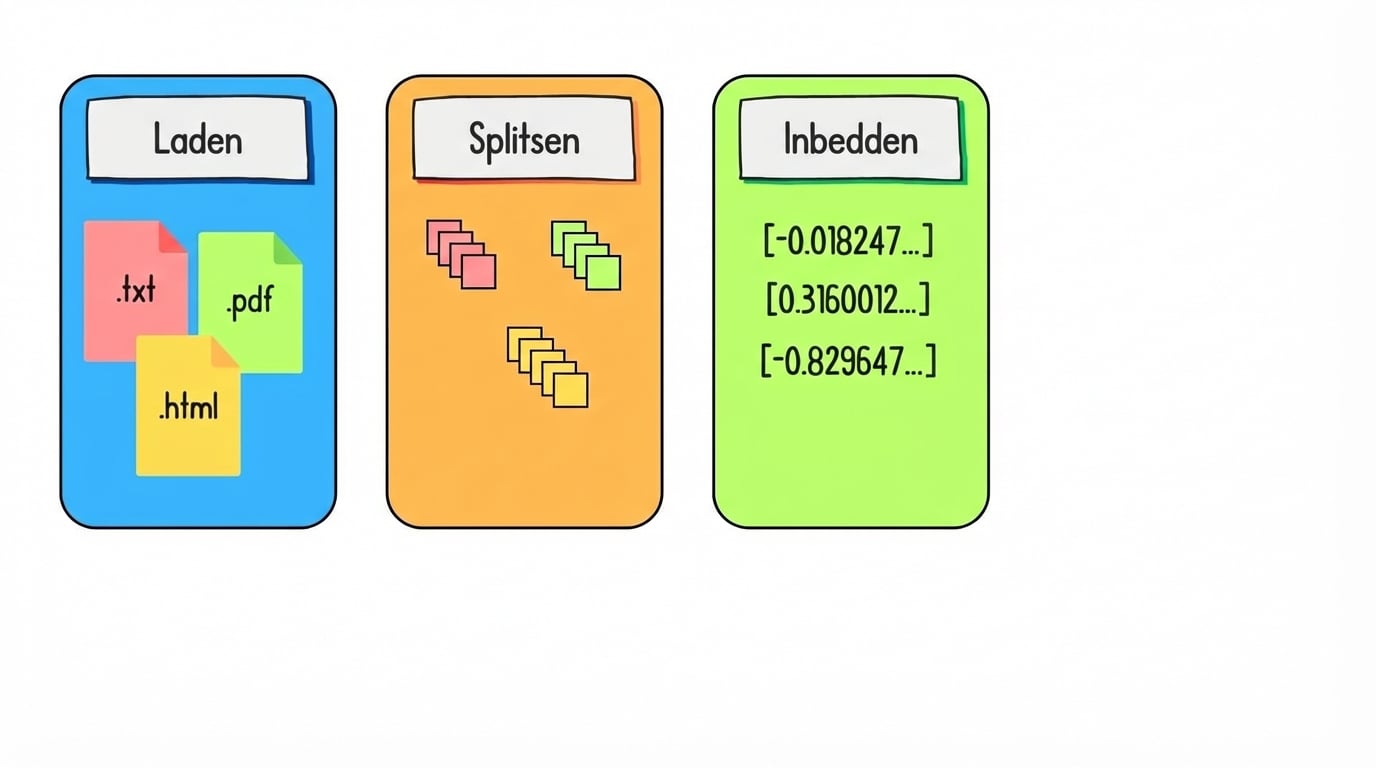
Data voorbereiden voor retrieval
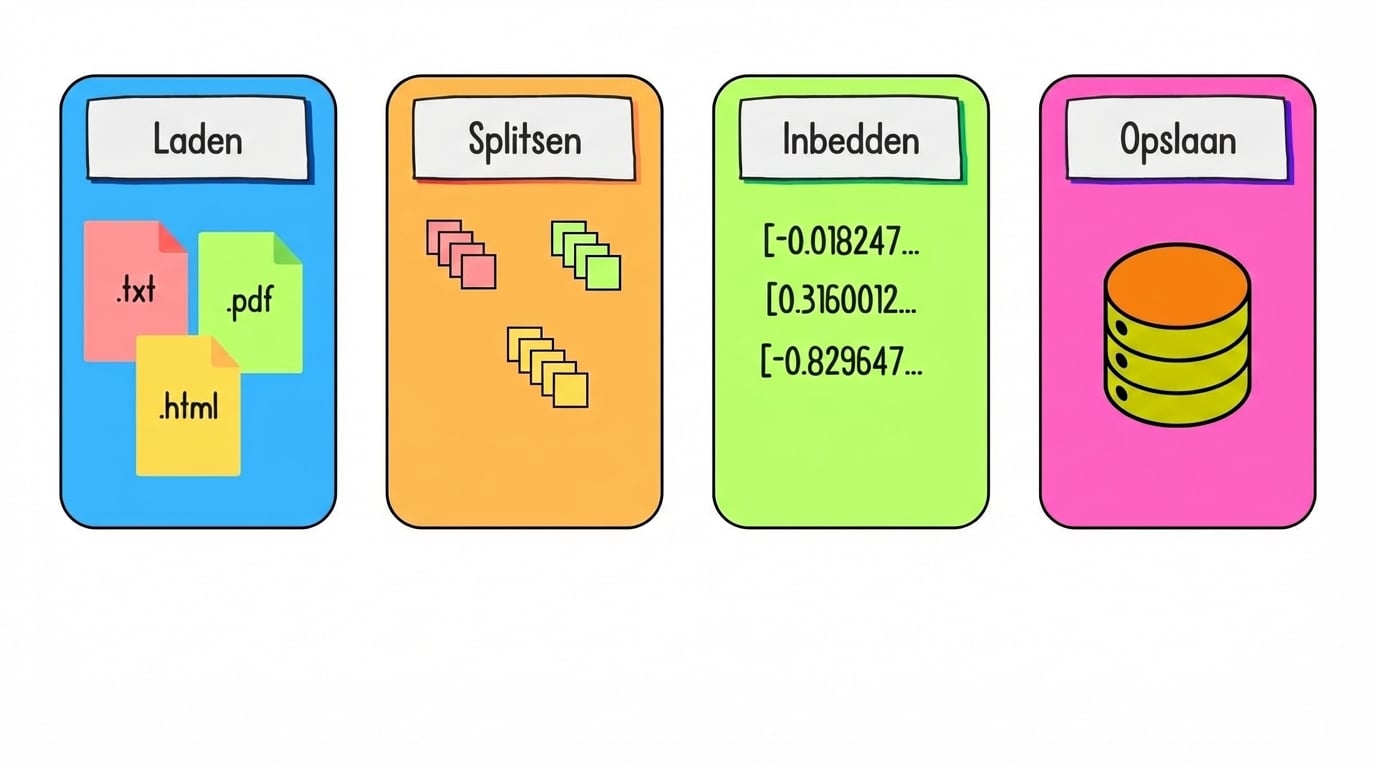
Data voorbereiden voor retrieval
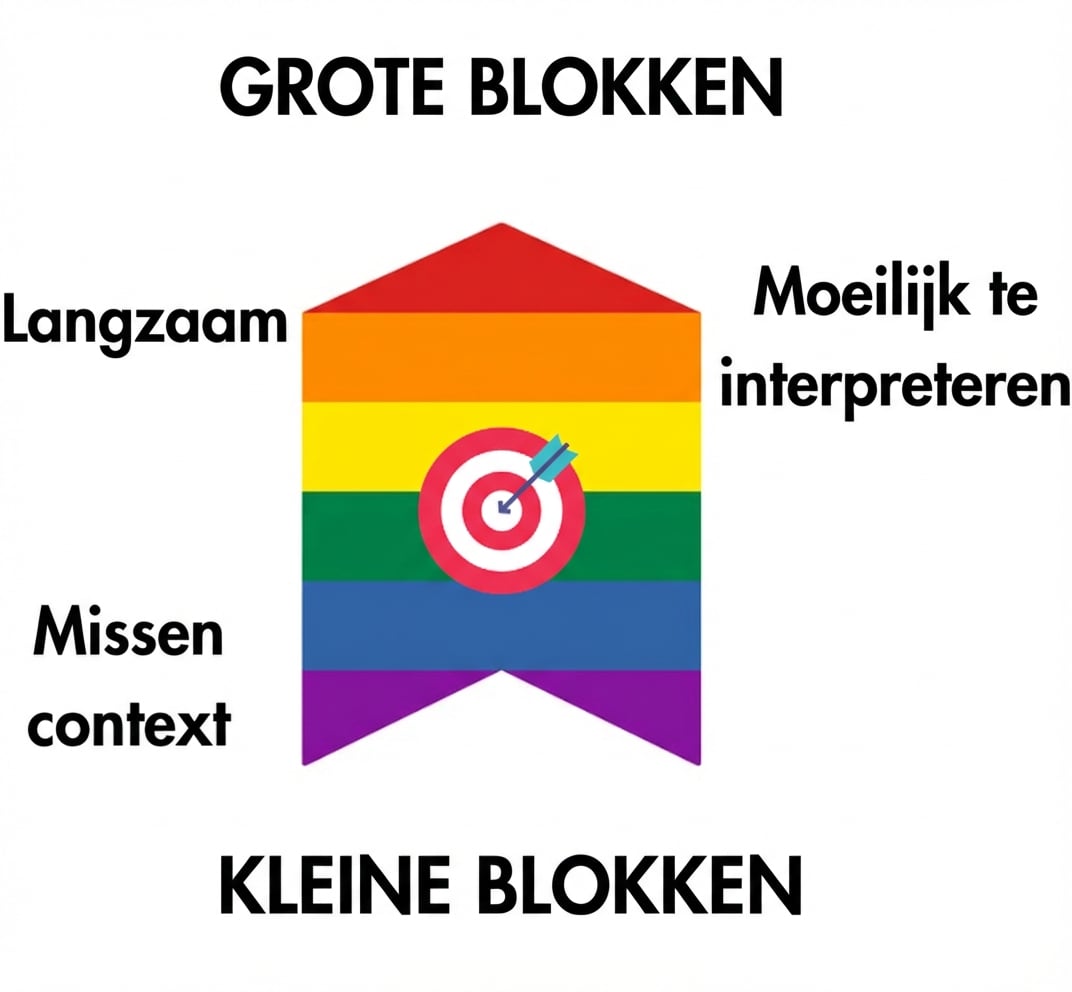
chunk_size
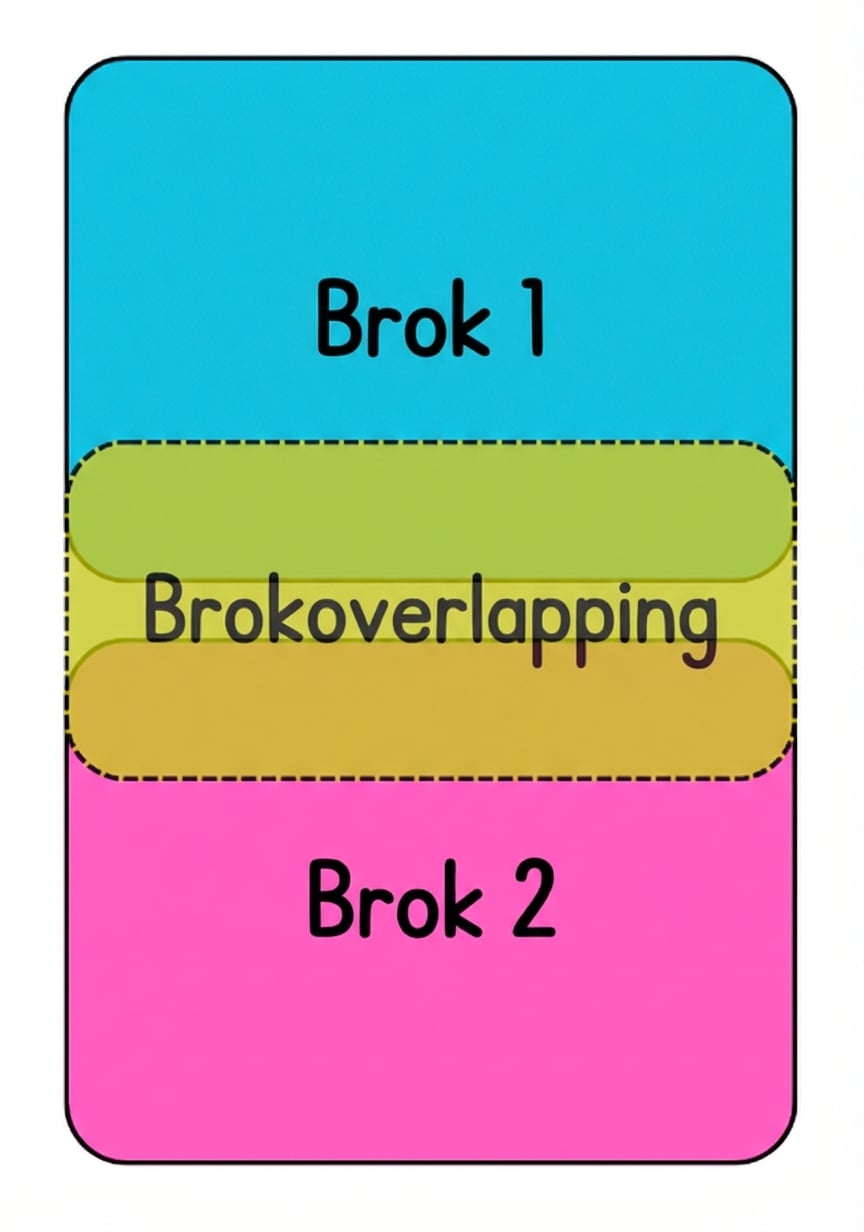
chunk_overlap
- Neem info op die over de grens gaat
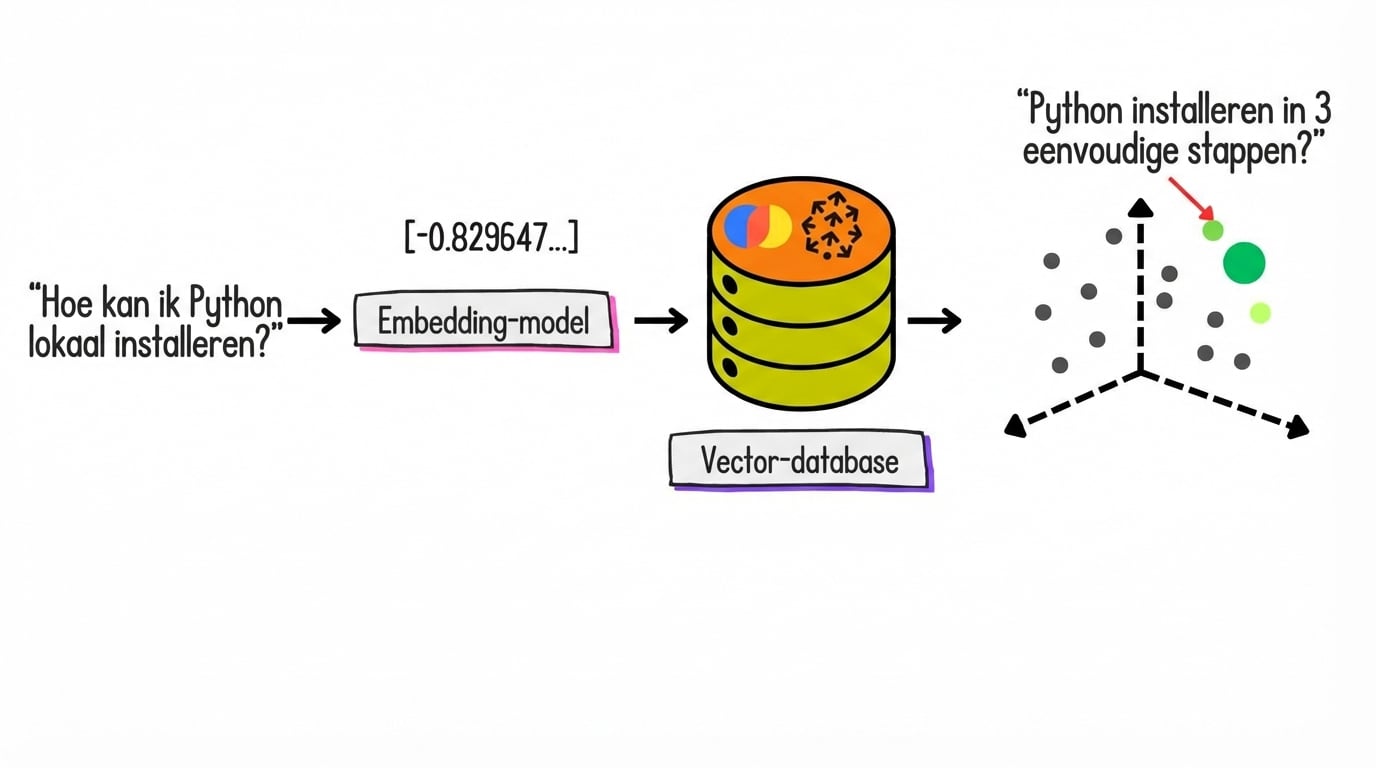
Embeddings en opslag
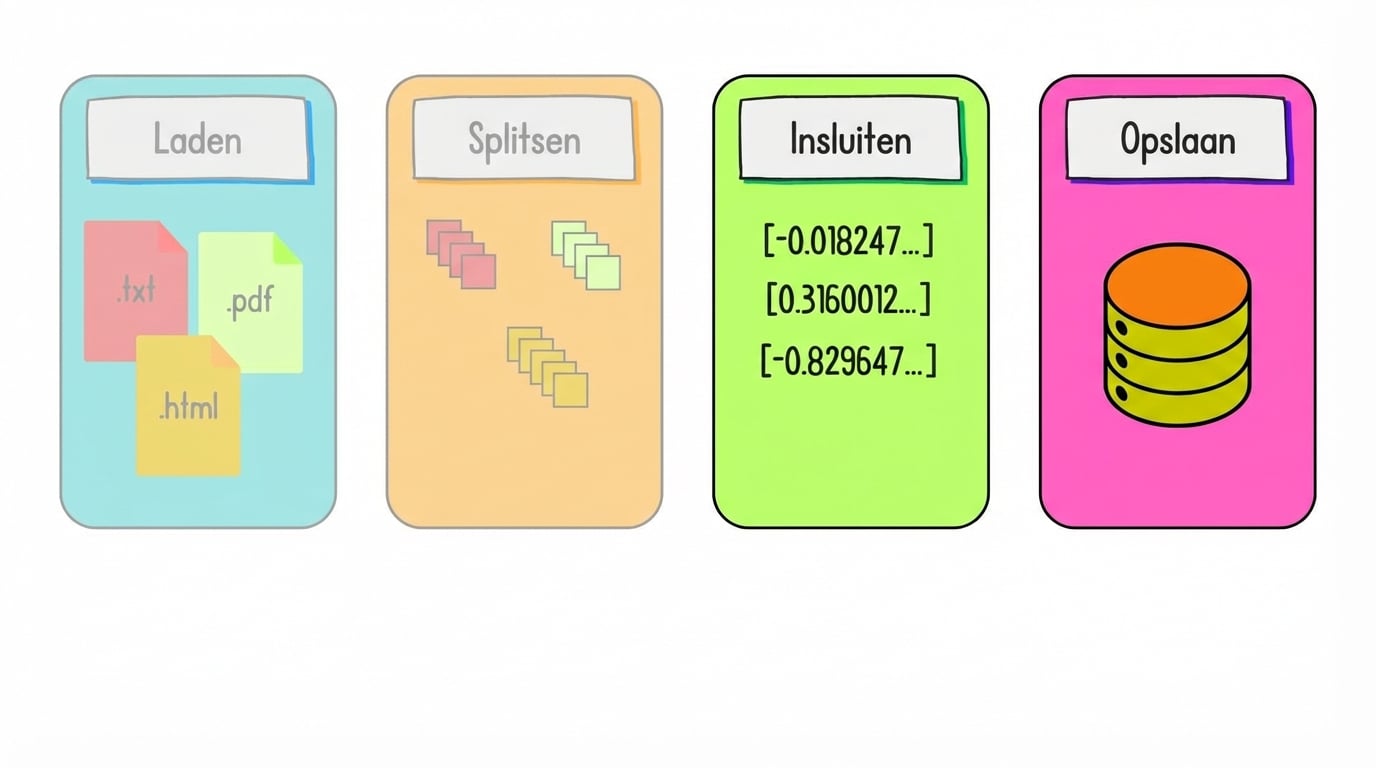
Wat zijn embeddings?
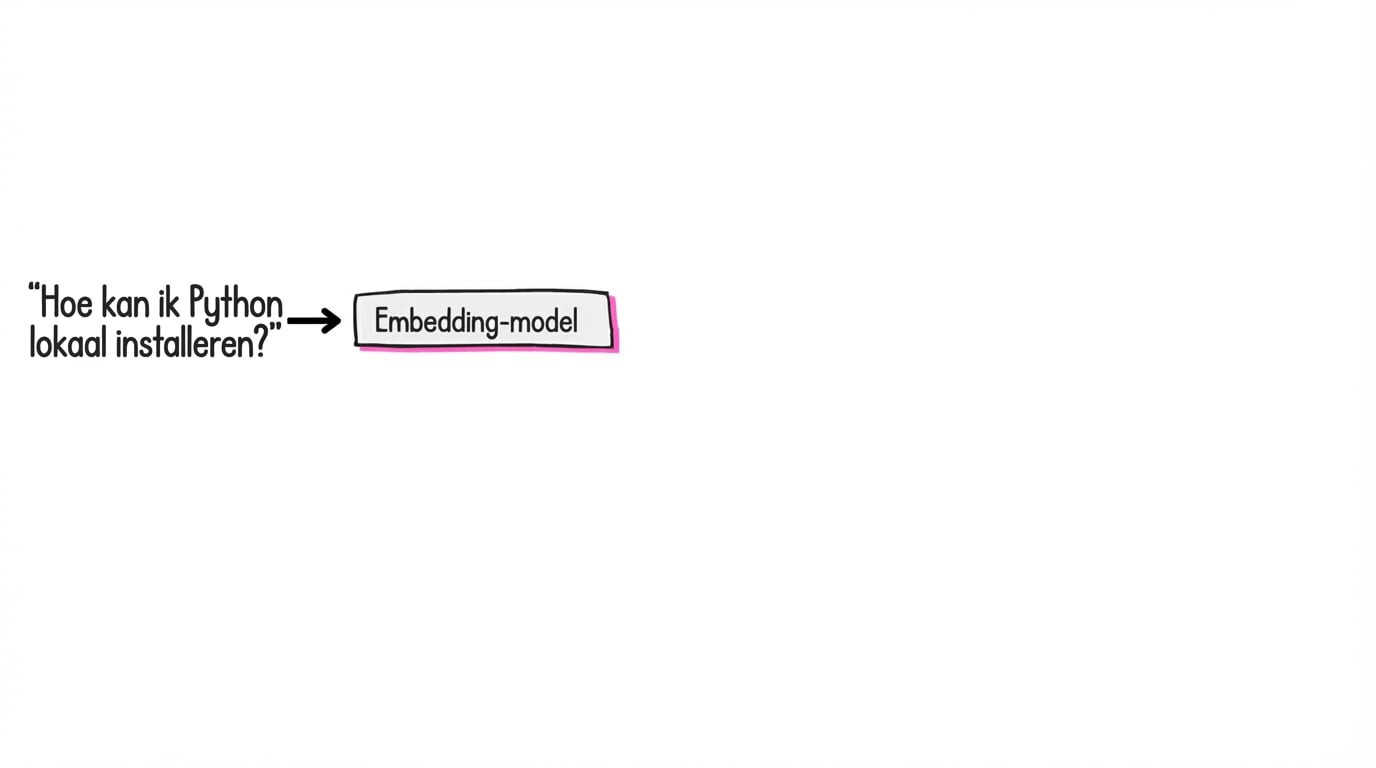
Wat zijn embeddings?
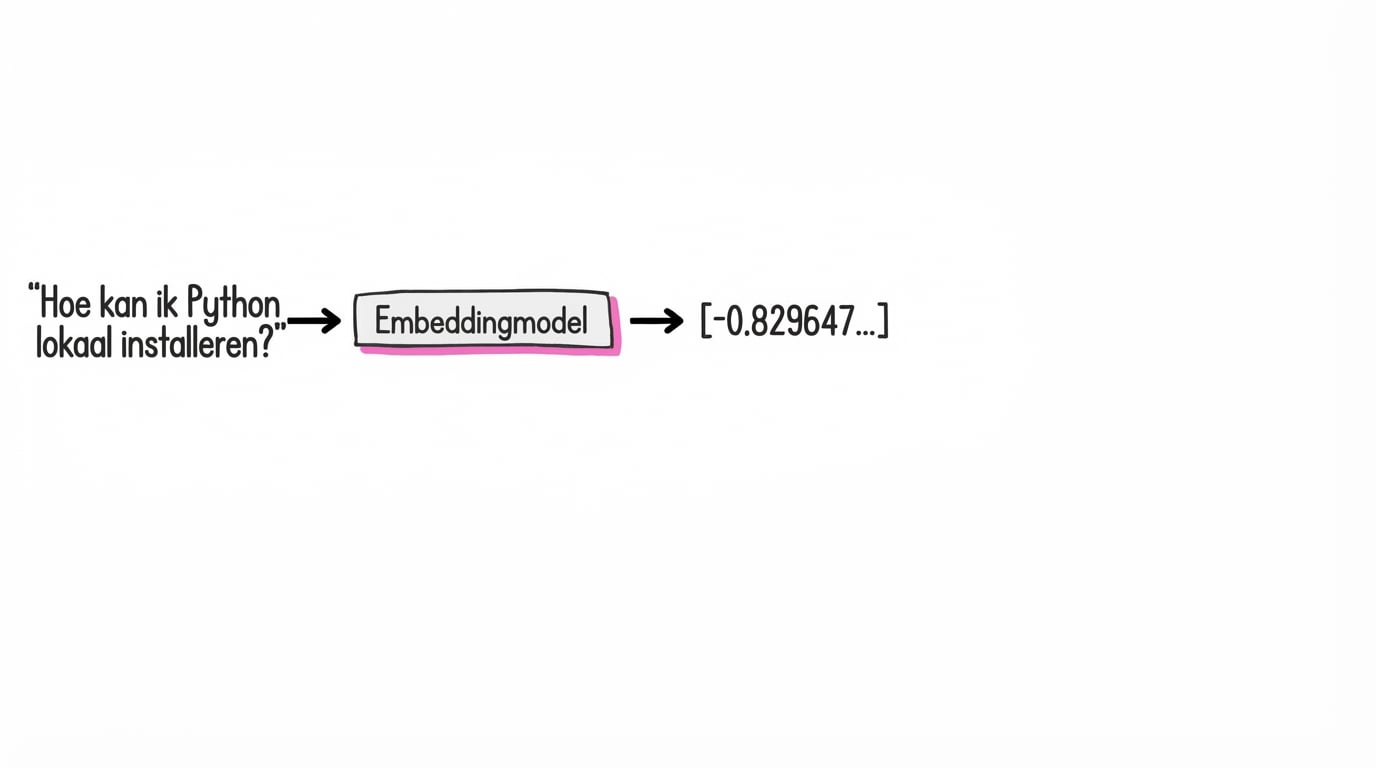
Wat zijn embeddings?
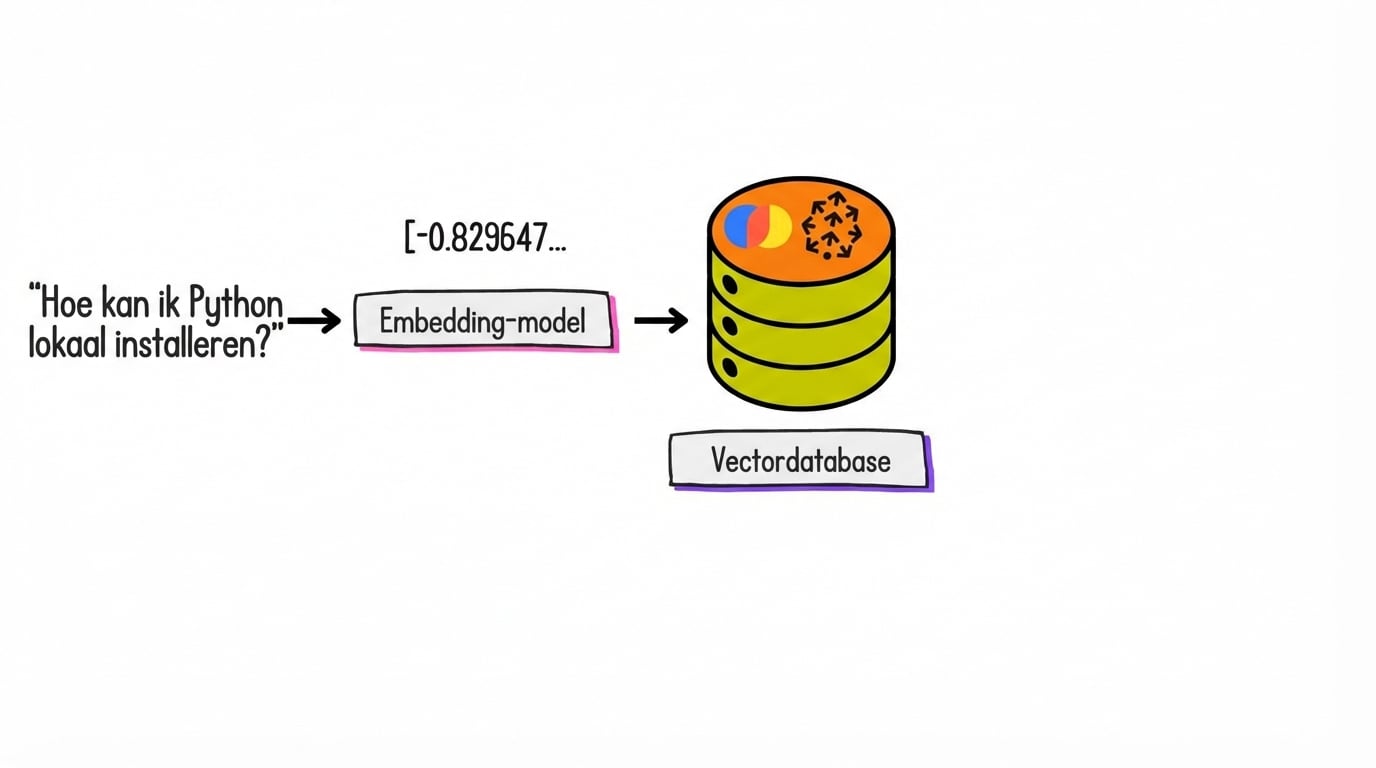
Wat zijn embeddings?