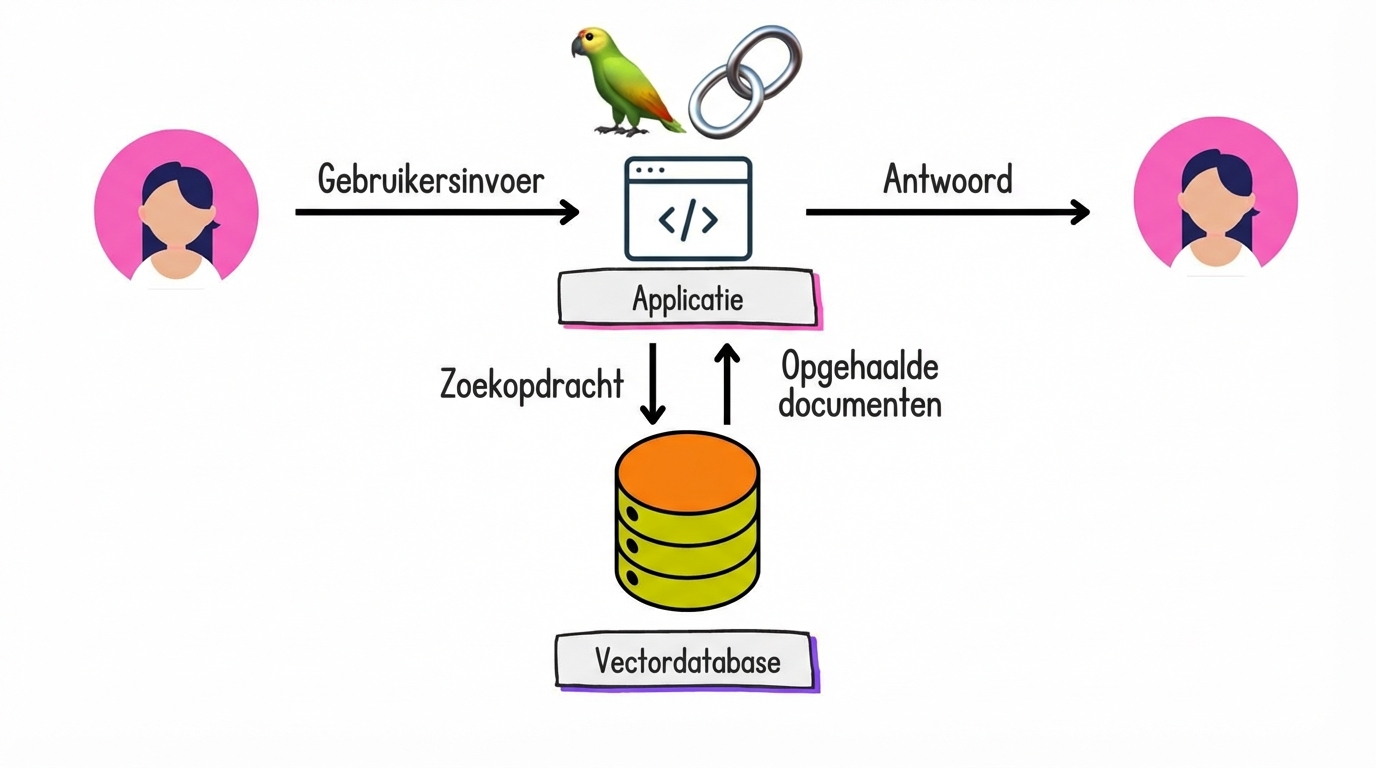
Documentopvraging optimaliseren
Retrieval Augmented Generation (RAG) met LangChain

Meri Nova
Machine Learning Engineer
De R van RAG...
Dense
Codeer chunks als één vector met niet-nul componenten
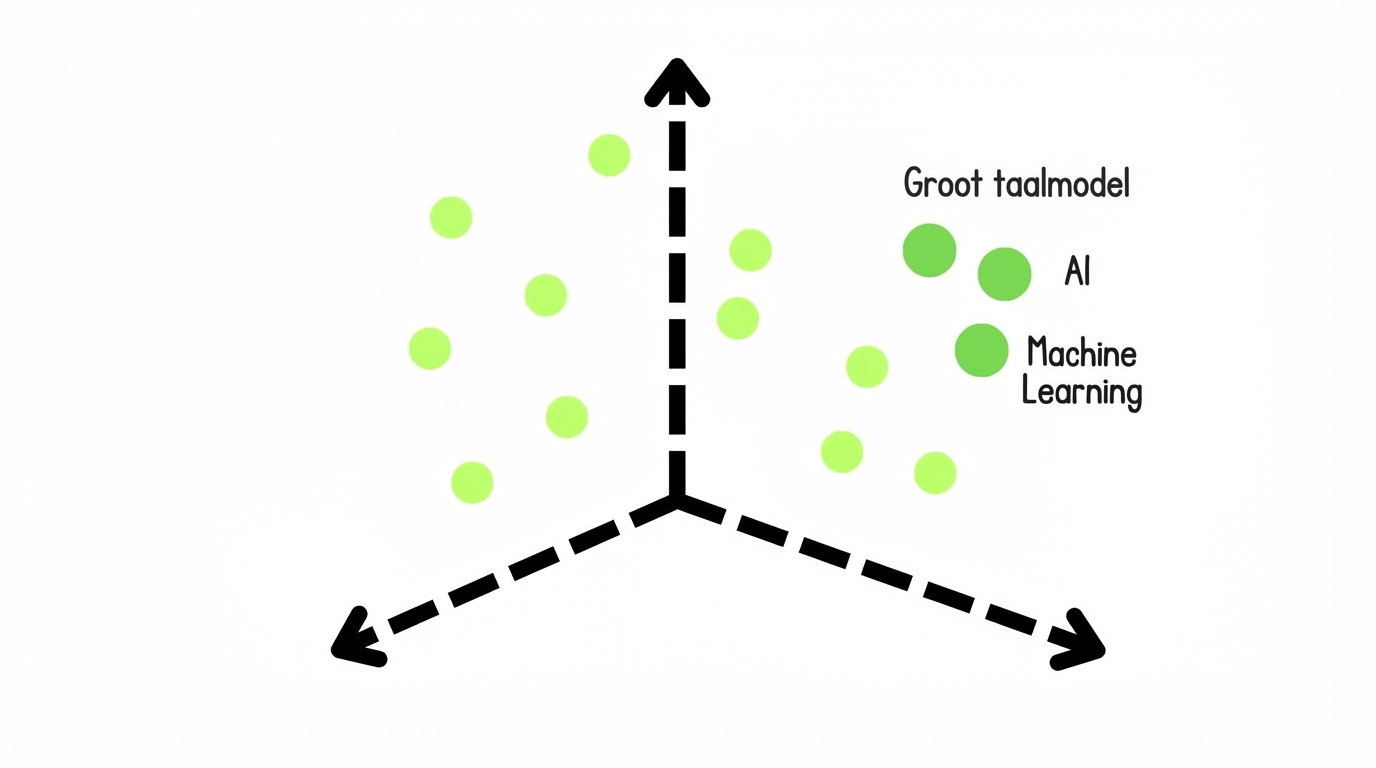
- Voordelen: Vangt semantiek
- Nadelen: Rekenintensief
Dense
Codeer chunks als één vector met niet-nul componenten
- Voordelen: Vangt semantiek
- Nadelen: Rekenintensief
Sparse
Codeer met woordovereenkomst met vooral nul componenten
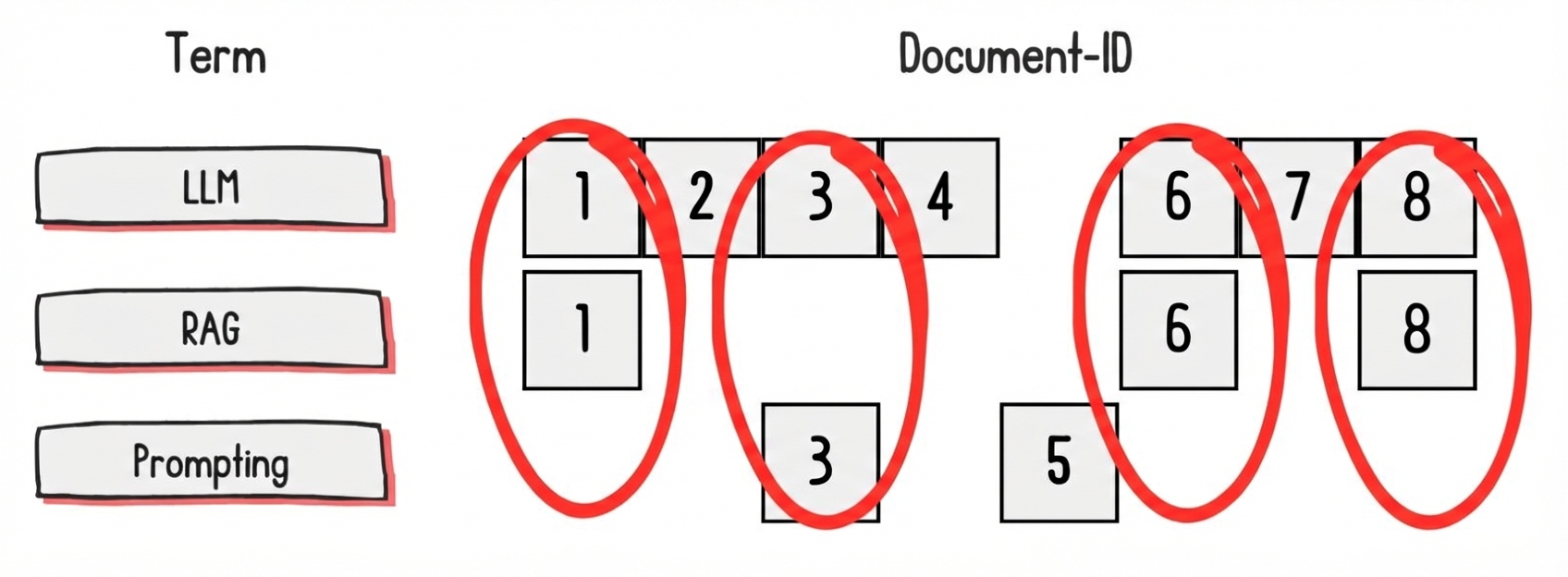
- Voordelen: Precies, uitlegbaar, zeldzame-woordverwerking
- Nadelen: Generaliseerbaarheid
Sparse-opvraagmethoden
TF-IDF: Codeert documenten via woorden die het document uniek maken
BM25: Dempt effect van zeer frequente woorden in de encoding

