Exploratory Data Analysis
End-to-End Machine Learning

Joshua Stapleton
Machine Learning Engineer
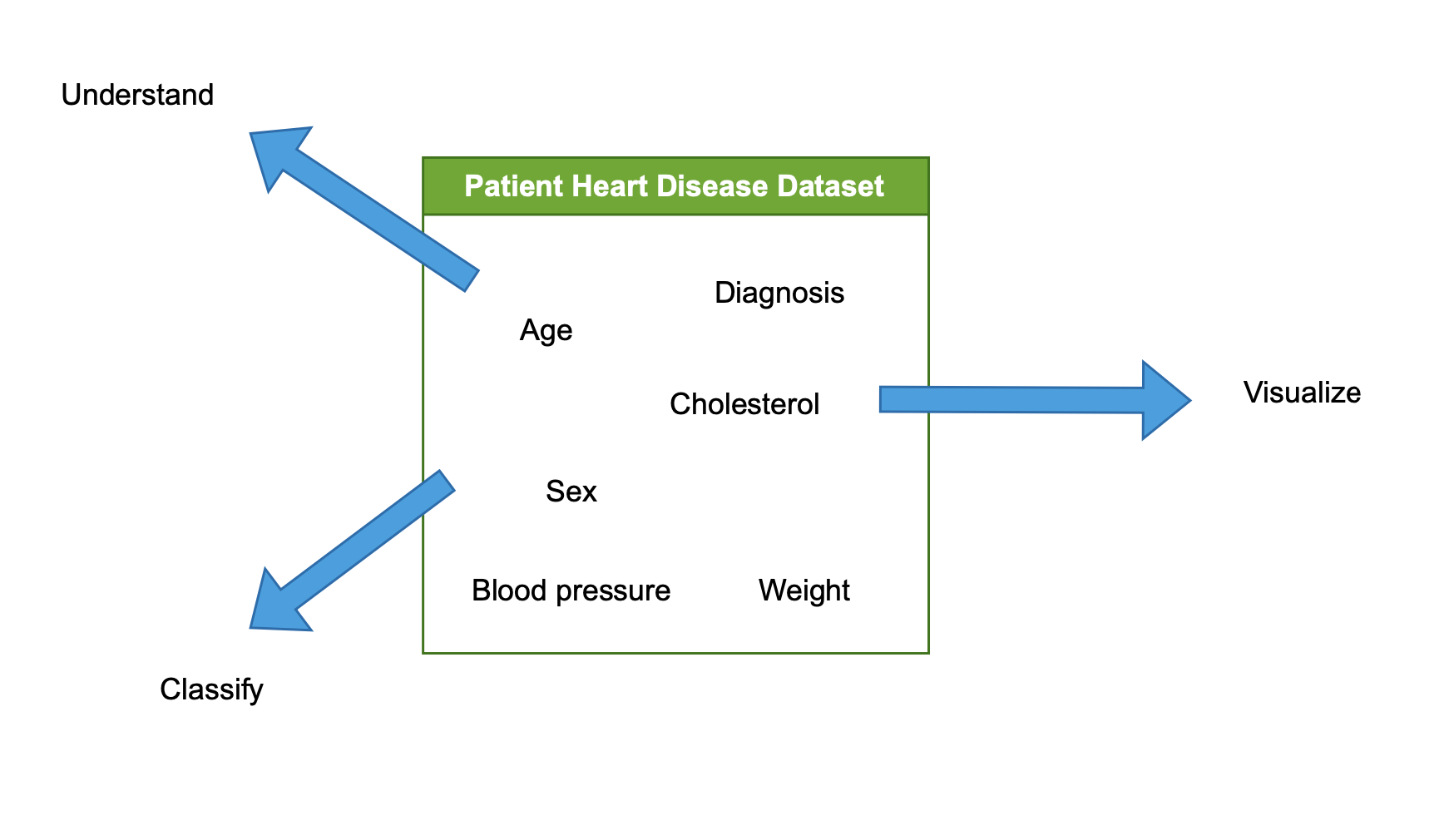
Het EDA-proces
- Onderzoek en analyseer de dataset
- Begrijp de dataset
- Visualiseer de dataset
- Karakteriseer / classificeer de dataset
Onze data begrijpen
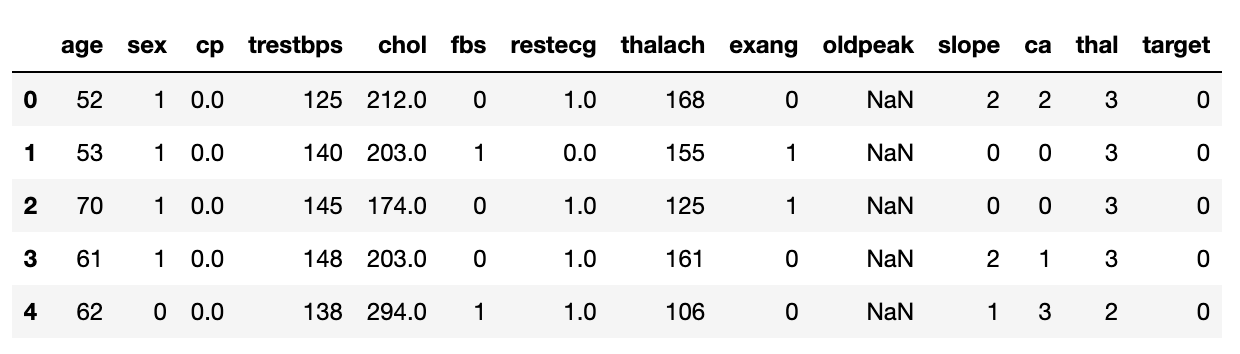
df.head()
- Toont de eerste rijen
- Geeft snel beeld van de structuur
# Print de eerste 5 rijen
print(heart_disease_df.head())
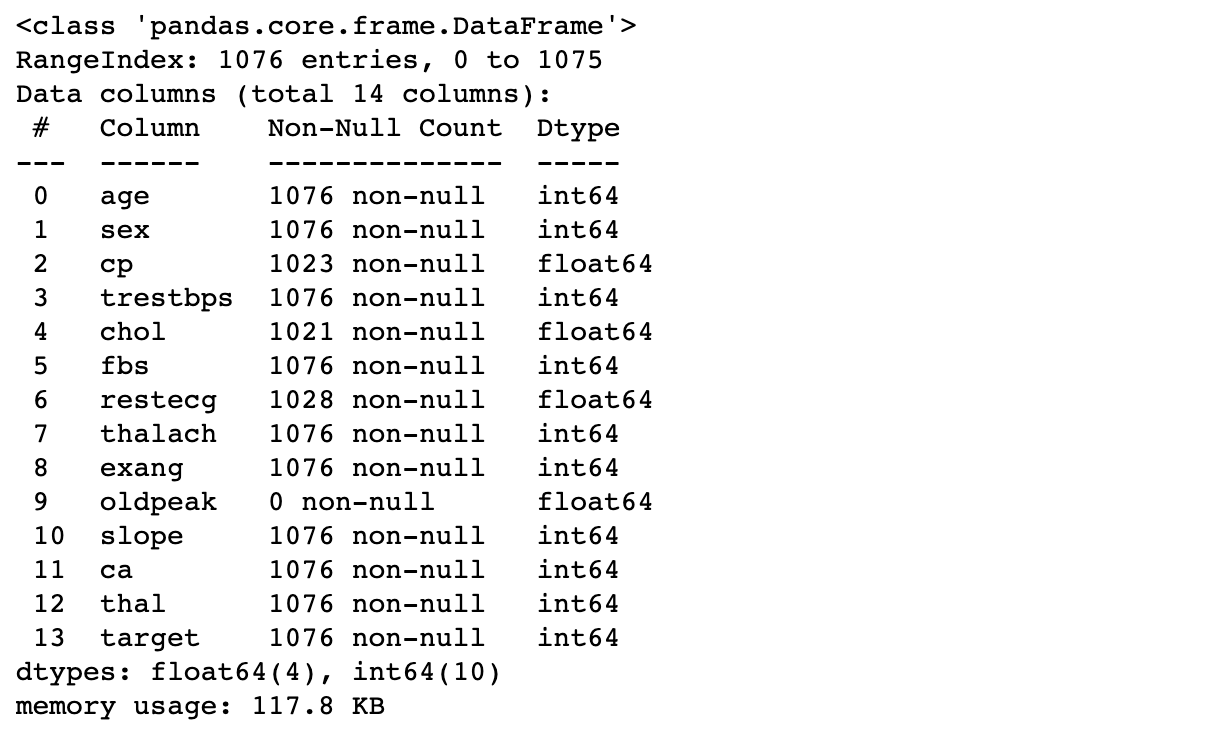
df.info()
- Vat kenmerken samen
- Toont non-null entries en types
# Print details
print(heart_disease_df.info())
Klasse-(on)balans
df.value_counts()
- Telt unieke voorkomens per klasse
- Klasse: binaire aanwezigheid van hartziekte (1/0)
- Belangrijk voor modelleren
# print de class balance
print(heart_disease_df['target'].value_counts(normalize=True))

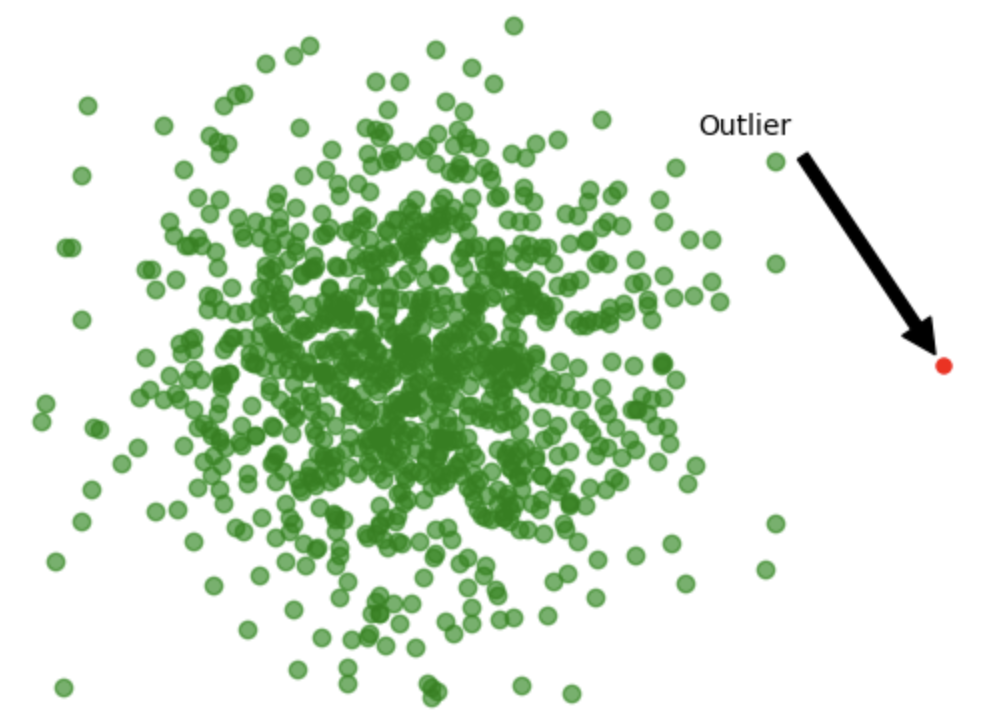
Uitschieters
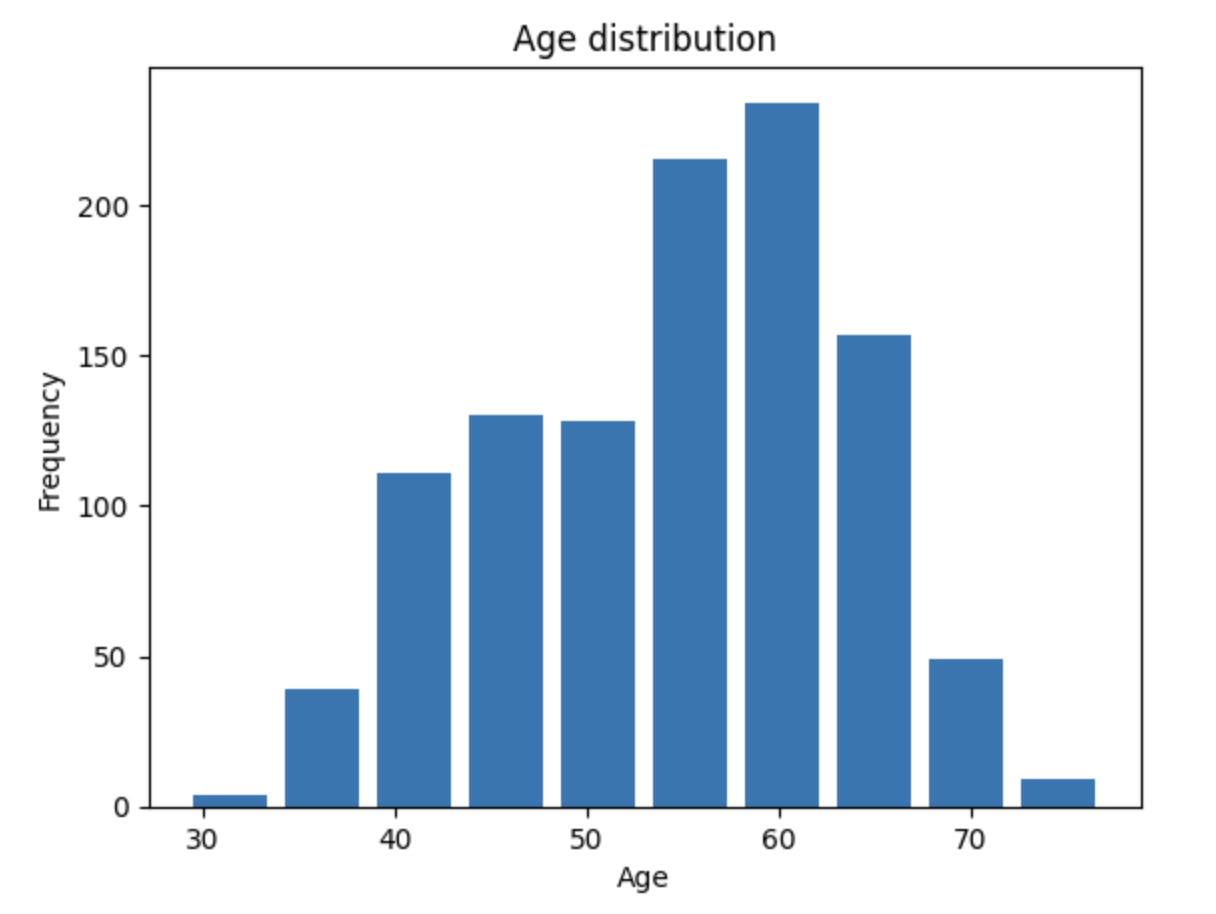
Onze data visualiseren
df['age'].plot(kind='hist')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.show()
1 https://seaborn.pydata.org/tutorial/distributions.html, https://app.datacamp.com/learn/courses/intermediate-data-visualization-with-seaborn

