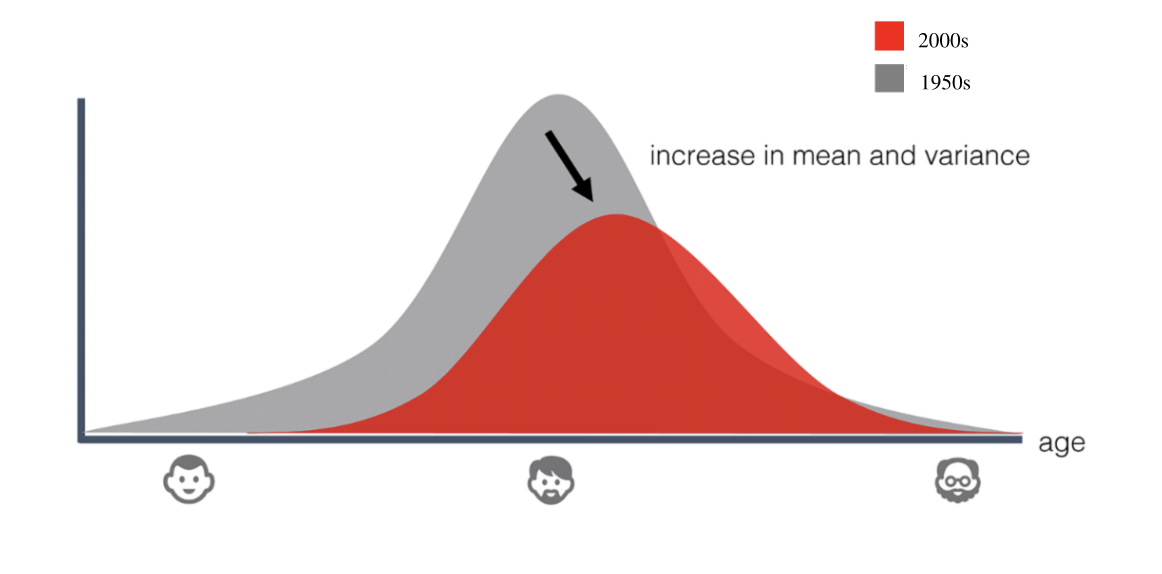
End-to-End Machine Learning
Joshua Stapleton
Machine Learning Engineer
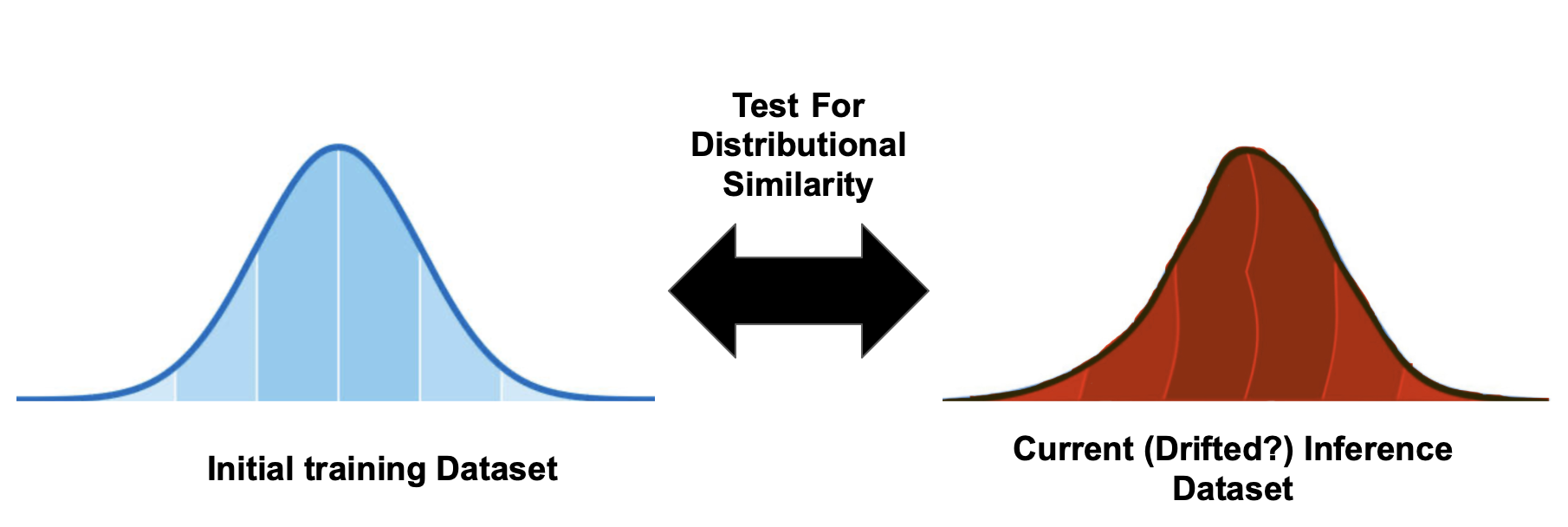
ks_2samp()
from scipy.stats import ks_2samp
# load the 1D data distribution samples for comparison sample_1, sample_2 = training_dataset_sample, current_inference_sample
# perform the KS-test - ensure input samples are numpy arrays test_statistic, p_value = ks_2samp(sample_1, sample_2)
if p_value < 0.05: print("Reject null hypothesis - data drift might be occuring") else: print("Samples are likely to be from the same dataset")
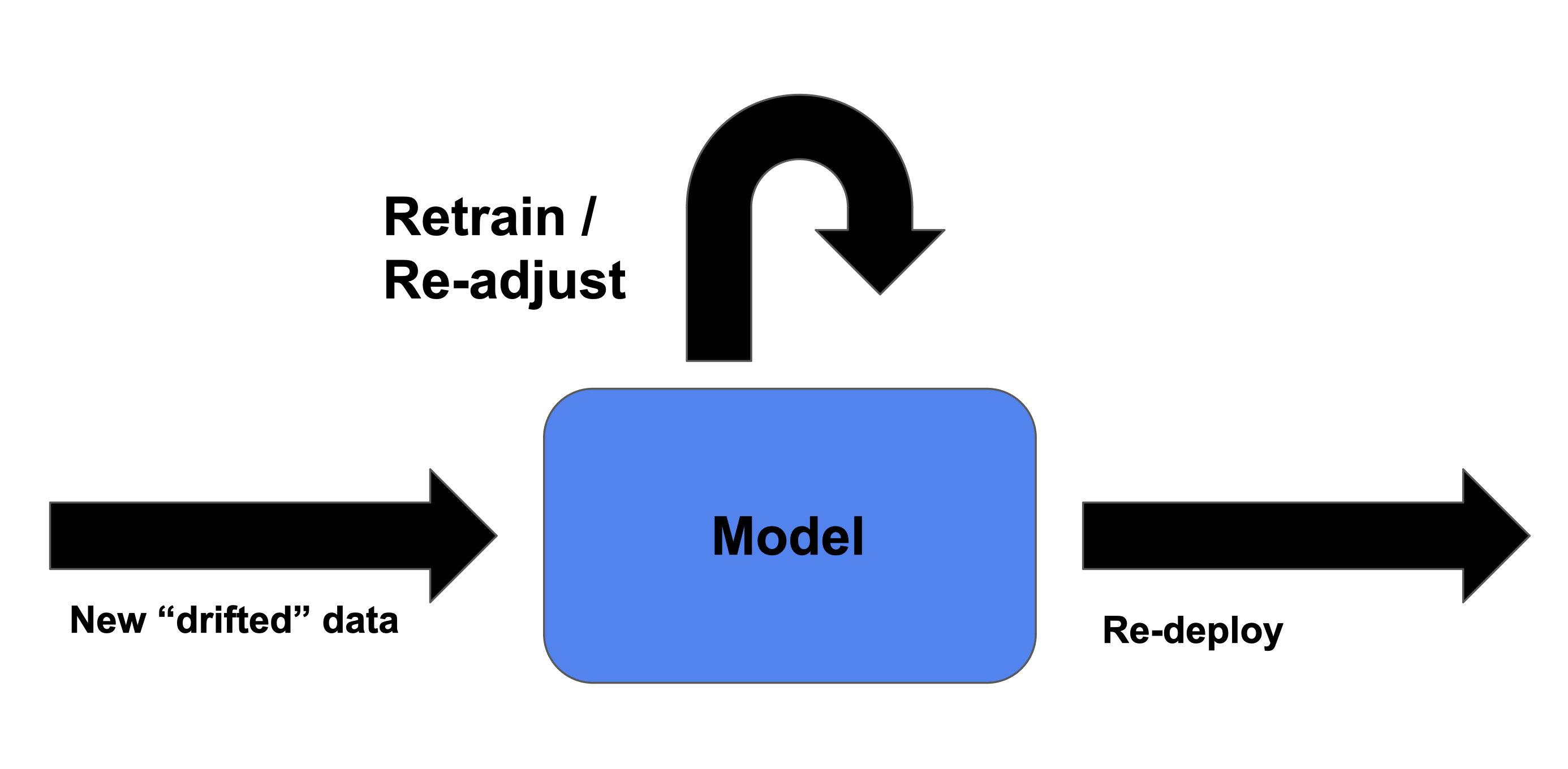
Model updaten voor nieuwe data
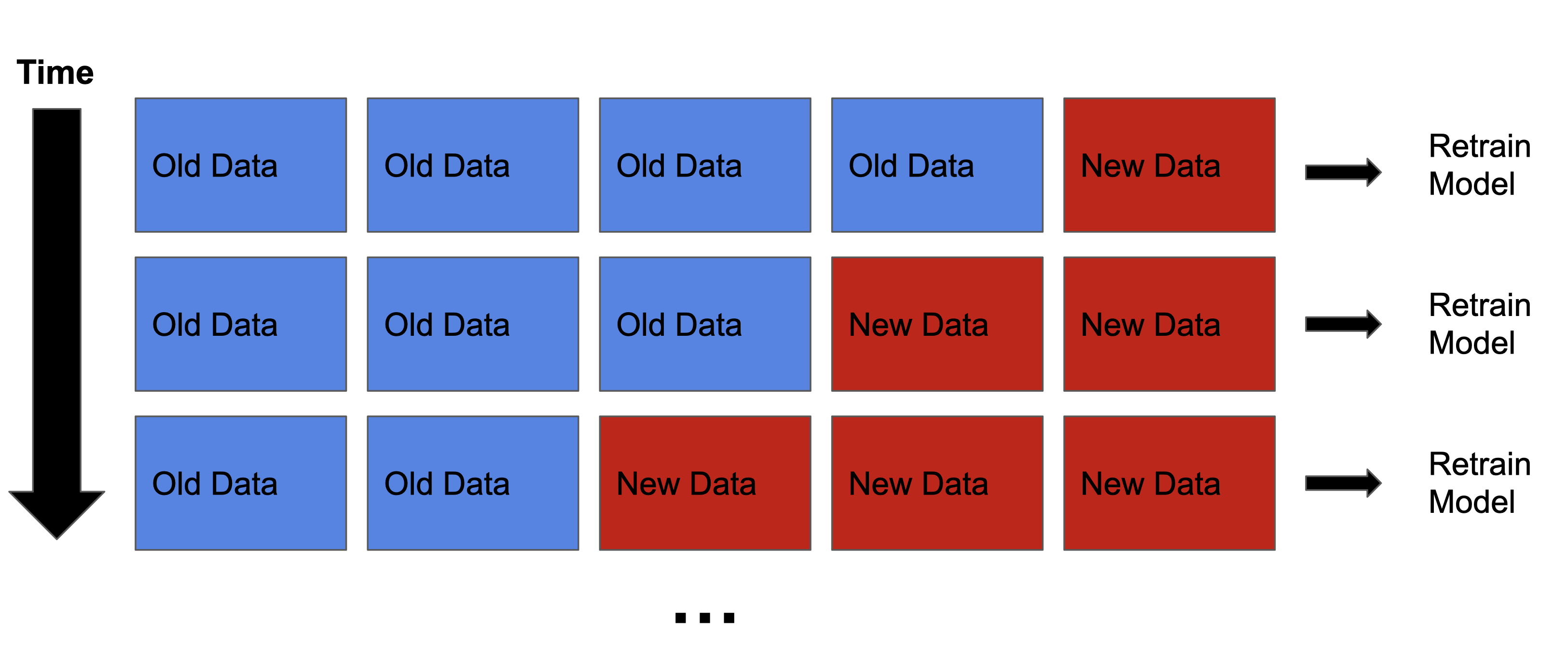
Te weinig nieuwe/inferentiedata?