Feature engineering en selectie
End-to-End Machine Learning

Joshua Stapleton
Machine Learning Engineer
Feature engineering
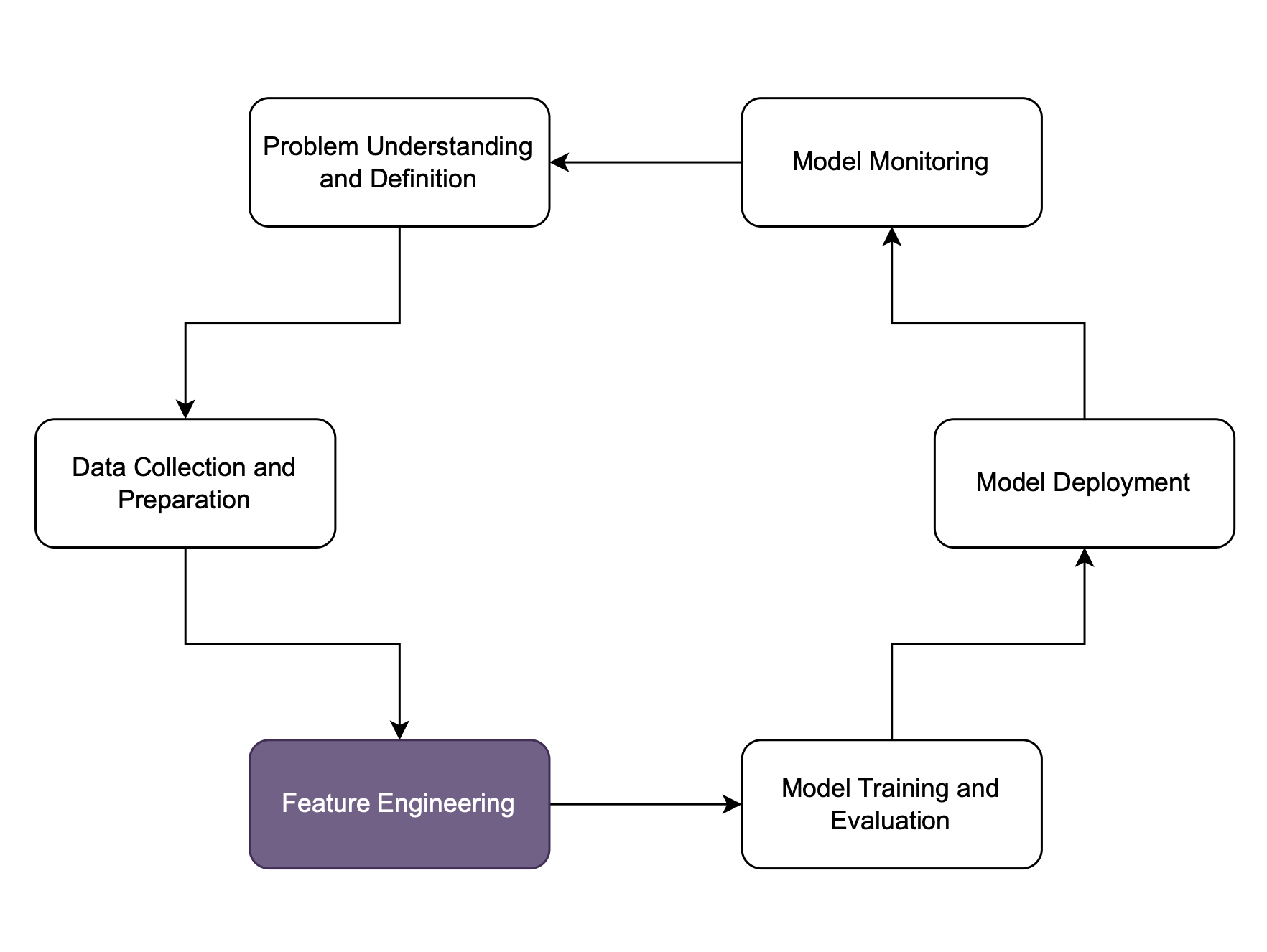
Wat is een goede feature?
- Gebruik relevante features
- Het weer op de dag van de afspraak zegt niets over de diagnose

- Gebruik afwijkende (orthogonale) features
- Twee features: leeftijd in maanden en in jaren helpen niet