Big Data Fundamentals met PySpark
Upendra Devisetty
Science Analyst, CyVerse
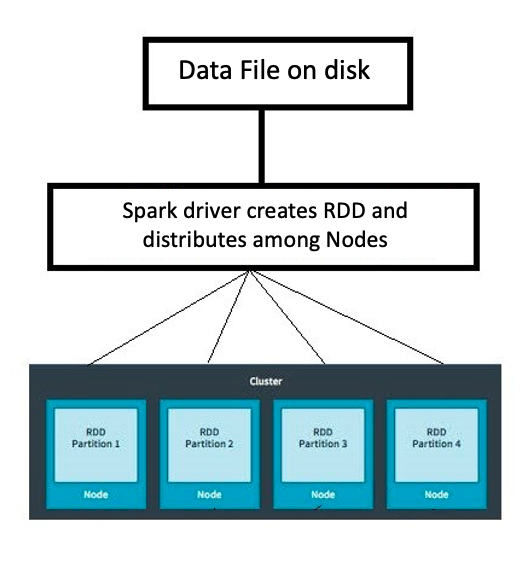
Resilient Distributed Datasets
Resilient: kan storingen opvangen
Distributed: over meerdere machines verdeeld
Datasets: verzameling gepartitioneerde data, bijv. arrays, tabellen, tuples, enz.
Een bestaande collectie objecten paralleliseren
Externe datasets:
Bestanden in HDFS
Objecten in een Amazon S3-bucket
regels in een tekstbestand
Vanuit bestaande RDD’s
parallelize()
numRDD = sc.parallelize([1,2,3,4])
helloRDD = sc.parallelize("Hello world")
type(helloRDD)
<class 'pyspark.rdd.PipelinedRDD'>
textFile()
fileRDD = sc.textFile("README.md")
type(fileRDD)
Een partitie is een logische verdeling van een grote, gedistribueerde dataset
methode parallelize()
numRDD = sc.parallelize(range(10), minPartitions = 6)
fileRDD = sc.textFile("README.md", minPartitions = 6)
getNumPartitions()