RDD-bewerkingen in PySpark
Big Data Fundamentals met PySpark

Upendra Devisetty
Science Analyst, CyVerse
Overzicht van PySpark-bewerkingen

- Transformaties maken nieuwe RDD’s
- Acties voeren berekeningen uit op RDD’s
RDD-transformaties
- Transformaties volgen lazy evaluation

Basis-RDD-transformaties
map(),filter(),flatMap()enunion()
map()-transformatie
- De map()-transformatie past een functie toe op alle elementen in het RDD
![]()
RDD = sc.parallelize([1,2,3,4])
RDD_map = RDD.map(lambda x: x * x)
filter()-transformatie
- De filter-transformatie geeft een nieuw RDD terug met alleen elementen die aan de voorwaarde voldoen

RDD = sc.parallelize([1,2,3,4])
RDD_filter = RDD.filter(lambda x: x > 2)
flatMap()-transformatie
- De flatMap()-transformatie geeft meerdere waarden per element van het oorspronkelijke RDD
![]()
RDD = sc.parallelize(["hello world", "how are you"])
RDD_flatmap = RDD.flatMap(lambda x: x.split(" "))
union()-transformatie
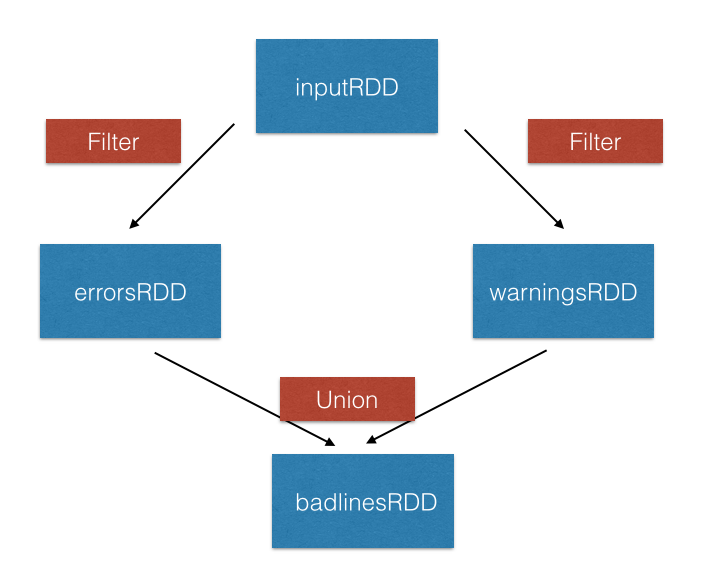
inputRDD = sc.textFile("logs.txt")
errorRDD = inputRDD.filter(lambda x: "error" in x.split())
warningsRDD = inputRDD.filter(lambda x: "warnings" in x.split())
combinedRDD = errorRDD.union(warningsRDD)

