Classificatie
Big Data Fundamentals met PySpark

Upendra Devisetty
Science Analyst, CyVerse
Classificatie met PySpark MLlib
- Classificatie is een supervised ML-algoritme dat invoer in categorieën indeelt
Introductie tot logistische regressie
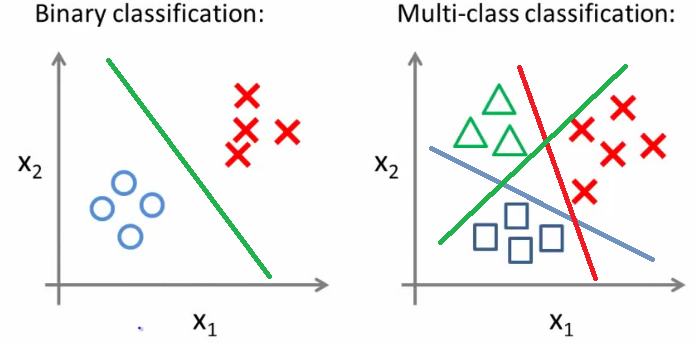
- Logistische regressie voorspelt een binaire uitkomst op basis van variabelen