Laden
Introductie tot Data Engineering

Vincent Vankrunkelsven
Data Engineer @ DataCamp
Databases voor analytics of applicaties
Analytics

- Aggregatie-queries
- Online Analytical Processing (OLAP)
Applicaties

- Veel transacties
- Online Transaction Processing (OLTP)
Kolom- vs. rij-georiënteerd
Analytics
- Kolom-georiënteerd

- Queries op subset van kolommen
- Parallelisatie
Applicaties
- Rij-georiënteerd
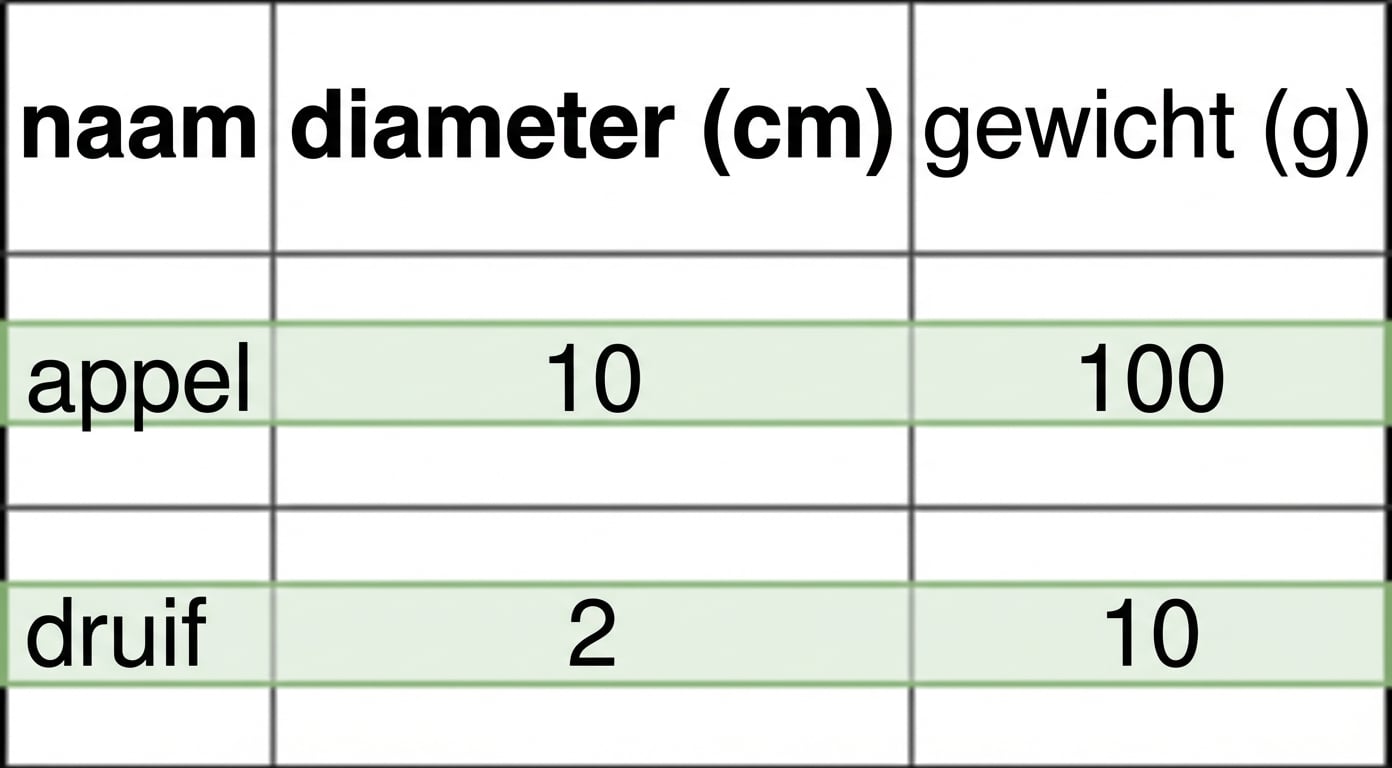
- Per record opgeslagen
- Per transactie toegevoegd
- Bijv. klant toevoegen is snel
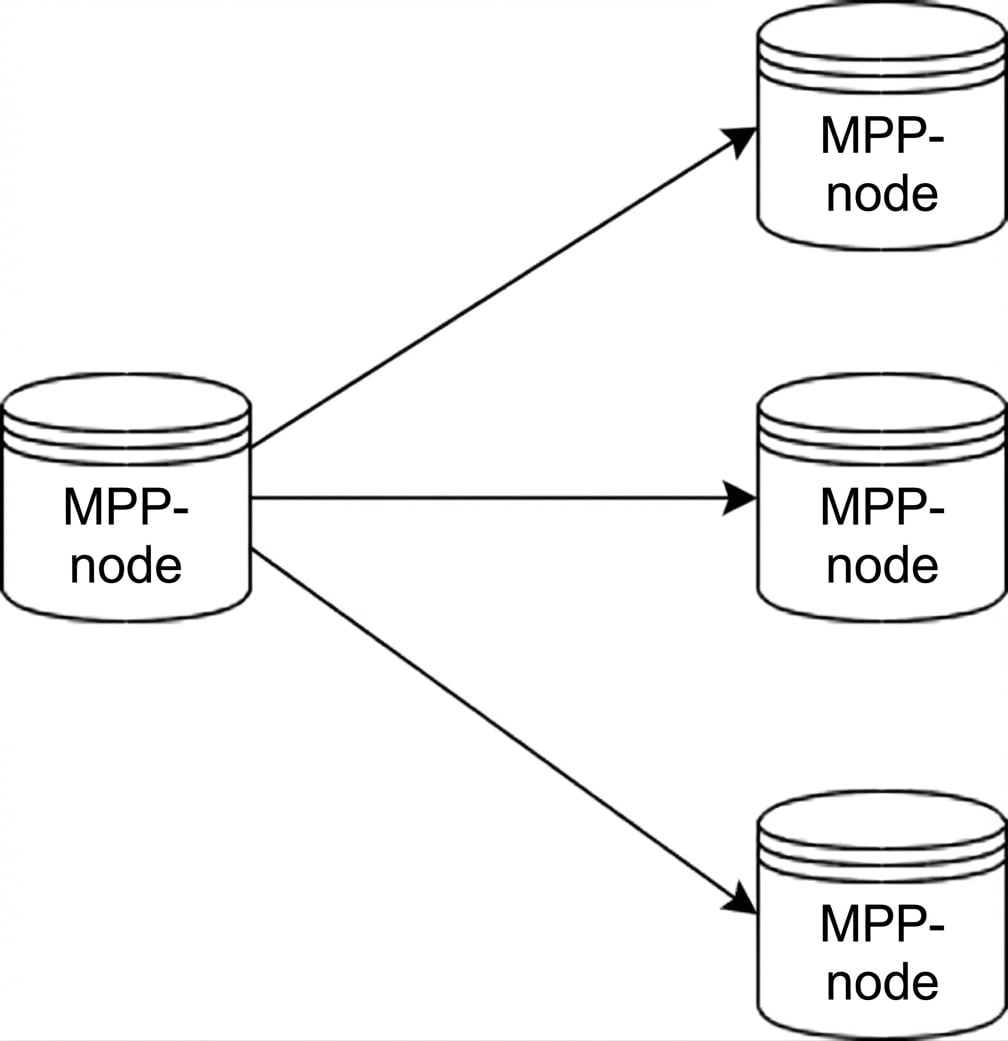
MPP-databases
Massively Parallel Processing-databases