Frameworks voor parallelle verwerking
Introductie tot Data Engineering

Vincent Vankrunkelsven
Data Engineer @ DataCamp
![]()
HDFS
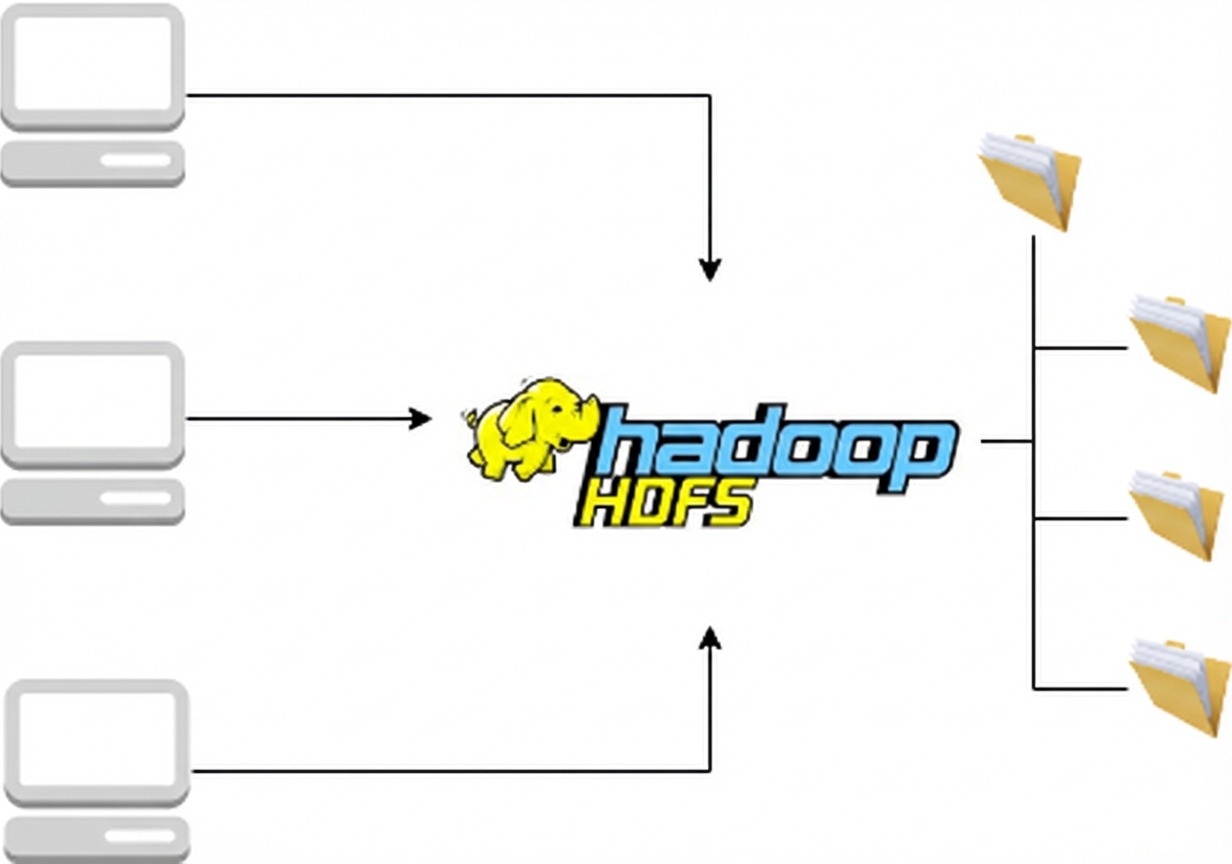
MapReduce
![]()
Hive
- Draait op Hadoop
- Structured Query Language: Hive SQL
- Eerst MapReduce, nu ook andere tools
![]()
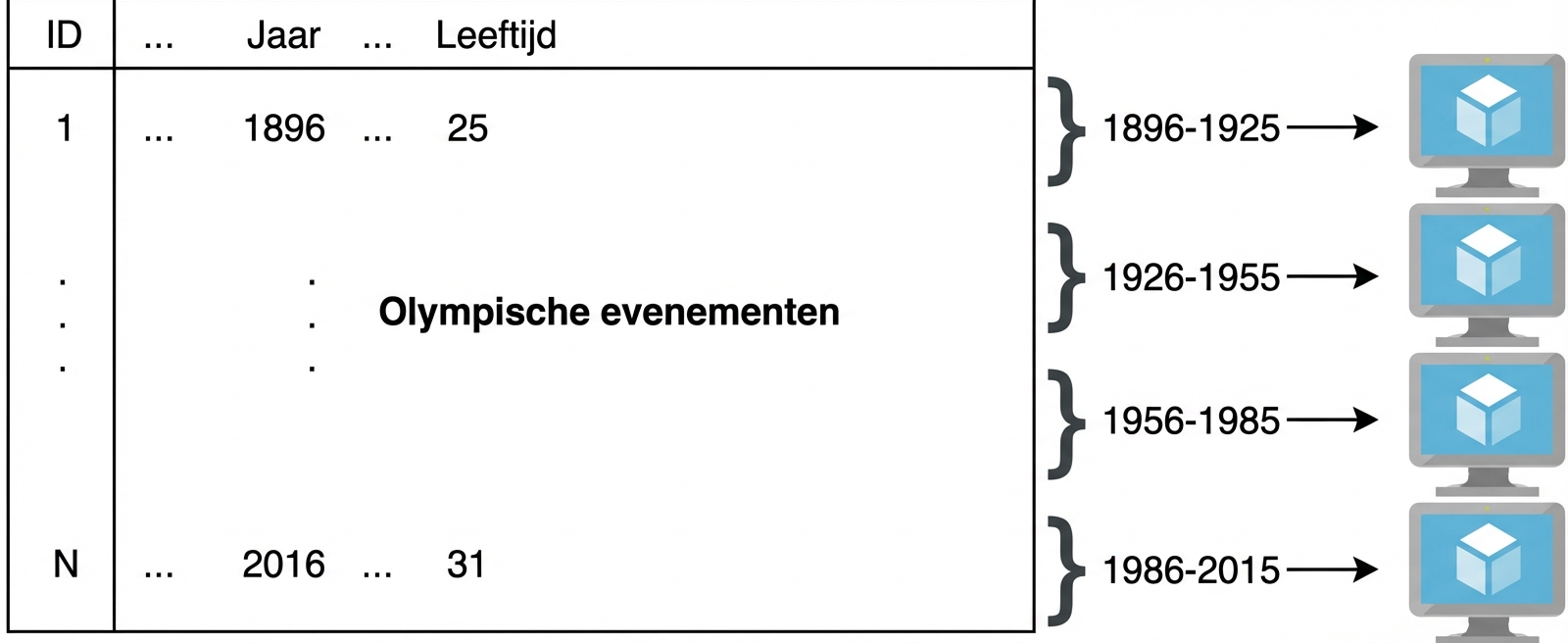
Hive: een voorbeeld

![]()
- Vermijdt schrijfacties naar schijf
- Beheerd door de Apache Software Foundation

