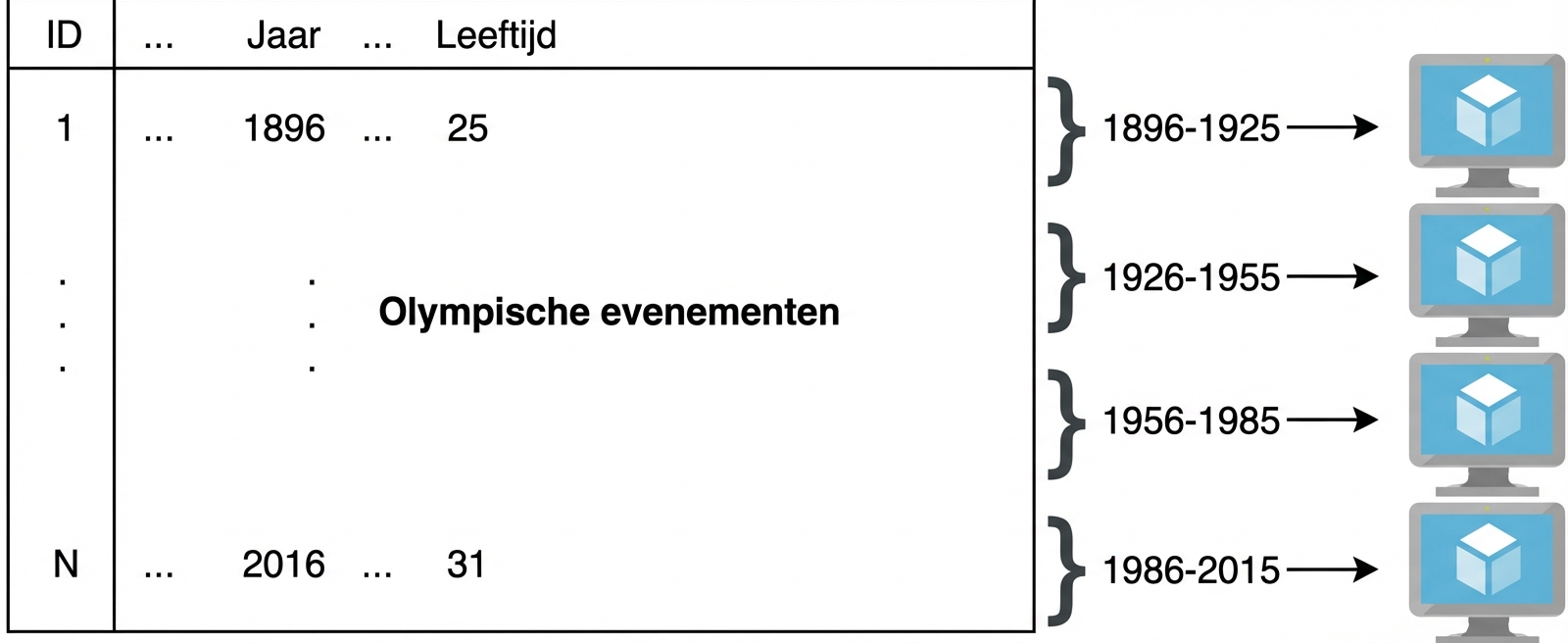
Wat is parallel computing
Introductie tot Data Engineering

Vincent Vankrunkelsven
Data Engineer @ DataCamp
Het idee achter parallel computing
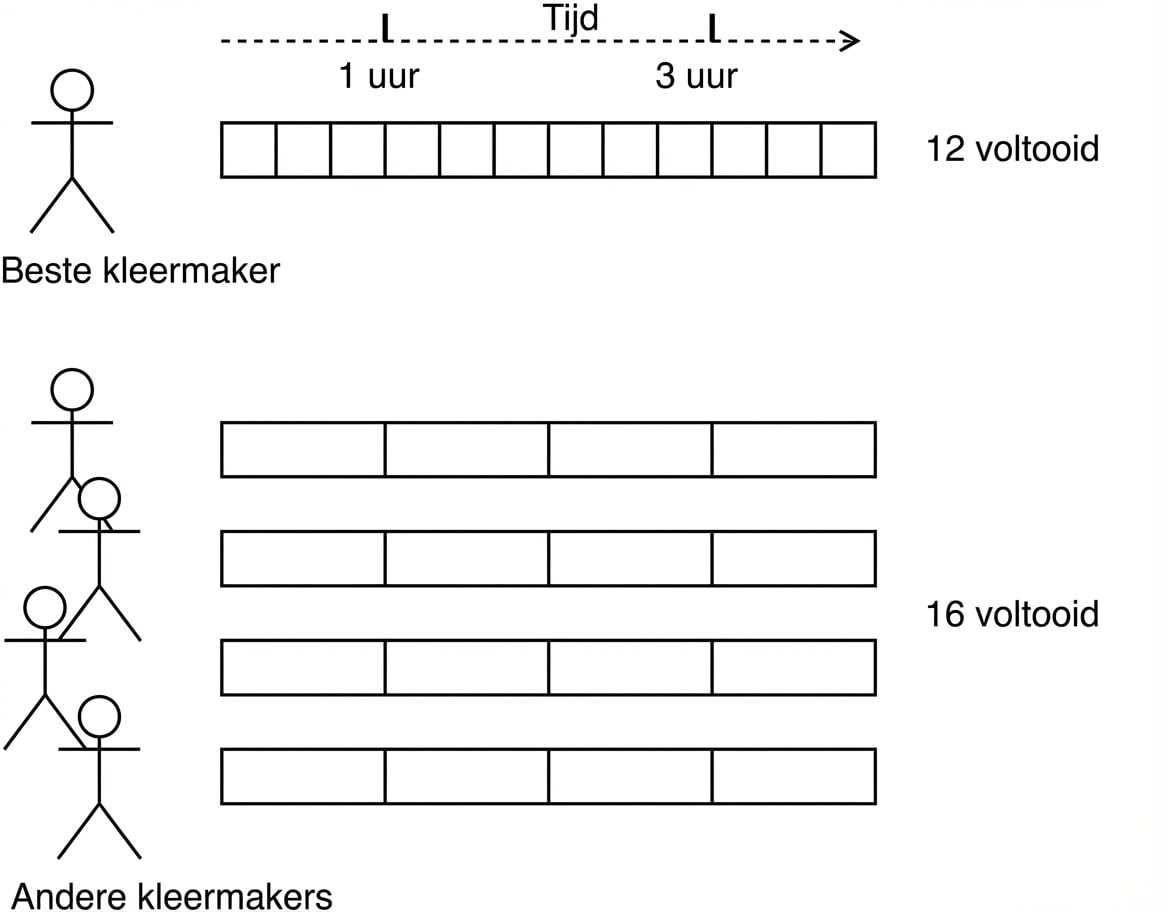
De kleermakerszaak
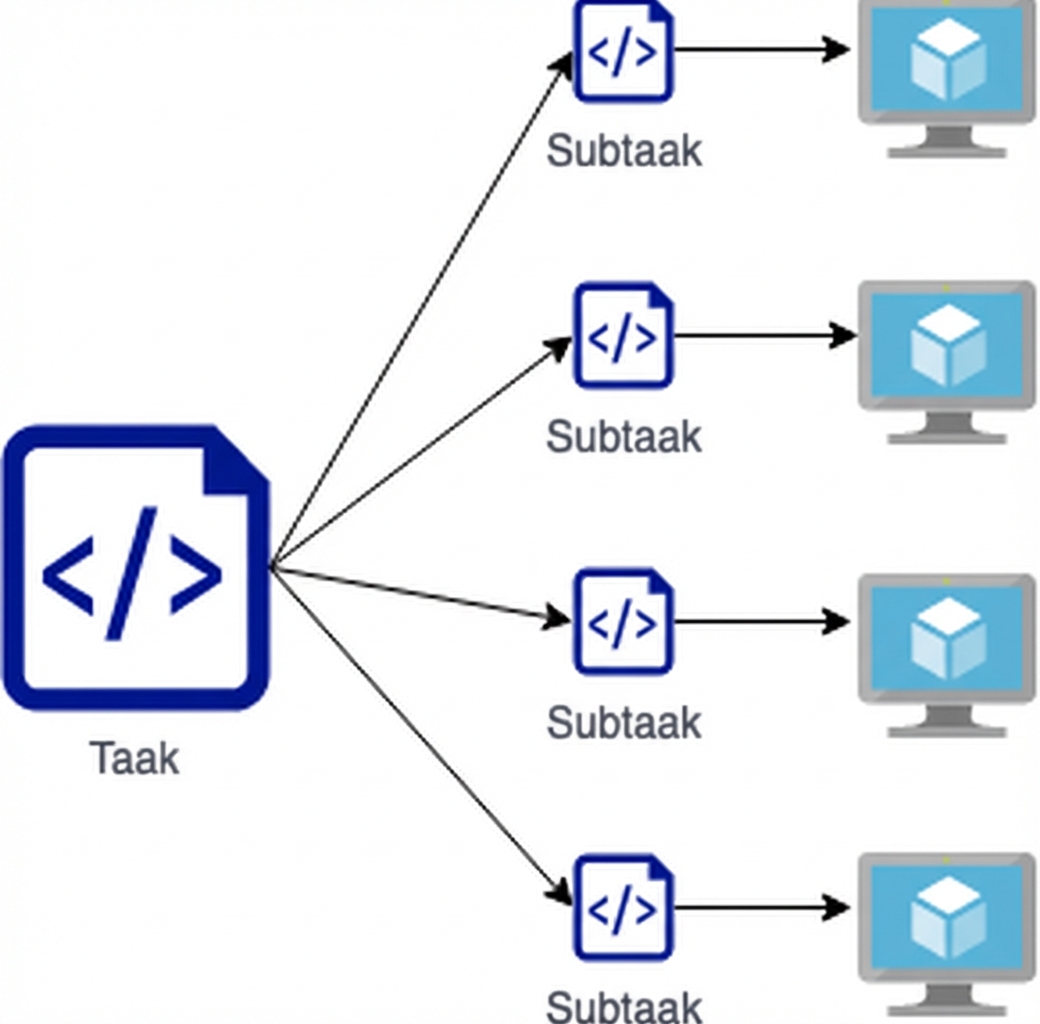
Voordelen van parallel computing
RAM-geheugenchip:

Risico’s van parallel computing
Parallelle vertraging:
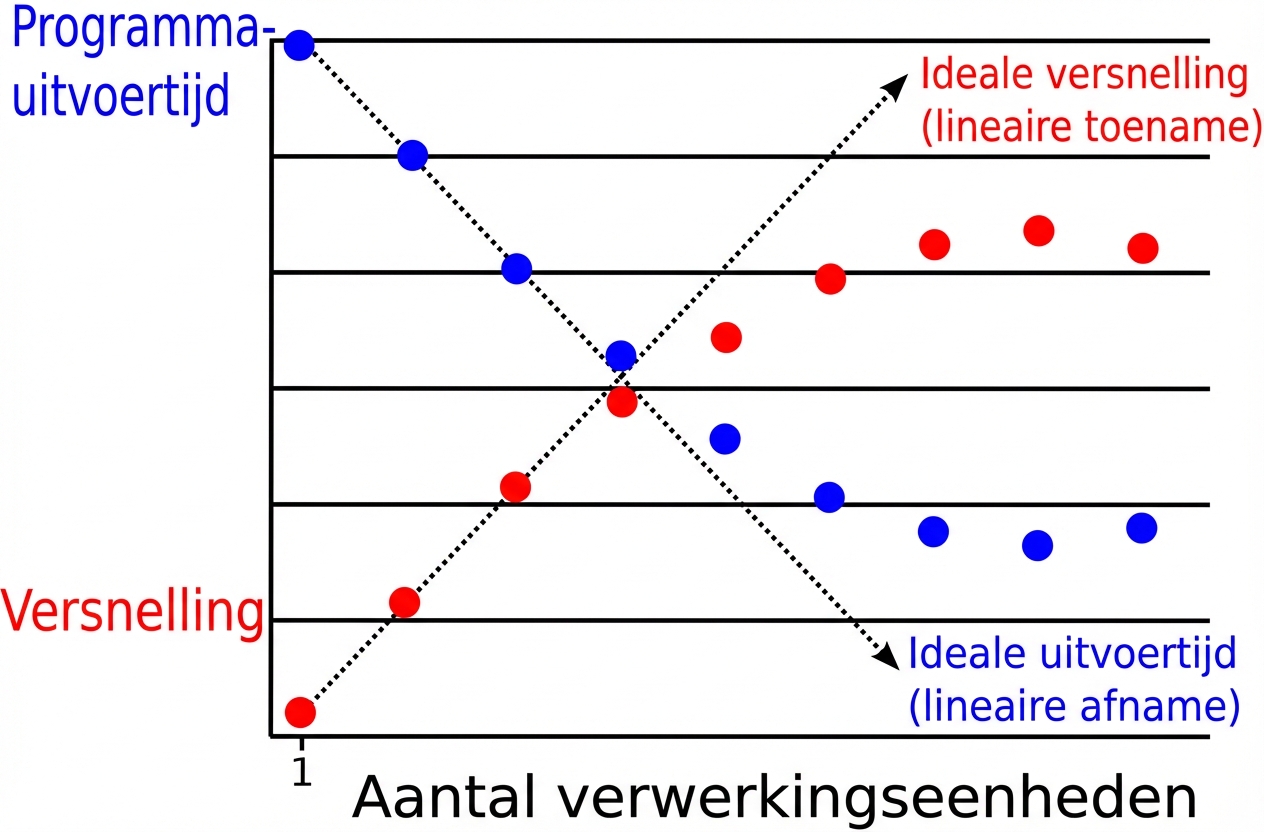
Een voorbeeld