Monte Carlo-methoden
Reinforcement Learning met Gymnasium in Python

Fouad Trad
Machine Learning Engineer
Herhaling: modelgebaseerd leren
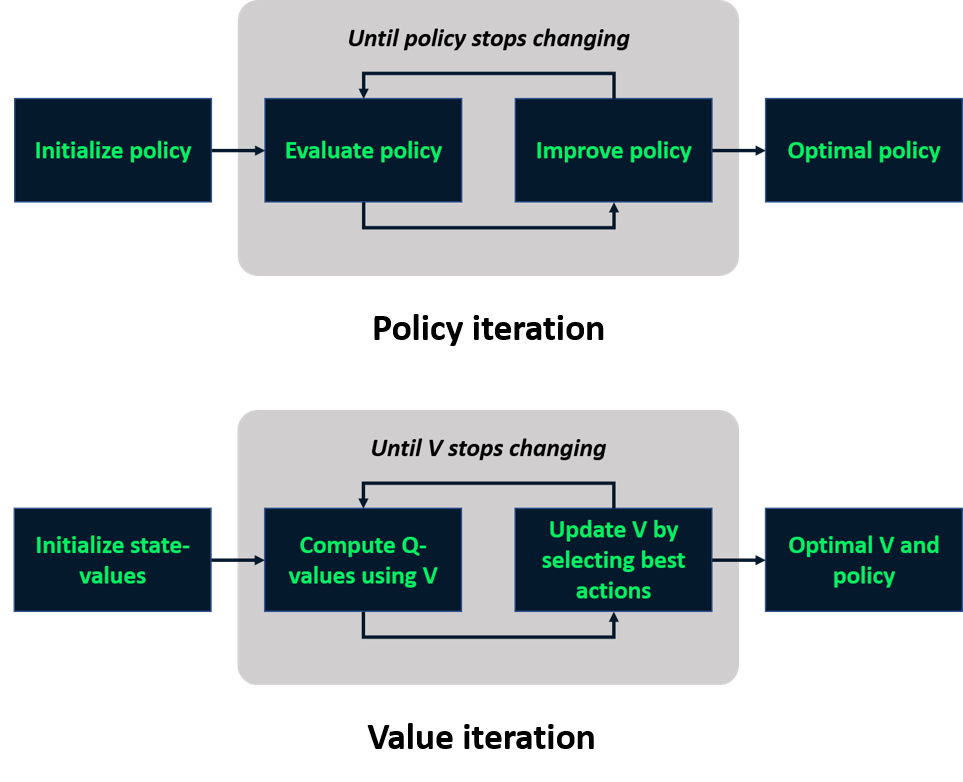
Modelvrij leren

Monte Carlo-methoden
- Modelvrije technieken
- Schat Q-waarden op basis van episodes
Monte Carlo-methoden
- Modelvrije technieken
- Schat Q-waarden op basis van episodes

Monte Carlo-methoden
- Modelvrije technieken
- Schat Q-waarden op basis van episodes

- Twee varianten: first-visit, every-visit
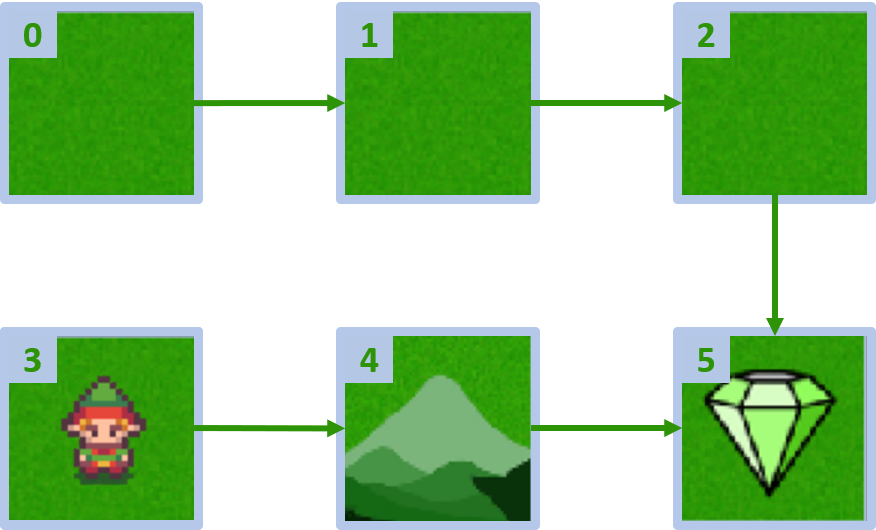
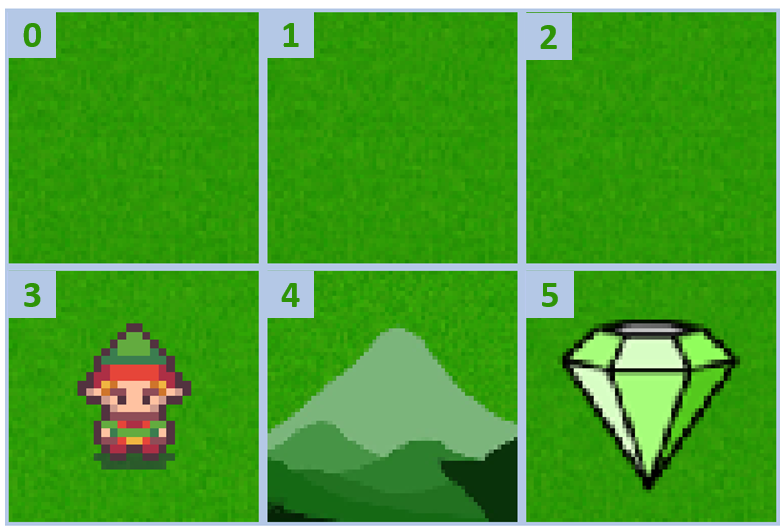
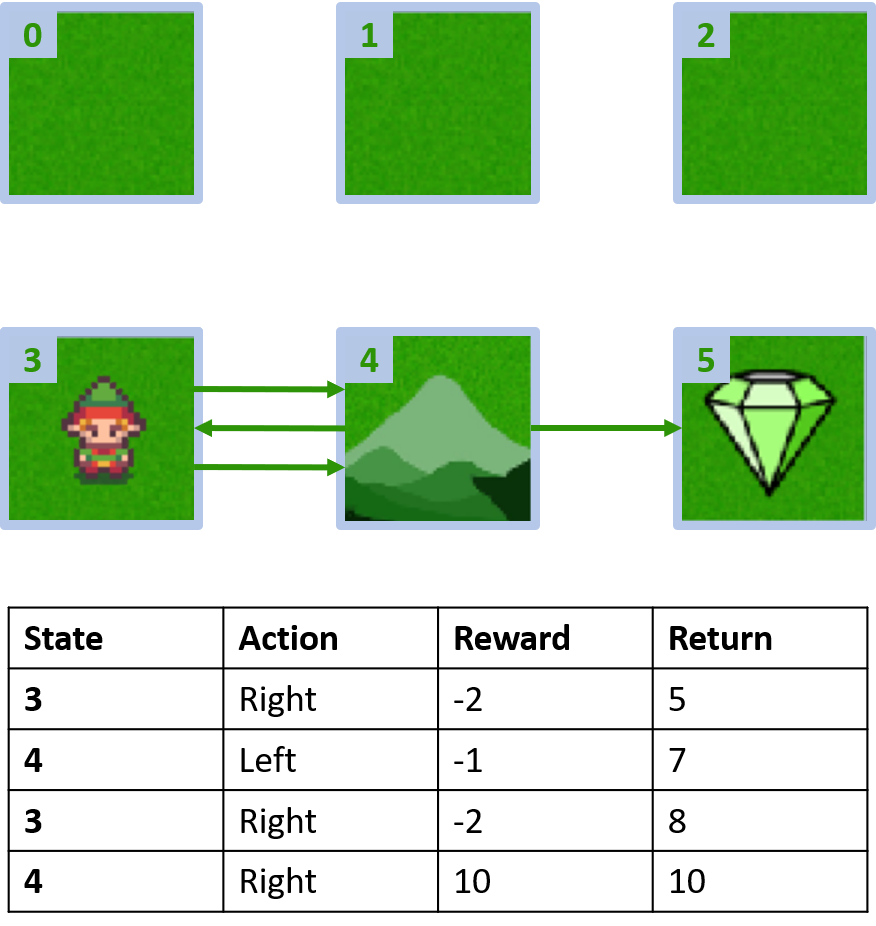
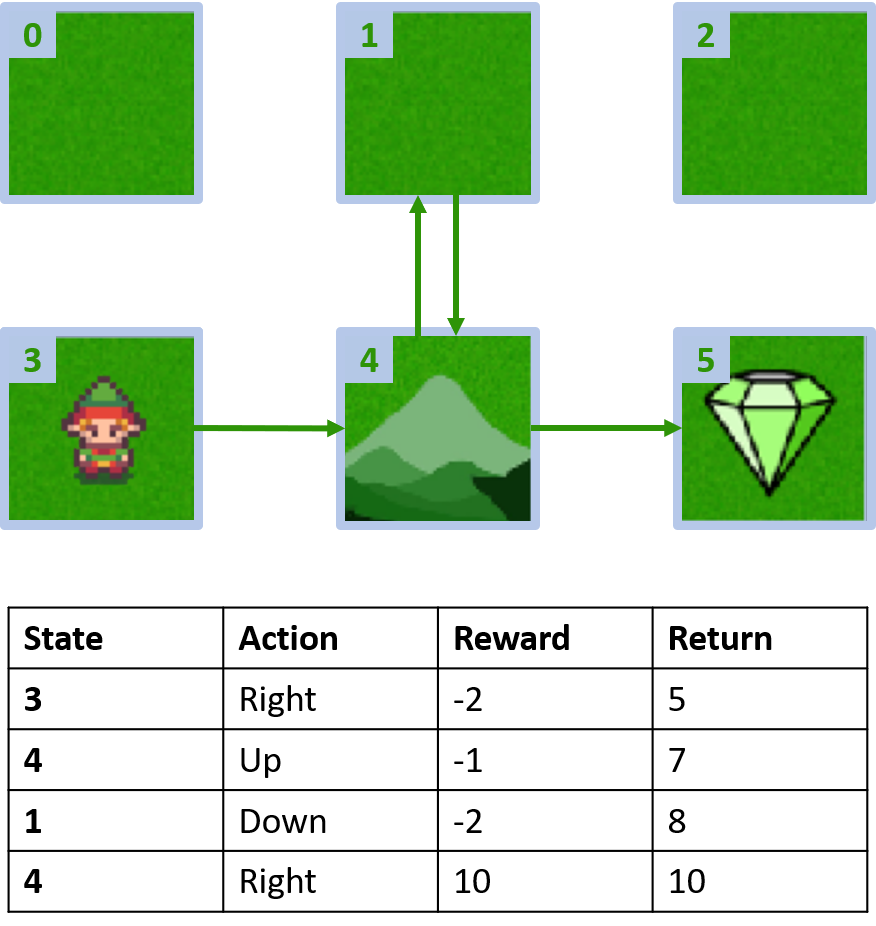
Aangepaste gridworld
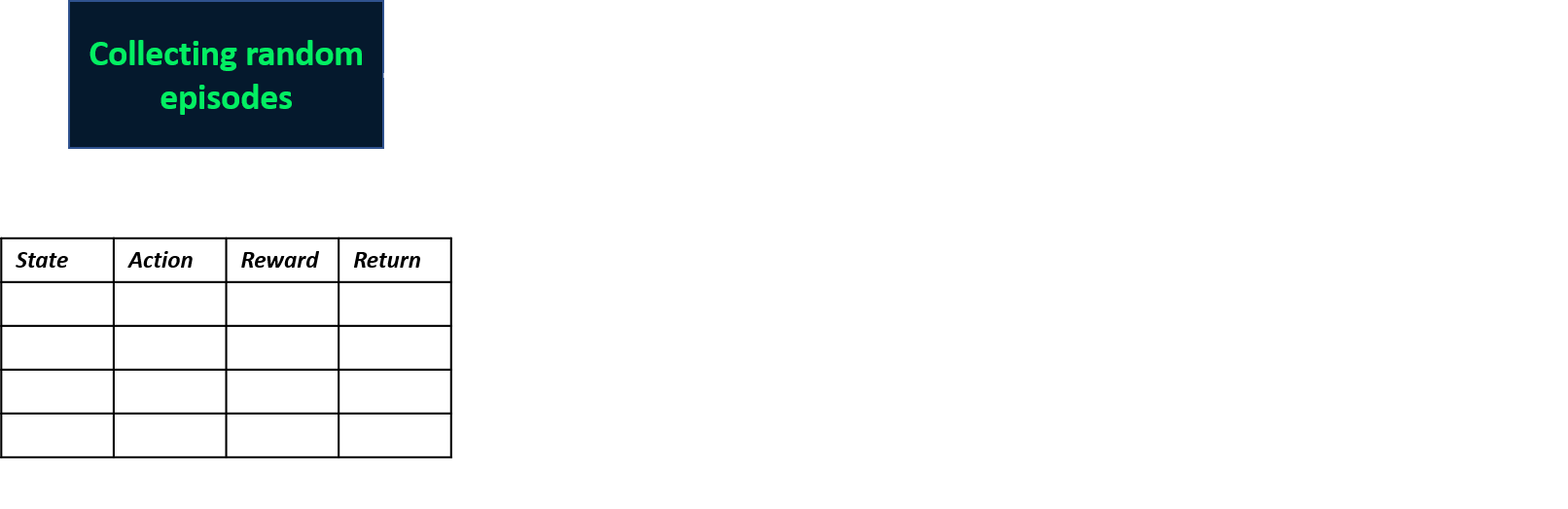
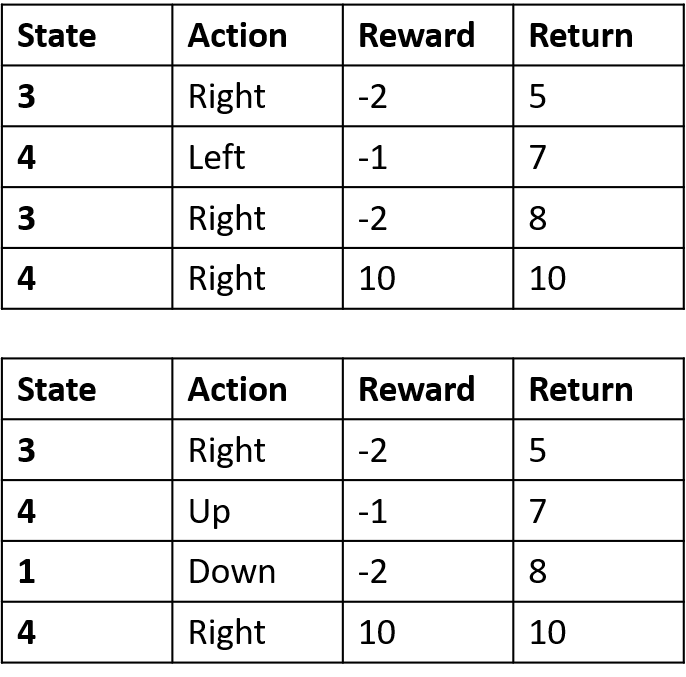
Twee episodes verzamelen
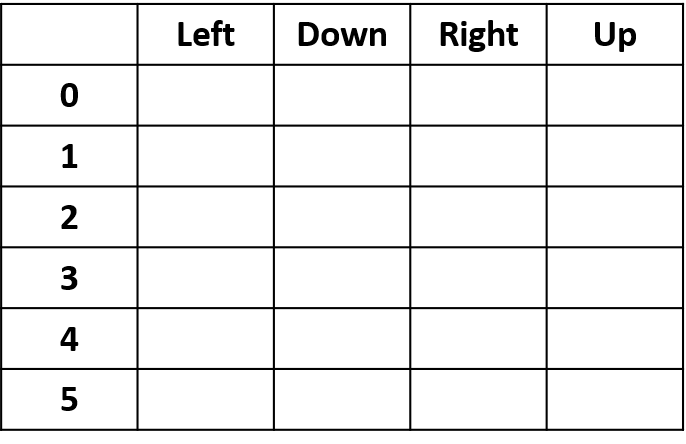
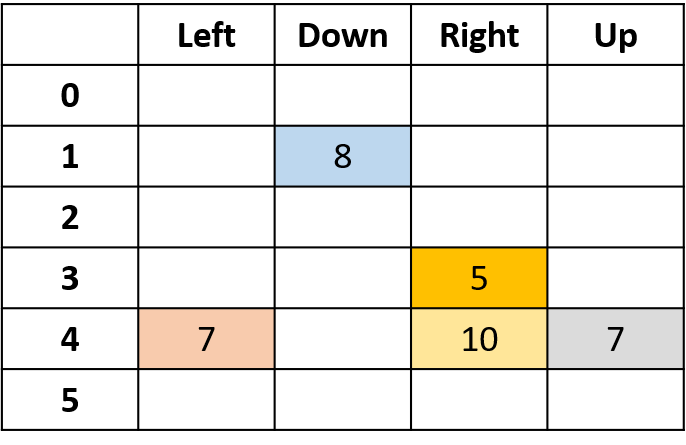
Q-waarden schatten
- Q-tabel: tabel met Q-waarden
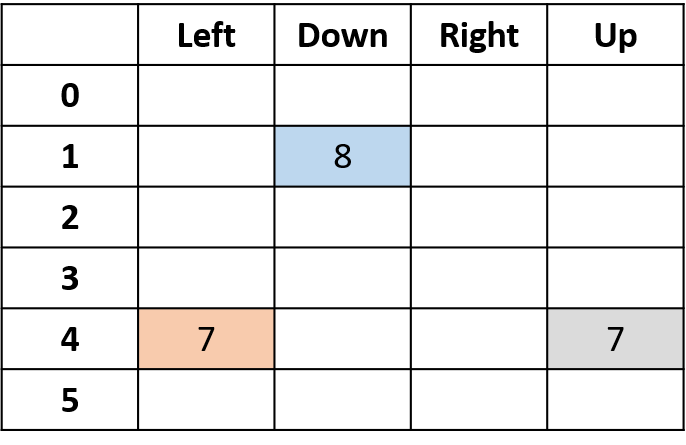
Q(4, left), Q(4, up) en Q(1, down)
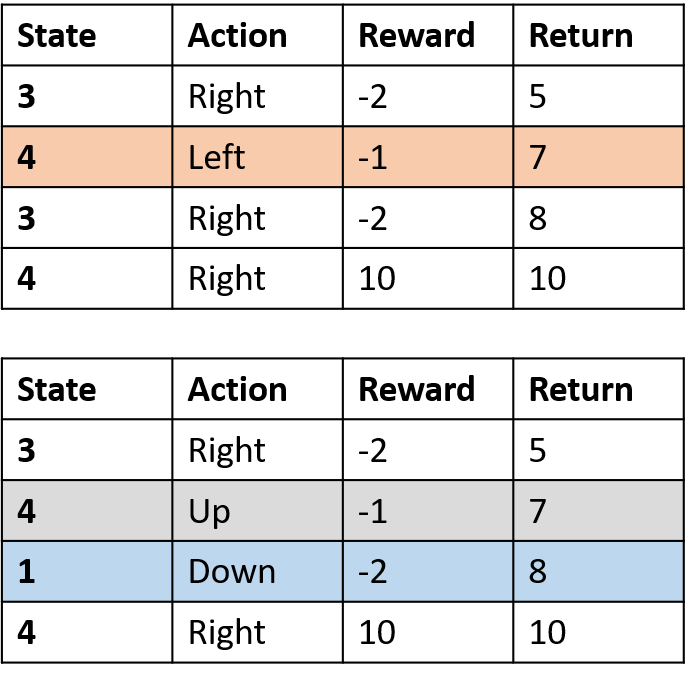
- (s,a) komt één keer voor -> vul in met return
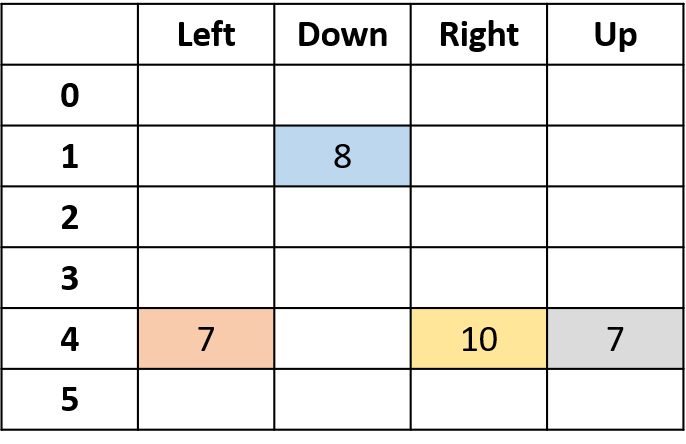
Q(4, right)
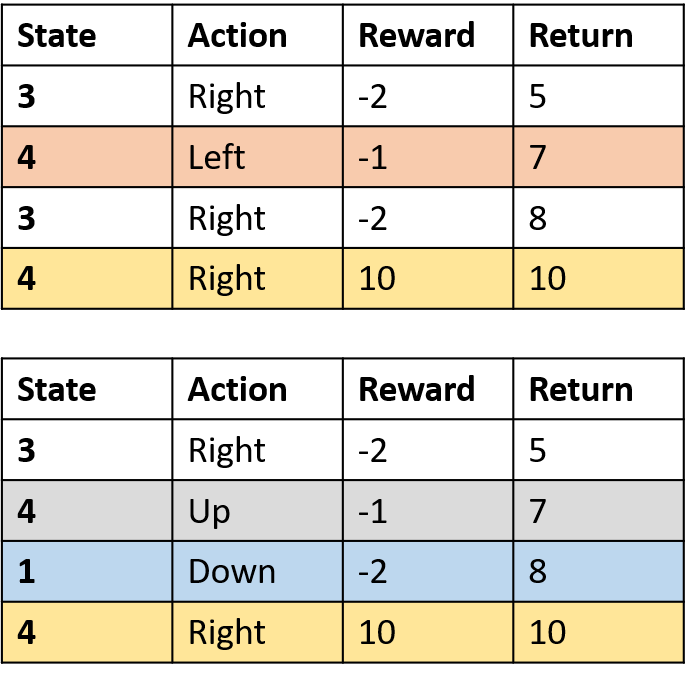
- (s,a) komt per episode één keer voor -> neem het gemiddelde
Q(3, right) - first-visit Monte Carlo
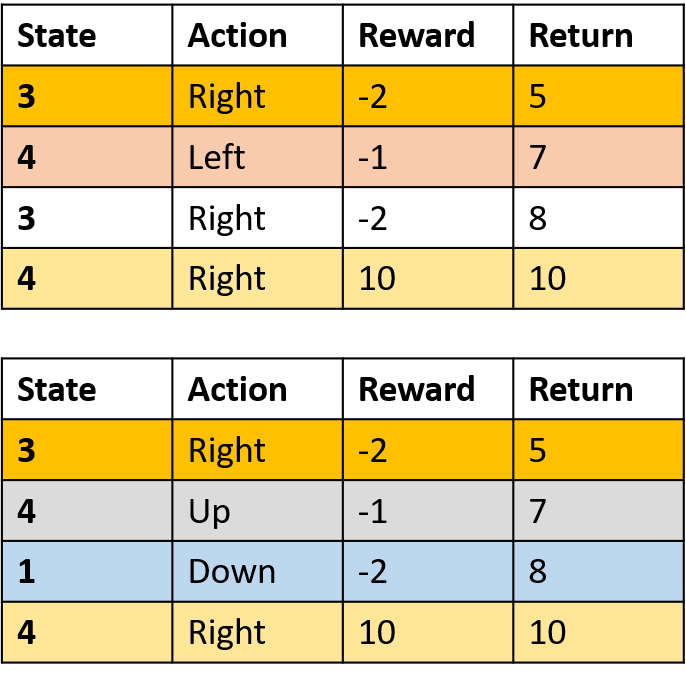
- Neem het gemiddelde van de eerste visit van (s,a) per episode
Q(3, right) - every-visit Monte Carlo
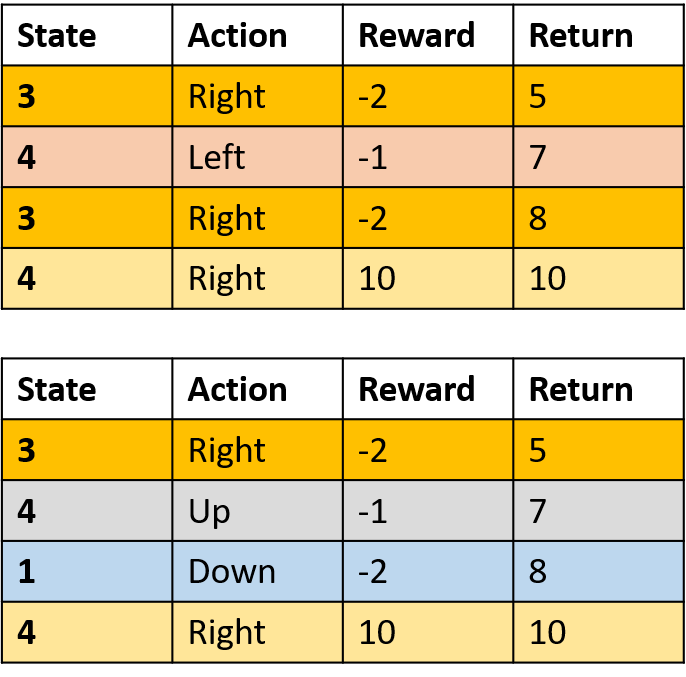
- Neem het gemiddelde over elke visit van (s,a) per episode
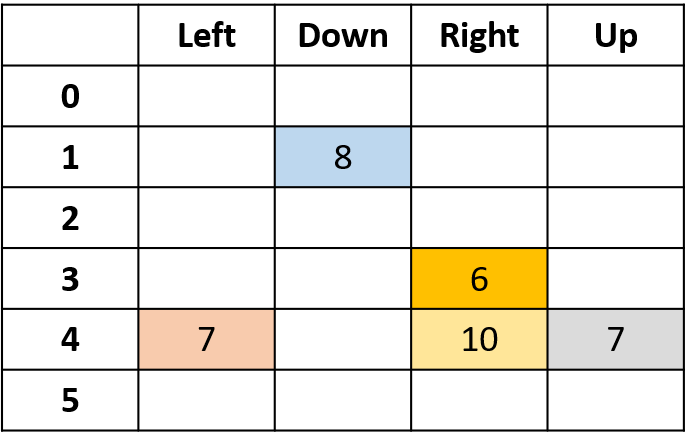
Alles samenvoegen