Balans tussen exploratie en exploitatie
Reinforcement Learning met Gymnasium in Python

Fouad Trad
Machine Learning Engineer
Trainnen met willekeurige acties

Exploratie-exploitatie-afweging

Eetkeuzes

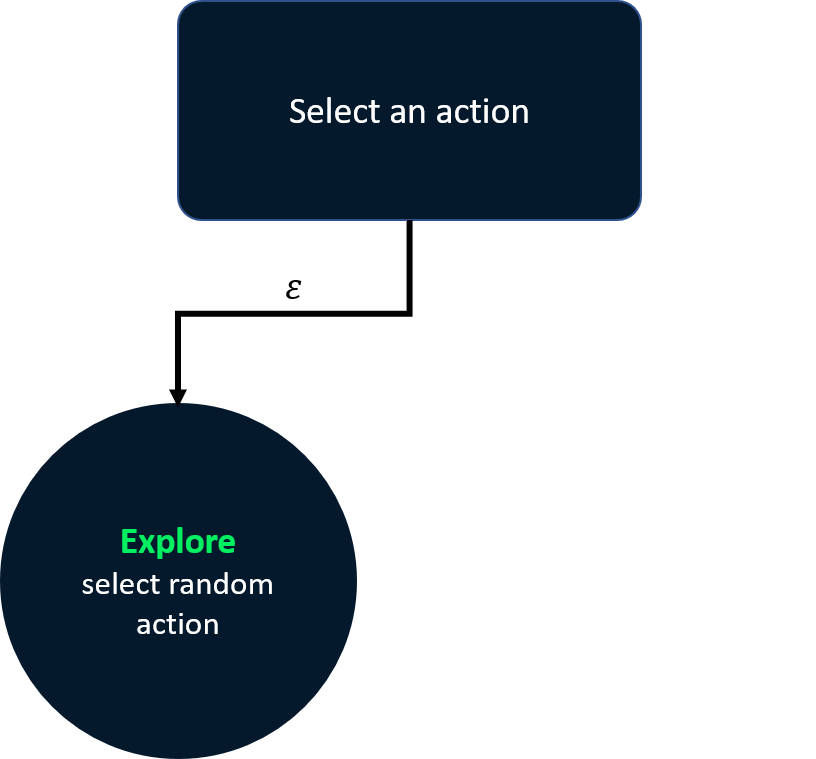
Epsilon-greedy strategie
Epsilon-greedy strategie
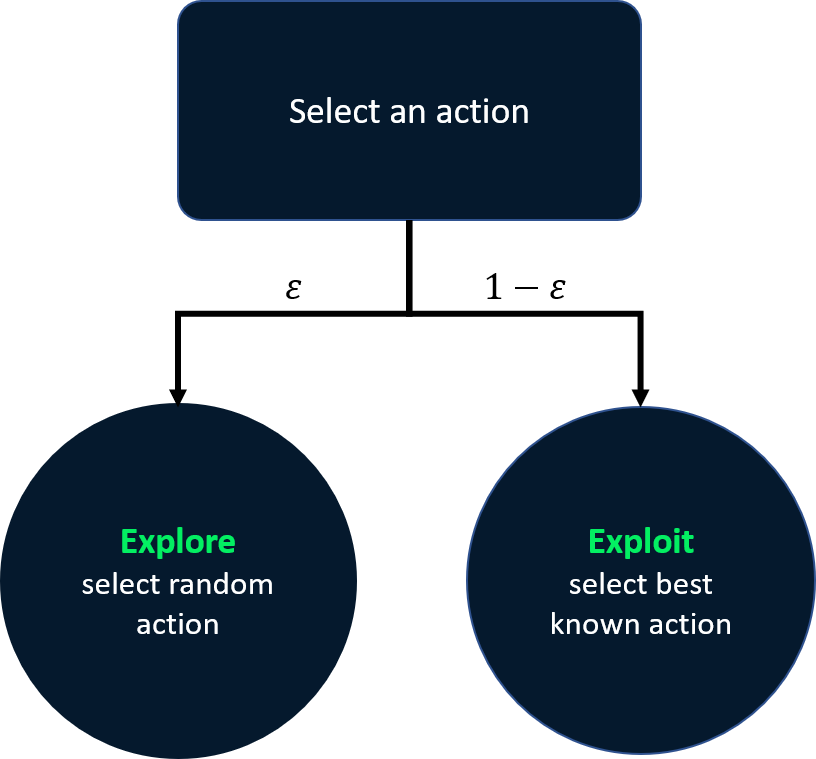
Epsilon-greedy met afname

Implementatie met Frozen Lake

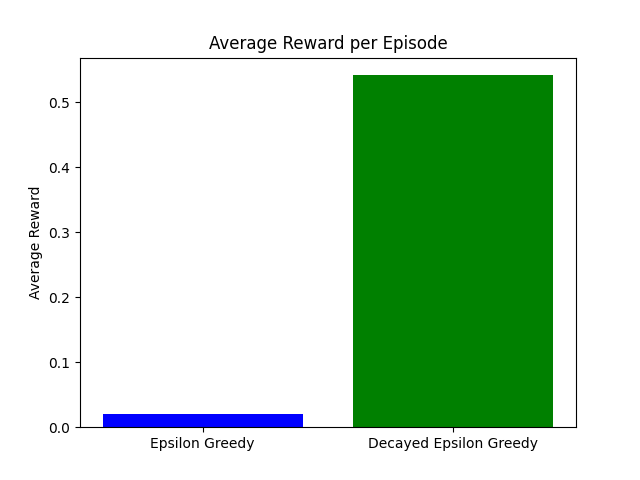
Strategieën vergelijken